本ページは、VR(バーチャルリアリティ/Virtual Reality )、AR(オーグメンテッドリアリティ/拡張現実/Augmented Reality)、プロジェクションマッピング、3DCGに関する論文を厳選し、時系列順に随時更新、一覧にしている場所です。
また、本ページのようにアーカイブベースではなく、速報ベースで取得したい方は、月1回の配信で最新論文を紹介するWebコンテンツもあります。
初めての方はこちら。
索引
最初に、索引として「A~Z」順に並べています。 索引を飛ばす場合はこちら。
A
- AffectiveHMD:組み込み型センサを用いた表情認識とバーチャルアバターへの表情マッピング
- Air Mounted Eyepiece: Design Methods for Aerial Optical Functions of Near-Eye and See-Through Display using Transmissive Mirror Device
- Angle-Multiplexed Metasurfaces: Encoding Independent Wavefronts in a Single Metasurface under Different Illumination Angles
- Articulated distance fields for ultra-fast tracking of hands interacting
- Audible Panorama: Automatic Spatial Audio Generation for Panorama Imagery
- Augmented Reality Powers a Cognitive Prosthesis for the Blind
- A Wide-Field-of-View Monocentric Light Field Camera
B
- Baxter’s Homunculus: Virtual Reality Spaces for Teleoperation in Manufacturing
- Behind The Palm: Hand Gesture Recognition through Measuring Skin Deformation on Back of Hand by using Optical Sensors
C
- Cardiolens: Remote Physiological Monitoring in a Mixed Reality Environment
- CAVE-based Visualization Methods of Public VR Towards Shareable VR Experience
- ChromaBlur: Rendering Chromatic Eye Aberration Improves Accommodation and Realism
- ChromaGlasses: Computational Glasses for CompensatingColour Blindness
- CompoundDome: スクリーンを部分的に透過することにより現実世界とインタラクションを可能にする装着型ドーム装置
- Context-Aware Online Adaptation of Mixed Reality Interfaces
D
- Deep Blending for Free-Viewpoint Image-Based Rendering
- Deep Fluids: A Generative Network for Parameterized Fluid Simulations
- Deep Volumetric Video From Very Sparse Multi-View Performance Capture
- Designing AR Visualizations to Facilitate Stair Navigation for People with Low Vision
- Design and prototype of an augmented reality display with per-pixel mutual occlusion capability
- Distortion-Free Wide-Angle Portraits on Camera Phones
- DreamWalker: Substituting Real-World Walking Experiences with a Virtual Reality
E
- EgoFace: Egocentric Face Performance Capture and Videorealistic Reenactment
- Embodied Hands: Modeling and Capturing Hands and Bodies Together
- Enchanting Your Noodles: GAN-based Real-time Food-to-Food Translation and Its Impact on Vision-induced Gustatory Manipulation
- Extending AR Interaction through 3D Printed Tangible Interfaces in an Urban Planning Context
- EyeHacker: Gaze-Based Automatic Reality Manipulation
- Eyemotion: Classifying facial expressions in VR using eye-tracking cameras
F
- FaceDrive: Facial Expressions Commands to Control Virtual Supernumerary Robotic Arms
- FaceVR: Real-Time Facial Reenactment and Eye Gaze Control in Virtual Reality
- FaceWidgets: Exploring Tangible Interaction on Face with Head-Mounted Displays
- fARFEEL: Providing Haptic Sensation of Touched Objects using Visuo-Haptic Feedback
- Fast Gaze-Contingent Optimal Decompositions for Multifocal Displays
- FibAR: Embedding Optical Fibers in 3D Printed Objects for Active Markers in Dynamic Projection Mapping
- Focal surface displays
- Functional Workspace Optimization via Learning Personal Preferences from Virtual Experiences
G
- GANerated Hands for Real-Time 3D Hand Tracking from Monocular RGB
- Generating Digital Painting Lighting Effects via RGB-space Geometry
- GestARLite: An On-Device Pointing Finger Based Gestural Interface for Smartphones and Video See-Through Head-Mounts
H
I
- IlluminatedFocus: Vision Augmentation using Spatial Defocusing via Focal Sweep Eyeglasses and High-Speed Projector
- Instant 3D Photography
- In the Blink of an Eye –Leveraging Blink-Induced Suppression for Imperceptible Position and Orientation Redirection in Virtual Reality
J
K
L
- Laplacian Vision: Augmenting Motion Prediction via Optical See-Through Head-Mounted Displays
- LayoutNet: Reconstructing the 3D Room Layout from a Single RGB Image
- Learn2Smile: Learning Non-Verbal Interaction Through Observation
- Live Coding of a VR Render Engine in VR
- Lost in Style:Gaze-driven Adaptive Aid for VR Navigation
- Luminance-Contrast-Aware Foveated Rendering
M
- Magic Bench — A Multi-User & Multi-Sensory AR/MR Platform
- Make your own Retinal Projector: Retinal Near-Eye Displays via Metamaterials
- MeCap: Whole-Body Digitization for Low-Cost VR/AR Headsets
- Mixing Yarns and Triangles in Cloth Simulation
- Mutual Human Actuation
N
- NaviFields: Relevance fields for adaptive VR navigation
- Neural Re-Simulation for Generating Bounces in Single Images
O
- Occlusion-aware Hand Posture Based Interaction on Tabletop Projector
- Occlusion Leak Compensation for Optical See-Through Displays using a Single-layer Transmissive Spatial Light Modulator
- Object-wise 3D Gaze Mapping in Physical Workspace
P
- paGAN: Real-time Avatars Using Dynamic Textures
- Perceptually-Guided Foveation for Light Field Displays
- PinpointFly: An Egocentric Position-pointing Drone Interface using Mobile AR
- Polyvision: 4D Space Manipulation through Multiple Projections
- Portal-ble: Intuitive Free-hand Manipulation in Unbounded Smartphone-based Augmented Reality
- PortOn: Portable mid-air imaging optical system on glossy materials
Q
R
- Realistic AR Makeup over Diverse Skin Tones on Mobile
- ReallifeEngine: A Mixed Reality-Based Visual Programming System for SmartHomes
- Real-time Measurement and Display System of 3D Sound Intensity Map using Optical See-Through Head Mounted Display
- Real-time Pose and Shape Reconstruction of Two Interacting Hands With a Single Depth Camera
- Recycling a Landmark Dataset for Real-time Facial Capture and Animation with Low Cost HMD Integrated Cameras
- Remixed Reality: Manipulating Space and Time in Augmented Reality
- RoMA: Interactive Fabrication with Augmented Reality and a Robotic 3D Printer
S
- Saccade Landing Position Prediction for Gaze-Contingent Rendering
- Scene-Aware Audio for 360° Videos
- Scenograph: Fitting Real-Walking VR Experiences into Various Tracking Volumes
- Smooth Assembled Mappings for Large-Scale Real Walking
- Special-purpose computer HORN-8 for phase-type electro-holography
- SpinVR: Towards Live-streaming 3D VR Video
- Supporting Responsive Cohabitation Between Virtual Interfaces and Physical Objects on Everyday Surfaces
- SurfaceBrush: From Virtual Reality Drawings to Manifold Surfaces
- SoftSMPL: Data-driven Modeling of Nonlinear Soft-tissue Dynamics for Parametric Humans
- SymbiosisSketch: Combining 2D & 3D Sketching for Designing Detailed 3D Objects in Situ
- Synergetic Reconstruction from 2D Pose and 3D Motion for Wide-Space Multi-Person Video Motion Capture in the Wild
T
- Total Capture: A 3D Deformation Model for Tracking Faces, Hands, and Bodies
- Towards Multifocal Displays with Dense Focal Stacks
- Transparent Mask: Face-Capturing Head-Mounted Display with IR Pass Filters
U
V
- Virtual Agent Positioning Driven by Scene Semantics in Mixed Reality
- Verifocal: a Platform for Vision Correction and Accommodation in Head-Mounted Displays
- Video Based Reconstruction of 3D People Models
- Video Motion Capture from the Part Confidence Maps of Multi-Camera Images by Spatiotemporal Filtering Using the Human Skeletal Model
- VR Facial Animation via Multiview Image Translation
W
X
Y
Z
VR/ARの最新研究一覧

