NVIDIAとカリフォルニア大学バークレー校の研究者らは、機械学習を用いて、任意の画像から2048×1024高解像度のフォトリアリスティックな画像合成モデルを生成できる手法を論文にて発表しました。
High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs
GitHub:NVIDIA/pix2pixHD

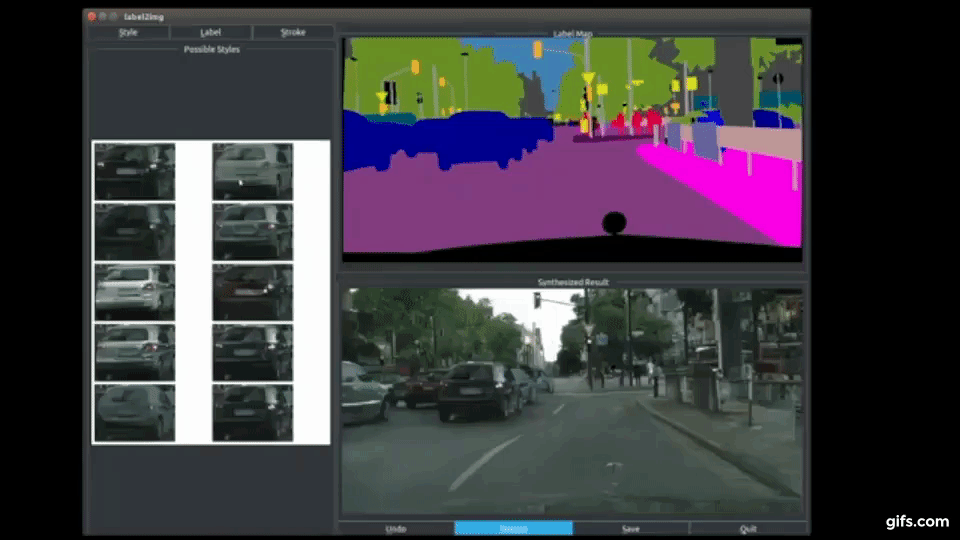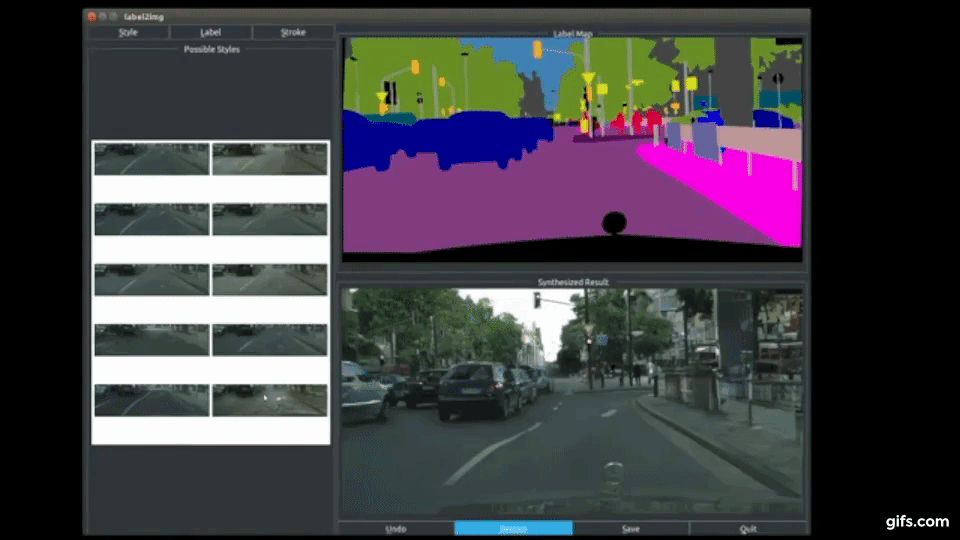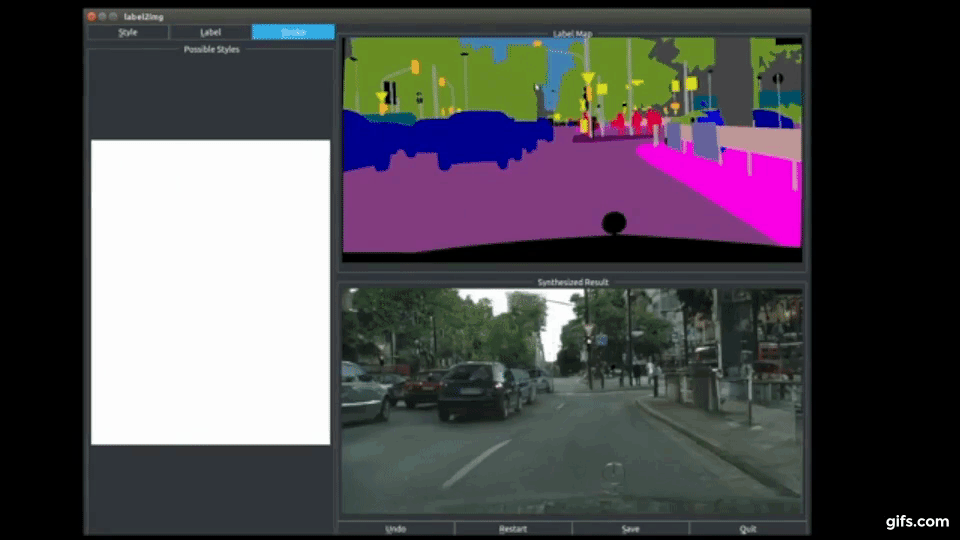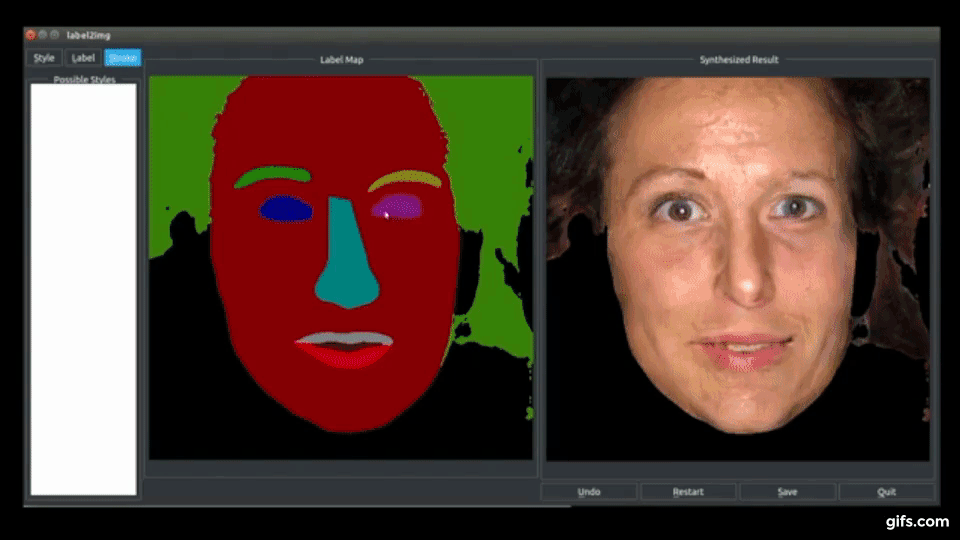
本稿は、Conditional GAN(Conditional Generative Adversarial Network)を用いて、ユーザがシーン内の各オブジェクトを合成編集できる手法を提案します。
画像をセマンティックラベルドメインに変換し、ラベルドメイン内のオブジェクトを編集してから、イメージドメインに戻すことができ、画像内の木を建物に置き換える、車の色や道路の質感を変える、車を増やすなど、任意の画像から新しいシーンを生成することができます。
また、本フレームワークは、Conditional GANを用いて高解像度で鮮明な画像を生成した成果が評価されます。本稿でも、既存の研究「pix2pix」と「CRN」との比較画像が用いられ、高画質になったことを実証しました。

