NVIDIAの研究者らは、教師なし学習と生成モデルを組み合わせて画像から画像へ変換する手法を論文にて発表しました。
Unsupervised Image-to-Image Translation Networks
本稿は、インプットした画像を、異なるドメインに対応する画像に変換し出力する手法を提案します。例えば、冬のシーンを入力し同じ場所の夏のシーンを出力したり、晴れのシーンを入力し同じ場所の雨のシーンを出力したり、などが可能になります。

(左図が入力で右図が出力。上段:冬の道路画像から夏の道路画像へ変換。下段:晴れの道路画像から雨の道路画像へ変換。)
これらは、晴れの道路と雨の道路を学習し変換を可能にしているのですが、両者がペア(同じ道路)で学習しているのではなく、それぞれが違う道路を独立して学習しています。
それは、教師あり学習のラベル付きデータによるものではなく、一方に属するデータをそれぞれが独立して学習する「教師なし」を採用しているということです。このことで、大量にラベル付きデータセットを用意する必要がないため、大幅にコストを下げることができます。
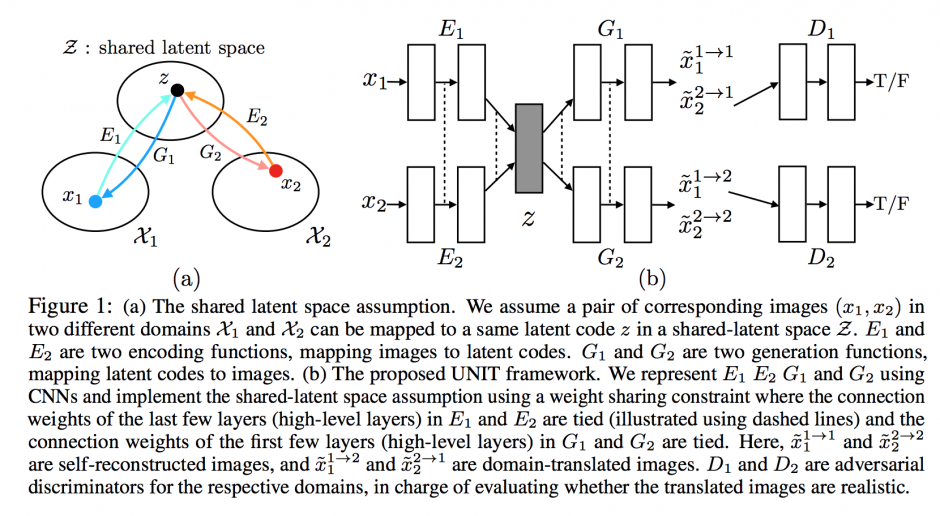
また、本手法は、生成モデル「VAE(Variational AutoEncoder)」と「GAN(Generative Adversarial Network)」が組み合わせて用いられます。
GANとは、生成器と識別器の2種類のネットワークが存在し、2つが対立し合い学習していく手法です。一方がインプットした画像そっくりに生成し、一方がそれを本物かどうかを判別する。そうやって一方で本物に似せる能力を高め、一方で判別する能力を高め、これら競合する2つのネットワークを使用し精度を向上させるのが敵対的生成ネットワーク:GANになります。
下図の(b)本フレームワークでは、Gが生成器、Dが識別器になります。また、EはVAEのEncoderです。
本手法を活用すると、例えば、1枚の顔写真から髭を生やしたり、笑顔にしたりなどの画像に変換することができます。

他にも、猫をトラに変換したり、猫をライオンに変換したり、犬を別の品種に変換したり。

現実世界を仮想世界に変換することも。

そして、NVIDIAは、本手法が自律走行車に役立てることができると言います。一度の訓練データで晴天、曇り、雪、雨、夜間などの様々な仮想条件をシミュレートすることができ、効率的に学習ができると。

関連
Microsoft Research等、異なる2枚の画像の特性(色やテクスチャなど)を転送し合成する新手法を論文で公開。画像類推に深層畳み込みニューラルネットワークを使用 | Seamless