Generating Digital Painting Lighting Effects via RGB-space Geometry
デジタル絵画内の照明を後から自動挿入する技術。ストローク密度が高い所に陰影もより集まると仮定し照明効果を推定するアルゴリズム。光の当たる方向も多様に変更可。写真や3D画像でも可。動画
FibAR: Embedding Optical Fibers in 3D Printed Objects for Active Markers in Dynamic Projection Mapping
3Dプリントした物体の動きを追跡してプロジェクションマッピングする研究。物体内に埋め込んだ複数本の光ファイバーから発せられる赤外光を赤外線カメラで観測し姿勢位置を決定。距離が遠くても追跡しぴったり張り付いているように投影す。動画

3D Photography using Context-aware Layered Depth Inpainting
1枚のRGB-D画像から3次元画像を生成する学習ベースの手法。入力画像から隠蔽(オクルージョン)された部分の色と深度のテクスチャを作成し合成する。Facebook 3D Photos等の類似技術より高品質。
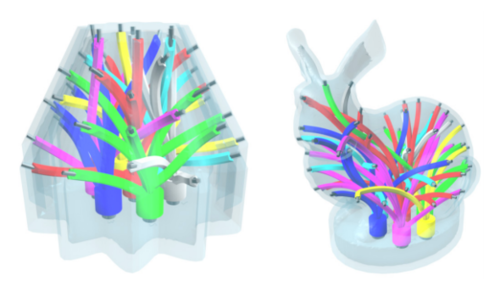
Mixing Yarns and Triangles in Cloth Simulation
布の動きをより現実的に再現する研究 。同じ布地上で三角形モデルと糸モデル(重要な領域のみ)を組み合わせて、衣服や旗などのクロスシミュレーションを細部(しわ,ひだ等)までよりリアルに再現する。 動画

SoftSMPL: Data-driven Modeling of Nonlinear Soft-tissue Dynamics for Parametric Humans
人の動きによる脂肪等の揺れを現実的に再現する研究。人間における軟部組織の変形をシミュレートするニューラルネットワークを用いた手法。体の形状をパラメーター化し、インタラクティブに操作(軟部組織の増減、動きの選択)もできる。動画

PortOn: Portable mid-air imaging optical system on glossy materials
机や床など光沢ある平面上に置くと裸眼視可能な垂直空中像を表示できるディスプレイの研究。フローリングや大理石、ガラスへの表示も可能。光沢面への反射は除去し空中像自体を際立たせる。本体は箱型で持ち運べる。動画

IlluminatedFocus: Vision Augmentation using Spatial Defocusing via Focal Sweep Eyeglasses and High-Speed Projector
その空間だけボケさせる隠消現実メガネの研究。目からの距離に関係なく特定の空間のみぼかす。可変焦点レンズとプロジェクタを使用。例:せたくない物だけを追跡しぼかす。机上の教科書だけシャープに漫画本はぼかす。2D画像内で背景だけぼかす等。動画
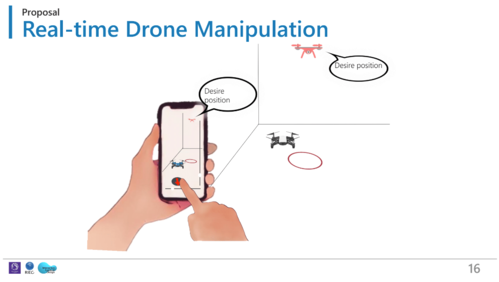
PinpointFly: An Egocentric Position-pointing Drone Interface using Mobile AR
ARでドローンを操作できる「PinpointFly」の研究。モバイル端末で移動先へドラッグするのみ、高さは横のスライドバーで調整。左右高さ奥行きの3次元で位置決め。初心者も精密に操作できる。移動先までの飛行経路もなぞって指定可能。マーカー設置できれば野外でも使用可能 。動画
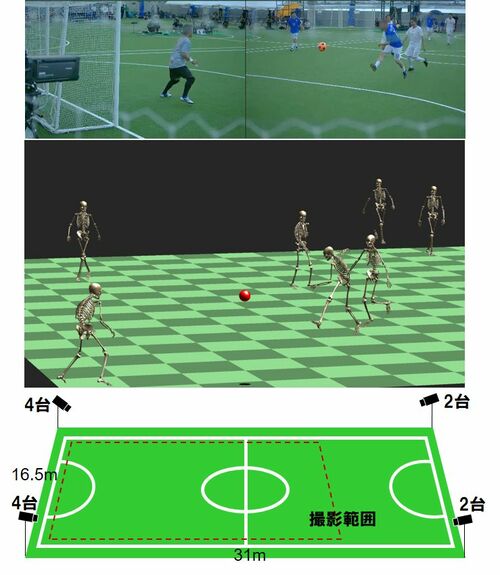
Synergetic Reconstruction from 2D Pose and 3D Motion for Wide-Space Multi-Person Video Motion Capture in the Wild
カメラ映像のみから複数人の動きを全身モーションキャプチャする研究。特殊装置やマーカー付スーツなし、服装も問わず広空間の多人数全身運動を同時にキャプチャ。激しい動き、人同士の重なり問題なし。ロボティクスで力筋も計算。カメラのみでスポーツやライブに活用。動画

Polyvision: 4D Space Manipulation through Multiple Projections
VR内において、4次元(4D) の感覚を体験できる高次元データと数学オブジェクトの探索を提案する研究。動画

Context-Aware Online Adaptation of Mixed Reality Interfaces
Mixed Realityインタフェースにおいて、目の前に表示されるアプリケーションも表示するタイミングと場所、および表示する情報量を自動的に制御する研究。動画

FaceWidgets: Exploring Tangible Interaction on Face with Head-Mounted Displays
ヘッドマウントディスプレイ(HMD)の背面に統合されたデバイスで、物理的なコントローラーを使用したインタラクションを可能にする研究。物理的なコントローラーには、ボタンやジョイスティック、回転するボタンなどが搭載する。動画

