Googleとカリフォルニア大学バークレー校の研究者らは、テキストから訓練されたニューラルネットワークを使って人間のようなスピーチを生成する人工音声生成モデル「Tacotron 2」を論文にて発表しました。
Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions
Audioのサンプルはこちらから聞けます。
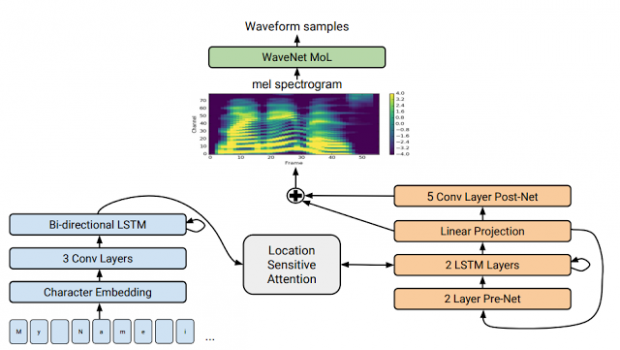
(Tacotron 2のアーキテクチャ)
本稿は、Googleの以前の機械学習音声生成プロジェクト「WaveNet」と「Tacotron」のアイディアを取り入れ改良した機械学習モデルを提案します。
本アプローチは、複雑な言語機能や音響機能を入力として使用するのではなく、スピーチの例とそれに対応するテキストだけを使って訓練し人間のようなスピーチをテキストから生成します。
精度が向上したとはいえ、複雑な言葉を発音するのが難しく、極端な場合には奇妙な音をランダムに生成することさえあります。また、リアルタイムで音声を生成することができません。楽しい音声や悲しい音声を出すなどの制御をすることもできません。これらは今後の課題としています。