(pix2pixとCRNと本提案が比較された画像。右下の本提案が鮮明に見えるのが確認できる)

(同じくpix2pixとCRNと本提案が比較された画像)
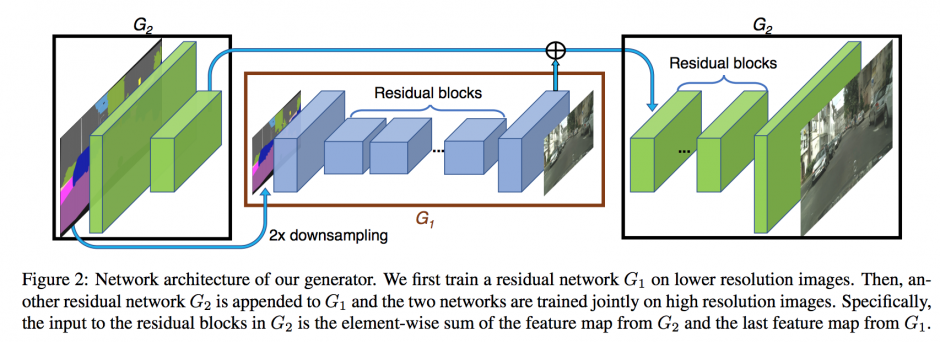
提案手法では、ResNet(Residual Network)の仕組みを導入しより深くしたこと、また、マルチスケールの生成器と識別器アーキテクチャを取り入れたことで、高解像度で写実的な画像を生成することに成功しました。
本モデルは、他のデータセットにも適応することができ、あるデータセットのテクスチャを使用して別のデータセットの画像を合成することが可能です。

上図は、本モデルを他のデータセットでテストした画像で、左図では「ADE20K dataset」を使用しベットやカーテンの色や質感を編集、右図では「Helen Face dataset」を使用し任意の顔写真の肌の色や髭を生やしたりリアルタイムで個々の顔パーツの属性を編集します。
関連
NVIDIA、教師なし学習と生成モデルを組み合わせて画像から画像へ変換する手法を論文発表。晴れを雨のシーンに、冬を夏のシーンに変換など | Seamless