Designing AR Visualizations to Facilitate Stair Navigation for People with Low Vision
低視力者向けにAR階段ナビゲーションを提案する研究。投影する方式と光学シースルーHMDを用いた方式で提示する。上り下りする階段のエッジ部分を光らせたり、ユーザーの階段上での位置確認のための表示など。動画
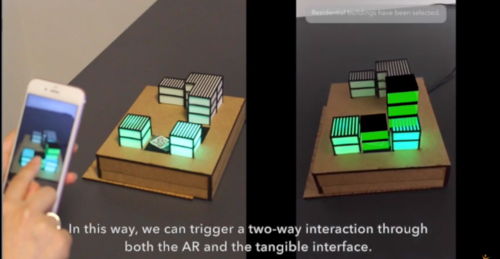
Extending AR Interaction through 3D Printed Tangible Interfaces in an Urban Planning Context
ARコンテンツおよび物理コンテンツとのインタラクションを提案する研究。デモ動画では、都市計画をコンテキストに、3Dプリンタで印刷した建物の一部をベースに、モバイルARインタフェースで拡張する様子を確認できる。動画

Portal-ble: Intuitive Free-hand Manipulation in Unbounded Smartphone-based Augmented Reality
スマートフォンの裏にハンドトラッカーを取付けARコンテンツを掴めるようにしたシステムを提案する研究。スマートフォンを移動させながらモニターを越えAR物体を掴める。AR物体に遠い距離、近いが手に届かない距離、手に届く距離、触れた状態、掴んだ状態を視覚、聴覚、触覚で区別し提示するUX。動画
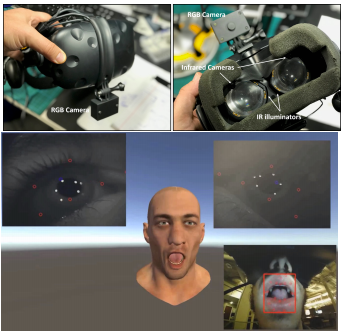
Recycling a Landmark Dataset for Real-time Facial Capture and Animation with Low Cost HMD Integrated Cameras
VR HMD内の顔の表情をトラッキングし、同じ動きをアバターで駆動させる手法を提案する研究。口の動き、視線の追跡、まばたきの動きをリアルタイム検出 。動画

FaceDrive: Facial Expressions Commands to Control Virtual Supernumerary Robotic Arms
顔の表情からロボットアームを制御するシステムを提案する研究。 4つのコマンド(アームを伸ばす、縮める、掴む、離す)に対応した任意の表情を機械学習することでロボットアームの操作を可能 にする。動画

ReallifeEngine: A Mixed Reality-Based Visual Programming System for SmartHomes
MR(複合現実)を活用してIoTの操作をビジュアルプログラミングできるシステム「ReallifeEngine」を提案する研究。動画では、人感センサーと電気スタンドのオンに繋ぎ、オフを物理スイッチに繋いでいる。またその間に5秒待つという指示や、圧力センサーの値が3を上回るとオンになる指示を組み込んだり。動画

MeCap: Whole-Body Digitization for Low-Cost VR/AR Headsets
スマートフォン用VRヘッドセットに鏡面半球ミラーを装着し自分の全身(手や口、衣服含む)をモーションキャプチャする手法を提案する研究。使用者の3D身体ポーズ、手や指のポーズ、顔の表情(口の状態を検出)、身体的外観(肌と衣服の検出)、および周囲環境のリアルタイム推定をする。動画

DreamWalker: Substituting Real-World Walking Experiences with a Virtual Reality
現実の町とバーチャルの町をリンクさせてVR内で物理歩行できるナビゲーションシステムを提案する研究。ユーザが実際に歩いている現実世界の屋外スペースを介してVR体験でナビゲートできるシステム。 つまり、現実空間を見なくても目的地に着けるということ。動画
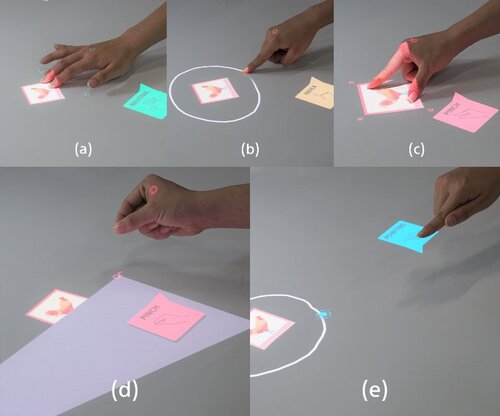
Occlusion-aware Hand Posture Based Interaction on Tabletop Projector
卓上の投影画像をタッチジェスチャーや 空中ジェスチャー で滑らか操作を提案する研究。オクルージョンも回避し、CNNで多様なインタラクションを区別。部屋規模の大型投影やARグラスへの応用も可能。動画

Real-time Pose and Shape Reconstruction of Two Interacting Hands With a Single Depth Camera
重なり合いながら動く両手を1台の深度カメラのみから正確かつリアルタイムに再構築するマーカーレスの手法を提案する研究。両手による衝突も推定。動画
VR Facial Animation via Multiview Image Translation
VRデバイス装着者の顔の表情をリアルタイムにアバターへ反映させるシステムを提案する研究。 HMD内側に装備した9個のカメラで事前訓練をし、使用時は3個のカメラでキャプチャする。動画

Neural Re-Simulation for Generating Bounces in Single Images
1枚の静止画像に対して、バーチャルオブジェクト(ボール)の衝突及び跳ね返りから相互作用する動画を生成する機械学習アプローチを提案する研究。動画
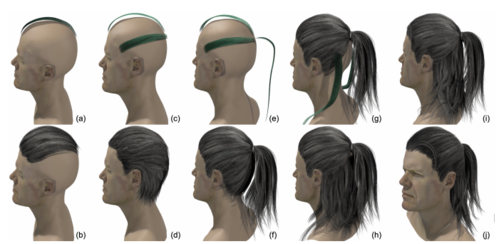
HairBrush for Immersive Data-Driven Hair Modeling
緻密な髪の3Dモデルを直感的に作成できるVRベースのヘアモデリングツールを提案する研究。 モーションコントローラを駆使して 頭部モデルを参考に髪型をストロークしていくだけで、緻密で高品質なヘアモデルを作成できる 。動画

fARFEEL: Providing Haptic Sensation of Touched Objects using Visuo-Haptic Feedback
投影型バーチャルハンドで触った実物体の触覚を再現するインタラクティブシステムを提案する研究。ローカルサイトとリモートサイトの2つのサイトで構成され、ローカルユーザは、タッチパネルを用いてリモートサイトに投影されたバーチャルハンドを操作し、実物体に触れたり、バーチャルオブジェクトを移動させたりできる。リモートサイトの実物体に触れると触覚装置を介して触覚がローカルユーザにフィードバックされる。動画
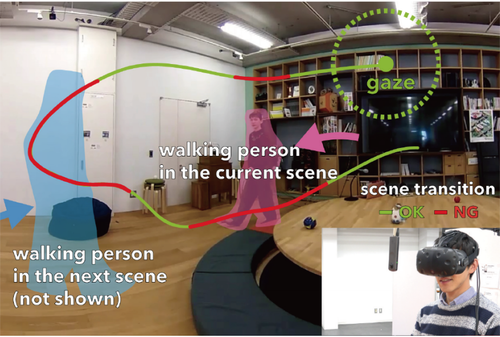
EyeHacker: Gaze-Based Automatic Reality Manipulation
同じ空間の現在と記録映像を気付かれずに自動差し替えする視線追跡ベースのVRシステム「EyeHacker 」(SRの拡張版)を提案する研究。 ユーザの視線追跡に基づいて、同じ空間におけるライブシーンと記録シーンとを自動差し替えする。動画

SurfaceBrush: From Virtual Reality Drawings to Manifold Surfaces
VR内に描いた3Dペイントを3Dモデルに変換するサーフェスモデリングツール「SurfaceBrush」を提案する研究。 描画されたストロークのポリラインに沿ってエッジ間の接続性を決定し、入力ブラシストロークから目的のサーフェスを再構築。動画

Luminance-Contrast-Aware Foveated Rendering
VRにおいて、視線先だけを高解像度に、その周囲を低解像度する中心窩レンダリングを画像内のオブジェクトも考慮して最適化する手法を提案する研究。 画像内の重要なオブジェクトは視線外でも低解像度にならないといった具合。動画

Distortion-Free Wide-Angle Portraits on Camera Phones
広角カメラによる写真の両サイドに写る顔の歪みを補正するアルゴリズムを提案する研究。 FOV 120°までの画像における両サイドの顔を他の部分に影響を与えずに局所的に補正する。動画

GestARLite: An On-Device Pointing Finger Based Gestural Interface for Smartphones and Video See-Through Head-Mounts
スマートフォン 内蔵カメラからのRGB画像入力だけでAR指先追跡と手のジェスチャ認識を高精度かつリアルタイムに実行する機械学習フレームワーク を提案する研究。動画

Live Coding of a VR Render Engine in VR
VR環境を離れることなくライブコーディングできるフレームワークを提案する研究。HMDを取り外すことなく、デバッグや既存のレンダリングロジックの調整などができる。実行時にシーンオブジェクトとVR内モニタともドラック&ドロップでやり取りすることも可能 。動画

Enchanting Your Noodles: GAN-based Real-time Food-to-Food Translation and Its Impact on Vision-induced Gustatory Manipulation
そうめんをラーメンに錯覚させるARとGANを組み合わせたリアルタイム味覚操作システム「Enchanting Your Noodles」を提案する研究。 食品の外観(色やテクスチャ)をリアルタイムに変換することで、視覚的に味覚をコントロールするアプローチ 。動画

Functional Workspace Optimization via Learning Personal Preferences from Virtual Experiences
各ユーザの動きを学習し、それぞれに適したVRワークスペースを生成する手法を提案する研究。キッチンテーブルの高さや食器棚の高さなどがパーソナライズされる。動画

Lost in Style:Gaze-driven Adaptive Aid for VR Navigation
VRユーザが現シーンでナビゲーションによる支援を必要としているかを視線追跡から予測する研究。 視線から適切な時にナビゲーションを表示/非表示することは、ユーザーの満足度を向上させる。動画

Audible Panorama: Automatic Spatial Audio Generation for Panorama Imagery
360°パノラマ画像の各オブジェクト位置(深度推定)に適した音源を割り当てる空間オーディオ・アルゴリズムを提案する研究。 画像内のシーンとオブジェクトを識別し、各オブジェクトの奥行きを推定、現実的なオーディオソースを希望の位置に配置することで臨場感を高めるアプローチ。動画

Real-time Measurement and Display System of 3D Sound Intensity Map using Optical See-Through Head Mounted Display
HoloLensとSLAMを組み合わせて、リアルタイムに3D音場を計測し可視化するシステムを提案する研究。マイクロホンアレイを可視化したい場所に配置し計測する。動画

Realistic AR Makeup over Diverse Skin Tones on Mobile
スマートフォンを用いて、より自然かつリアルタイムにメイキャップできるAR技術を提案する研究。ライブビデオストリーム上で行われ、フェイストラッキングから唇、目、頬などの顔領域を定義し、メイキャップアクセサリをレンダリング、元画像とブレンド。

Special-purpose computer HORN-8 for phase-type electro-holography
高画質画像を3D映像としてホログラフィ情報で投影できる「電子ホログラフィ」を可能にするホログラフィ用コンピュータ「位相型 HORN-8」を提案 する研究。動画

paGAN: Real-time Avatars Using Dynamic Textures
1枚の顔画像からモバイル端末に写実的な3Dアバターを作成し、自身の顔を介してリアルタイムに動かせるdeep learningモデル「paGAN」を提案する研究。動画

Transparent Mask: Face-Capturing Head-Mounted Display with IR Pass Filters
VR HMD装着者の表情を外部から取得できるIRパスフィルタを用いたHMDを提案する研究。HMD装着者の顔を外部カメラから透過して見ることを可能とするHMD。動画

Towards Multifocal Displays with Dense Focal Stacks
1秒間に1600枚の焦点面を表示する多焦点ディスプレイを提案する研究。焦点調節可能なレンズを駆動して所望の範囲の焦点距離を周期的に掃引し、焦点距離を高速かつリアルタイムに追跡することにより、多数の焦点面を表示する。動画
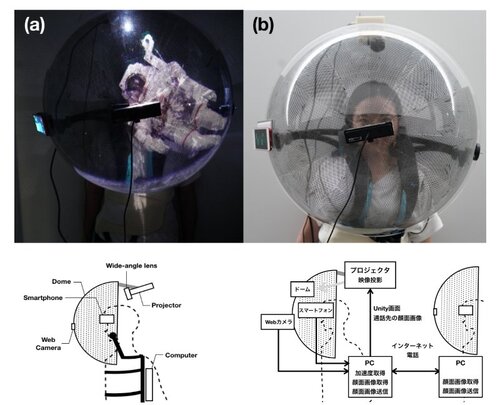
CompoundDome: スクリーンを部分的に透過することにより現実世界とインタラクションを可能にする装着型ドーム装置
半球ドーム装置を用いて映像投影でVR体験を提供するシステム「CompoundDome」を提案する研究。システムに肌が触れないため、髪の毛や化粧が崩れる心配、他人が密着で装着した機材を装着する心配もない。加えて、広視野体験(本システムの視野角は、約160°)、VR酔いの軽減にも繋がる。動画

Scenograph: Fitting Real-Walking VR Experiences into Various Tracking Volumes
リアルウォーキングVR体験において、VRシーンを小さく分割することで物理空間に依存しない設計が可能なツール「Scenograph」を提案する研究。物語の構造を維持しながら、VRシーンを分割し、所与のサイズおよび形状の実際の追跡エリアに体験を適応する。例えば、25平方メートルのVRシーンをL字型の8平方メートルの6つのシーンに分割など。動画

Verifocal: a Platform for Vision Correction and Accommodation in Head-Mounted Displays
重ねた2枚のレンズをスライドさせて焦点距離を変える視線追跡と組み合わせた可変焦点HMDを提案する研究。FOVを大きく保ったまま可変焦点できる。モバイルでも使用可能。また、最適な焦点距離は、ユーザの眼鏡処方も考慮しているため、眼鏡なしで快適な視聴体験も可能。動画

Deep Blending for Free-Viewpoint Image-Based Rendering
動き回ることが可能な実写ベースのバーチャル空間を作成できるCNNを用いた自由視点レンダリング法を提案する研究。実写画像から新規のバーチャルシーンを生成する手法。左の画像は出力結果。動画
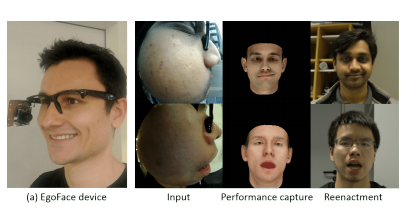
EgoFace: Egocentric Face Performance Capture and Videorealistic Reenactment
メガネフレーム側面に装着したカメラによる顔の側面映像から正面の表情を再現する機械学習を用いた手法を提案する研究。 RGB魚眼カメラから撮影した着用者の横顔を入力に、正面の顔をリアルタイムに再構築。動画

Deep Volumetric Video From Very Sparse Multi-View Performance Capture
複数台(3-4台)のRGBセンサーでさまざまな角度から実際に動く人の全身運動をキャプチャし、再構築するCNN(Convolutional Neural Network)を用いた手法を提案する研究。動画

LayoutNet: Reconstructing the 3D Room Layout from a Single RGB Image
1枚のパノラマ画像から3Dルームレイアウトを推定し再構築する手法を提案する研究。直方体ではないL字型のレイアウトにも対応する。動画

Make your own Retinal Projector: Retinal Near-Eye Displays via Metamaterials
網膜に画像を直接投影することで、現実空間と仮想オブジェクトの調和を実現する透過型ミラーデバイスを用いたレーザ投影システムを提案する研究。LCOS-SLM型レーザプロジェクターを光源に、TMDで離散的に光源を分割し、眼球レンズの位置で離散点光源として再収束させることで網膜に投影する。動画
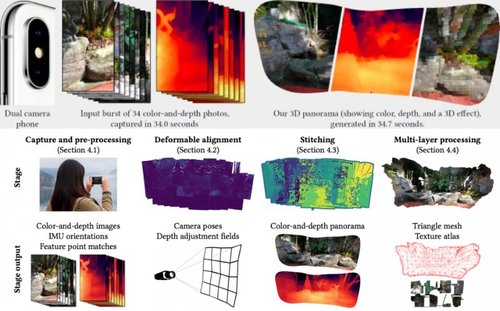
デュアルレンズ搭載スマートフォンで撮影した画像から3Dパノラマを生成する技術を提案する研究。スマートフォンを動かして複数枚の画像を1秒間隔でキャプチャし、 深度マップ、スティッチング、任意のデバイスでレンダリングできるテクスチャ付きメッシュに変換する。動画

Augmented Reality Powers a Cognitive Prosthesis for the Blind
視覚障害者向けにHoloLensを用いて周囲情報を取得し音声で伝えるサポートシステムを提案する研究。ユーザの周囲をスキャンしマップを作成、シーン内の各オブジェクトに対して、オブジェクトの位置を形成するような音声を生成し伝達する。壁などへの衝突を回避できる。予め指定した物体にラベリングしておくと、何があるかも教えてくれる。

In the Blink of an Eye –Leveraging Blink-Induced Suppression for Imperceptible Position and Orientation Redirection in Virtual Reality
VR体験者の目の瞬き時にバーチャルシーンを少し回転させるリダイレクトウォーキング技術を提案する研究。 瞬きをしている時間における知覚ができない現象を利用して、気が付かれない値、瞬き中に約4〜9cm、約2〜5°の回転を実行する。これにより、物理空間以上の広さをバーチャル空間で歩行する。動画

Scene-Aware Audio for 360° Videos
一般的なモノラルマイクで収録された屋内での360°ビデオシーンに後から空間オーディオを追加する手法を提案する研究。専用のAmbisonicsマイクがなくても、視聴者に対して視野角と一致する空間オーディオを低コストで提供 できる。動画
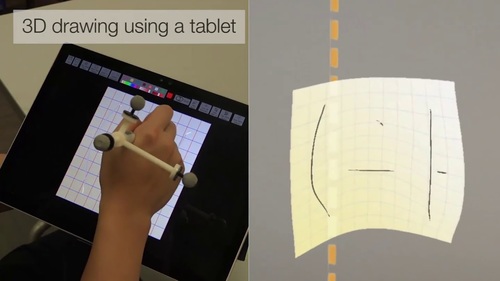
SymbiosisSketch: Combining 2D & 3D Sketching for Designing Detailed 3D Objects in Situ
2Dスケッチと3Dスケッチ(AR)を統合したハイブリット描画システム「SymbiosisSketch」を提案する研究。 3D空間に立体的な絵を描けることに加えて、3D空間で定義した曲面や平面キャンバスをタブレットに投影し2Dベースで描くことができ、逆にタブレット上で描くことで入力点が3Dキャンバスに投影され、新しいストロークが生成される。動画

Supporting Responsive Cohabitation Between Virtual Interfaces and Physical Objects on Everyday Surfaces
光学シースルーHMD(HoloLensなど)を用いて机や壁などの表面をタッチスクリーンにするインタフェース「MRTouch」を提案する研究。 机の表面をタイピングしたりなどWebブラウザのように使用したり、壁をキャンパスのようにし絵を描いたりが可能になる。動画

Remixed Reality: Manipulating Space and Time in Augmented Reality
Kinect 8台からのライブ3D再構築ルームをVRで体験できるシステムを提案する研究。部屋の天井に取り付けられた8台のKinectから取得したデータを、1つの3Dルームに結合し再構築する。物理ルームと3D再構築ルームはライブで位置を合わせする。現実空間をあたかも操作しているかのように感じられる。動画

Video Based Reconstruction of 3D People Models
1台の単眼カメラから人体3Dアバタを4.5mm精度で生成する機械学習を用いた手法を提案する研究。複雑なカメラ機器や深度センサは必要とせず、1台のカメラからの単一の視点で、ぐるっと回るだけでスキャンし3Dモデルを作成する。動画
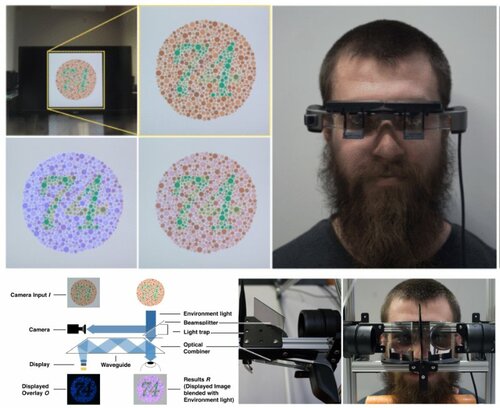
ChromaGlasses: Computational Glasses for CompensatingColour Blindness
光学シースルーHMDを用いて色覚異常者を補助するメガネ型デバイス「ChromaGlasses」を提案する研究。ユーザが見る環境を感知し、環境中の重要な特徴(ユーザが区別できない色)を識別し検出、そして検出した重要な特徴に応じてHMDによってピクセル精度で色を補正することにより、色覚異常をリアルタイムに緩和させる。動画

Object-wise 3D Gaze Mapping in Physical Workspace
追跡したユーザの視線を3Dオブジェクト上に可視化し、各オブジェクトをどれだけ注視しているかを解析する3D視線マッピングシステムを提案する研究。各オブジェクトの視線分布を解析し、円グラフやヒートマップ、オブジェクトを色分けなどのランキング形式で可視化する。動画
GANerated Hands for Real-Time 3D Hand Tracking from Monocular RGB
1台の RGBカメラから手指の追跡をするCNNを用いたリアルタイム3Dハンドトラッキング技術を提案する研究。物で隠れた指も正確に推定可能。動画

RoMA: Interactive Fabrication with Augmented Reality and a Robotic 3D Printer
VRデバイスによるビデオシースルー技術とロボットアーム3Dプリンタを使用して、リアルタイムにモデリングしながら同時に印刷できるシステム「RoMA(Robotic Modeling Assistant)」 を提案する研究。 モーションコントローラを駆使して、エディタで3Dモデルを作成 、と同時にロボットアームが3Dオブジェクトを作成する。動画

Fast Gaze-Contingent Optimal Decompositions for Multifocal Displays
眼球運動の矯正を用いた新たな多焦点ディスプレイ技術を提案する研究。以前より計算時間を3桁改善する分解アルゴリズムと、視線追跡から計算し眼球運動の矯正を用いることで、 視線に合わせて体験者に適切な焦点面を高品質で提供するマルチフォーカスディスプレイを可能にする。動画

Behind The Palm: Hand Gesture Recognition through Measuring Skin Deformation on Back of Hand by using Optical Sensors
手指を動かした時の手の甲の皮膚変形を計測し機械学習で推定することでハンドジェスチャーを認識する 装着型ウェアラブルデバイス を提案する研究。デバイスは、13個の反射型光センサー(フォトリフレクタ)が横一列に配置されており、手指を動かした時に変化する手甲の皮膚と装置までの距離を取得、「SVM(Support Vector Machine)」 で識別する。手指本来の動作を阻害することなくジェスチャー認識 ができる。動画

Total Capture: A 3D Deformation Model for Tracking Faces, Hands, and Bodies
顔の表情やハンドジェスチャの細部な動きと体の大規模な動きを同時にマーカレスで複数人キャプチャできる3Dモデル手法を提案する研究。VGAカメラ480台、HDカメラ31台、Kinectセンサー10台が整備されたドーム型ボディスキャナシステムを用いて、胴体や腕の大きなモーションを同時にキャプチャ、細かな全身運動を再現する。動画
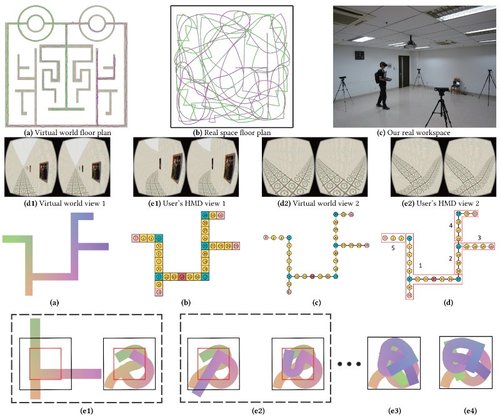
Smooth Assembled Mappings for Large-Scale Real Walking
VRにおいて、狭い物理空間で大規模な仮想空間を歩行できる分割統治法を用いた新たなリダイレクト・ウォーキング「Smooth Assembled Mapping(SAM)」を 提案する研究。 通路が連続するVR空間の平面図を分割し、物理世界の平面図に折り曲げて歪んだマップを生成する。動画
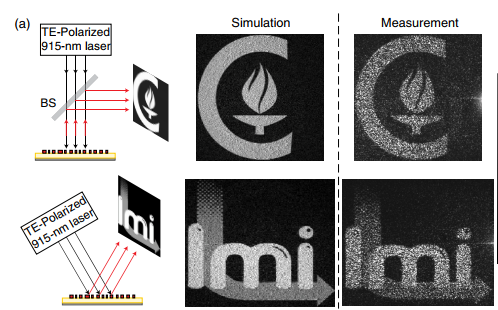
Angle-Multiplexed Metasurfaces: Encoding Independent Wavefronts in a Single Metasurface under Different Illumination Angles
解像度を低下させることなく2つのホログラムを1つの表面上に再現する角度多重ホログラムの提案をする研究。表面に当たる入射光の角度に応じて異なる反射を生成し、異なるホログラムを再現、 1枚の表面上に複数のホログラムを再構築する。

NaviFields: Relevance fields for adaptive VR navigation
VRにおけるユーザの歩行環境を動的に自動調整する適応型VRナビゲーション技術「NaviFields」 を提案する研究。インタラクション要素が高い領域は通常移動で、関連性のない領域は高速移動にする。動画
Design and prototype of an augmented reality display with per-pixel mutual occlusion capability
実オブジェクトの後ろにバーチャルオブジェクトを隠し配置できる相互遮蔽可能な光学シースルーHMDを提案する研究。偏光ビームスプリッター(PBS)、空間光変調器(SLM)などが用いられ、ピクセルごとの相互遮蔽をレンダリングする。画像:デジタルティーポットが物理物体の黒のスプレー缶の後ろに、物理物体のスクイズボトルと白いスプレー缶の前に鎮座する。
Articulated distance fields for ultra-fast tracking of hands interacting
最大1000fpsで動作する深度カメラベースのハンドトラッキングを提案する研究。手や指が互いに重なっても、途切れることなく追跡する。動画
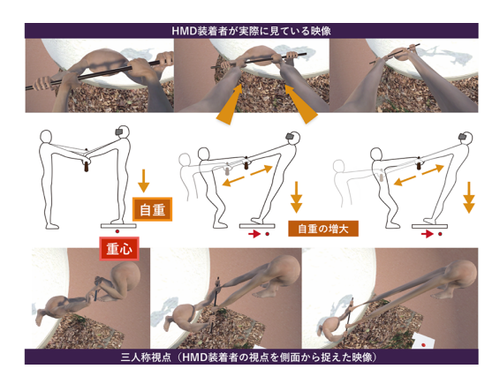
HMD を介したポールを引っ張り合うことによる腕が伸縮する感覚の誘発
「腕が伸びる感覚」をVR体感できるシステムを提案する研究。HMDを装着した体験者と協力者とが対面となり、⼀対⼀でポールを引っ張り合う過程で表現する。VR内では、自分の腕が表示され、「(現実世界の)腕を引っ張られる強さ」に応じて、「(イメージの世界の)腕の⻑さ」を滑らかに伸ばし、あたかも腕が伸びる感覚を再現。動画

Perceptually-Guided Foveation for Light Field Displays
視線先だけを高画質に描画する「中心窩レンダリング」とフォーカス調整ができる「4Dライトフィールド・ディスプレイ」を統合させた提案をする研究。ユーザーが見ている箇所と奥行きを一致させる試み。画像:左図:視線は右でフォーカスは奥。右図:視線は右でフォーカスは手前。動画

ChromaBlur: Rendering Chromatic Eye Aberration Improves Accommodation and Realism
デフォーカスと色収差を考慮に入れ自然観察で生じるものに近い網膜画像を生成する色補正レンダリング方式「ChromaBlur」を提案する研究。従来のレンダリングよりも自然な奥行きの印象を与えることができ、また、焦点調節可能なレンズと視線トラッキングを組み合わせることで、輻輳と焦点距離の不整合問題を最小限に抑えることができる。動画

AffectiveHMD:組み込み型センサを用いた表情認識とバーチャルアバターへの表情マッピング
VRヘッドセット装着者の表情の種類と強さを機械学習で推定し、アバターに反映させる技術「AffectiveHMD」を発表する研究。HMDに組み込んだ反射型光センサ群は、発光部から赤外光を照射し反射光を受光することで、顔表面との距離を計測する。自然、喜び、怒り、驚き、悲しみの5種類が対象。動画

Air Mounted Eyepiece: Design Methods for Aerial Optical Functions of Near-Eye and See-Through Display using Transmissive Mirror Device
広視野角の光学シースルーHMDを実現するための手法「AME」を提案する研究。MDCS(Micro Dihedral Corner Reflector Array)を用いたTMD(Transmissive Mirror Device、透過型ミラーデバイス)を使用して目の前にバーチャルレンズを提示することで実像をレンダリングし、VRヘッドセットを着用せずとも同等の体験を光学シースルーHMDベースで適応可能にする。動画

同時に体験する2人ペアのVRユーザーに対し、別々のシチュエーションでありながら相互に関連する行動を紐付けて実行する研究。画像:一方が魚釣りで竿の反発力を再現し、一方が凧揚げの引きを再現する。一方は出現する柱を踏んで前進するのに対して、一方がパズルを解くためにボックスを再配置する。動画

Baxter’s Homunculus: Virtual Reality Spaces for Teleoperation in Manufacturing
VRからロボットを遠隔操作するシステムの研究。VR制御室には、目の前にロボットの目からの映像が2Dモニターとして映し出され、両サイドにはロボットの手のカメラからの映像がサブモニターとして表示され、 それらを見ながら腕と手を操作する。動画
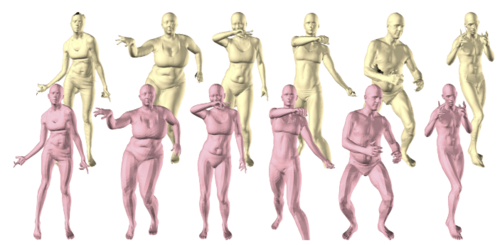
Embodied Hands: Modeling and Capturing Hands and Bodies Together
フルボディモーションキャプチャで、より詳細な手の動きを再現する手法「Embodied Hands」を提案する研究。全身のモーションキャプチャにおいて、手の指などの細かい箇所のノイズを、より精密に表現したのが本手法。動画
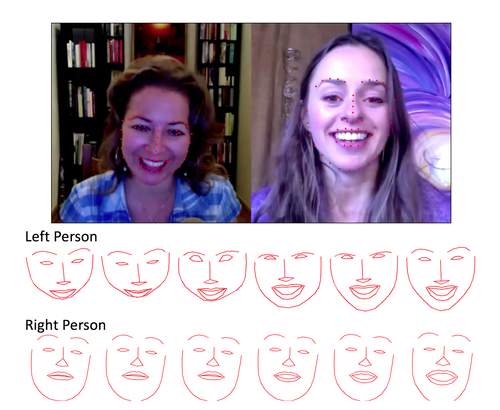
Learn2Smile: Learning Non-Verbal Interaction Through Observation
ユーザーの顔の表情を読み取りエージェントと非言語対話を可能にする機械学習モデル「Learn2Smile」を提案する研究。マシーン側が、 自然言語認識や音声認識で取得する際に、人間の表情も読み取り判断に役立てるというシステム。

SpinVR: Towards Live-streaming 3D VR Video
360°の映像をカメラの高速回転でライブストリーミングするVRカメラシステム「SpinVR」を提案する研究。2つの魚眼レンズを搭載したカメラアレイを水平方向に高速回転させ、全方向性ステレオ(ODS)形式でネイティブにキャプチャ。動画
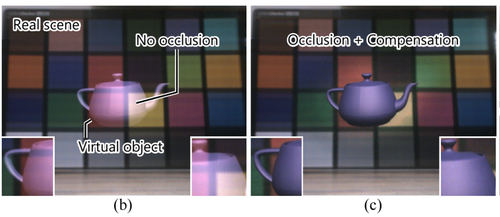
Occlusion Leak Compensation for Optical See-Through Displays using a Single-layer Transmissive Spatial Light Modulator
光学シースルーHMD(OST-HMD)において、実世界に重なって表示される半透明なバーチャルオブジェクトを実物のようにくっきり写す不透明描写方法を提案する研究。バーチャルオブジェクトに応じて計算された遮蔽マスクをLCDに表示し、仮想物体に重なる背景の光を遮ることで、遮蔽を実現。動画
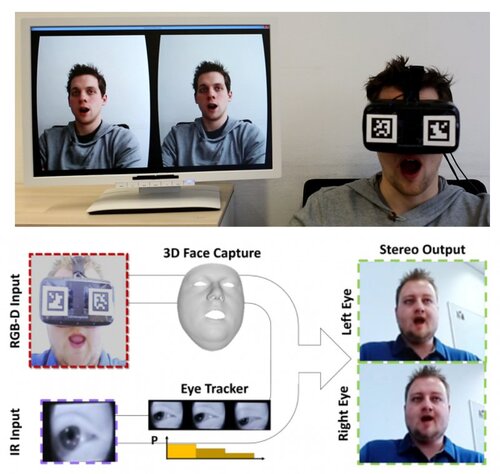
FaceVR: Real-Time Facial Reenactment and Eye Gaze Control in Virtual Reality
VRヘッドセット装着者の顔の表情や眼の動きを捉えリアルタイムに再構築する技術「FaceVR」を提案する研究。正面からRGB-Dセンサーで顔全体をキャプチャし、HMD内部のIRセンサーで眼球をトラッキング 。リアルタイムに顔を制御し再レンダリングする。動画
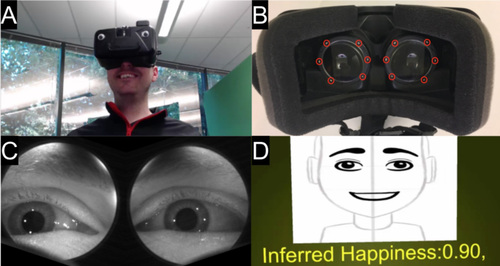
Eyemotion: Classifying facial expressions in VR using eye-tracking cameras
VRヘッドセット装着者の眼を捉えた画像のみから残りの顔全体の表情をDeep learningを用いて推定する手法「Eyemotion」を提案する研究。推定した顔の表情を動的アバターへリアルタイムに反映。動画

Magic Bench — A Multi-User & Multi-Sensory AR/MR Platform
CGキャラクターと戯れるベンチベースのAR体験プラットフォーム「Magic Bench」を提案する研究。自身が映る目の前の巨大画面を見ながら、3DCGによるキャラクターと戯れたり、エフェクトを共有したりが可能。ベンチ自体には、ハプティックアクチュエーターを含んでいるだけでなく、参加者の位置と数を知る役割を果たす。動画

A Wide-Field-of-View Monocentric Light Field Camera
視野138°の情報を取得し、4次元画像を生成する単眼式ライトフィールド・パノラマカメラを提案する研究。マイクロレンズアレイを使用して、単焦点レンズと複数のセンサーを結合し、広視野角でライトフィールドを取り込めるコンパクトな光学設計。動画
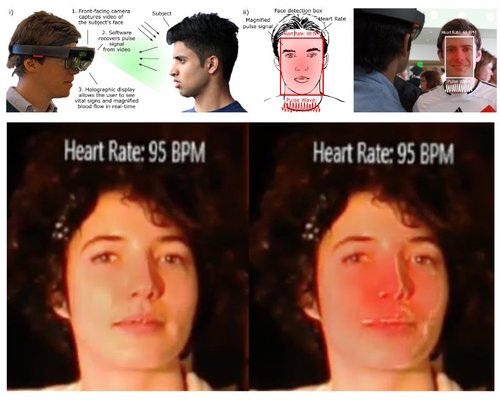
Cardiolens: Remote Physiological Monitoring in a Mixed Reality Environment
HoloLensなどのARヘッドセットを使用してバイタルサインのリアルタイムな可視化を可能にする生理学的測定ツール「Cardiolens」を提案する研究。前方にいる被験者の顔から反射した周囲光を捕らえ、その光を分析し血液量パルスとバイタルサインを計算する。動画
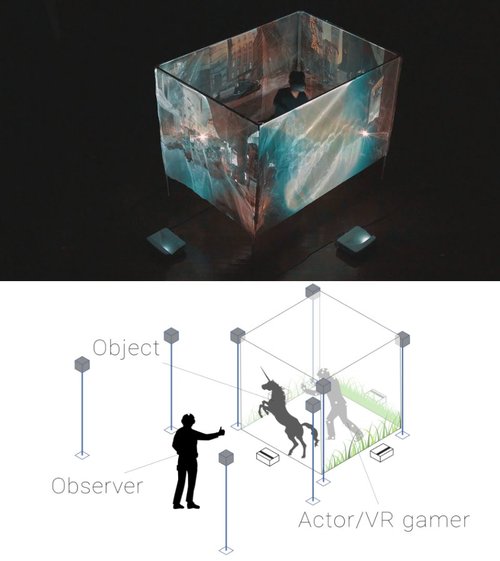
CAVE-based Visualization Methods of Public VR Towards Shareable VR Experience
VRプレイヤーの体験を他者(オブザーバー)と共有するシステム「ReverseCAVE」を提案する研究。立方体に配置する4つの半透明スクリーンとプロジェクター複数台で構成され、スクリーンにはVR空間上のオブジェクトが投影され、オブザーバーは立方体内でプレイするユーザー含め目視できる。オブザーバー自身も追跡するため、移動により見る角度が変わっても位置関係を保つ。動画
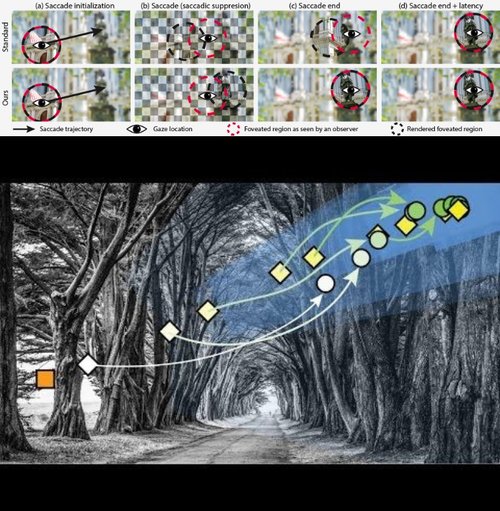
Saccade Landing Position Prediction for Gaze-Contingent Rendering<
サッカード眼球運動中のレンダリングで画像を更新する手法を提案する研究。サッカードが終了する可能性が高い場所を予測し、予測が利用可能になるとすぐに新しい固定場所の画像を提供するというアプローチ。次見る場所を予測し、固定が確立される前に新しい固定の正しい画像を提供する。

空間光変調器(Spatial Light Modulator,SLM)を使用して光がディスプレイに入る方法を変えて、焦点を曲げて見せるVRディスプレイ「Focal Surface Display」を提案する研究。光源からの光の分布(位相・偏波面・振幅・強度・伝播方向)を電気的に制御することにより光を変化させ、画像の選択された部分の焦点を変更するために曲げる。動画
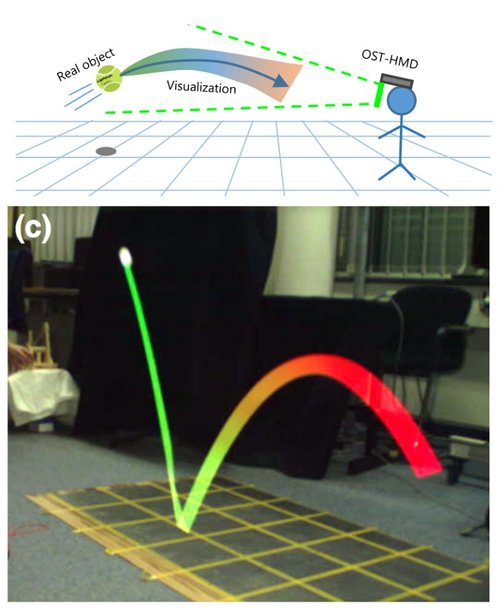
Laplacian Vision: Augmenting Motion Prediction
via Optical See-Through Head-Mounted Displays
光学シースルーHMD越しに見ることで、ボールが跳ねる物理オブジェクトの未来動作を予測し先に表示してくれる未来予知システムの研究。将来の軌道を予測し、リアルタイムに視覚化。動画
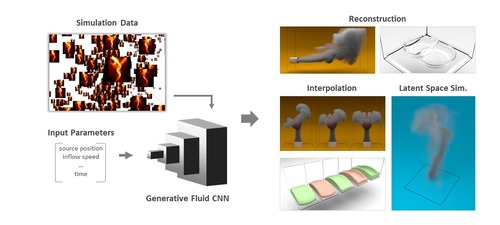
Deep Fluids: A Generative Network for Parameterized Fluid Simulations
Pixarによる研究チームは、流体力学に基づいて気体や液体などの物理ベースのシミュレーションを合成するためのdeep learningアーキテクチャ「Deep Fluids」を提案する研究。乱流の煙から粘性のある液体まで多種多様な流体動作を構築し、トレーニングデータにない連続的な変化に対しても、もっともらしい動きを合成する。動画

Virtual Agent Positioning Driven by Scene Semantics in Mixed Reality
ARシーンの意図を考慮して仮想キャラクタを適切に配置するCNNを用いた手法を提案する研究。HoloLensに搭載されたRGB-Dカメラからシーンの3Dモデルを再構築し、Mask R-CNNで物体検出し、オブジェクトを検出。シーンの意味および対話の目的に従ってバーチャルキャラクタを配置する。
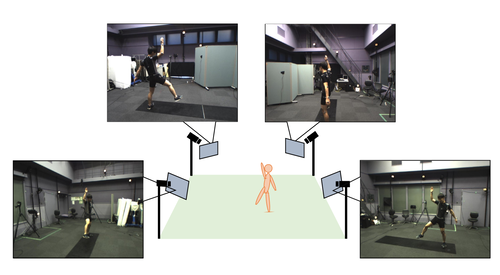
Video Motion Capture from the Part Confidence Maps of Multi-Camera Images by Spatiotemporal Filtering Using the Human Skeletal Model
複数台のRGBカメラだけから人のモーションキャプチャをリアルタイムに行う技術「VMocap」を提案する研究。4台のカメラを同期させて、異なる方向から人物のビデオ映像を録画し、それぞれをDeep Learning処理して画像から関節の存在確率を推定、これらを参考にして、多自由度の人間骨格モデルを動かすことで、運動の3次元再構成を行う。動画