Appleは、バーチャルパーソナルアシスタント「Siri」の背後にあるDeep learningベースの技術について、その中でもdeep MDNベースの「音声合成 テキスト読み上げ(TTS:text-to-speech)」に関するシステムの詳細を公開しました。
同社が構築するSiriのしゃべる音声は、更新とともにより自然に、より現実の人間に似た音声になってきており、今回発表されたTTSシステムも来年秋に最終版をリリースするiOS11に搭載するとした最新の音声合成技術になります。
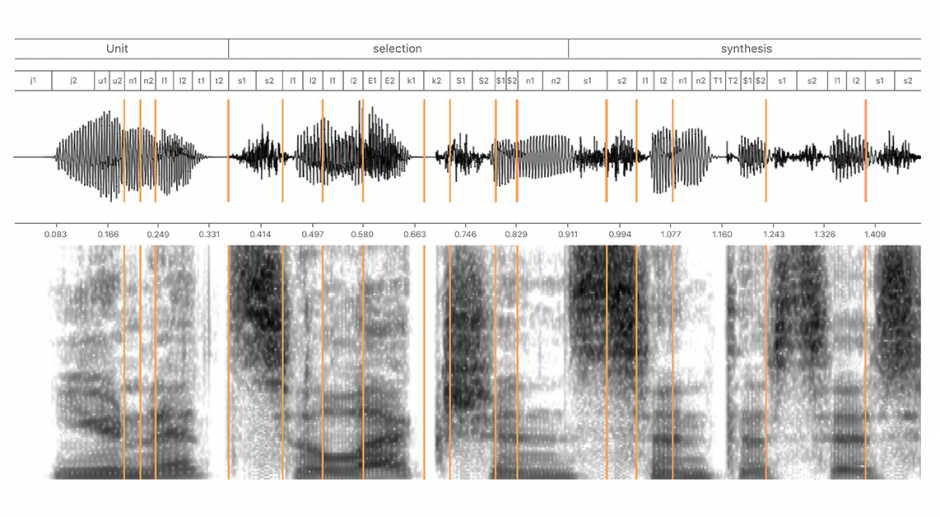
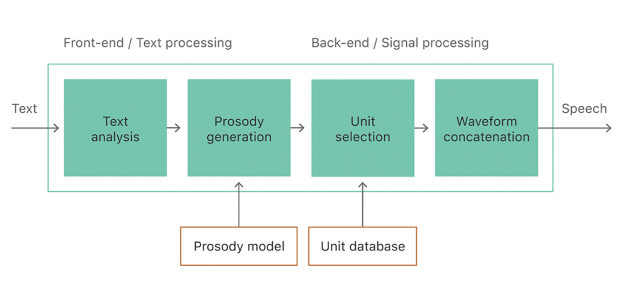
同社の合成技術は、単位選択合成(Unit selection synthesis)に基づいており、人の声をスタジオで長時間録音した音声をユニットにスライスしデータベース化、次いで、入力テキストに従ってそれらを再結合し全く新しい音声を生成します。
トレーニング音声データには、48kHzでサンプリングされた最低15時間の高品質音声録音が用いられています。ユニット数は、100万から200万ほど。
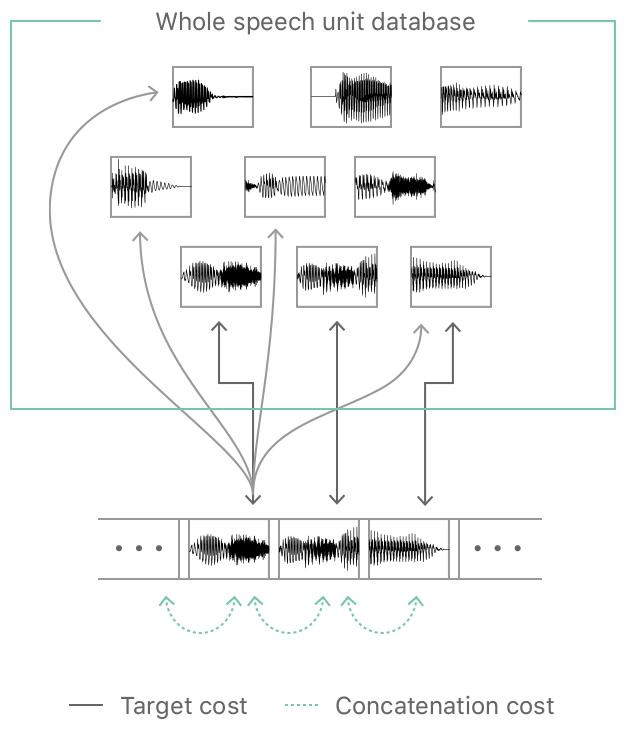
同社TTSの目標としては、データベース内のユニットのターゲットコストと連結コストの両方を自動的かつ正確に予測できるDeep learningに基づいた統一モデルを訓練することです。
そのために、DNN(deep neural network)とGMM(Gaussian mixture model)を組み合わせたdeep MDN(mixture density network)を使用します。
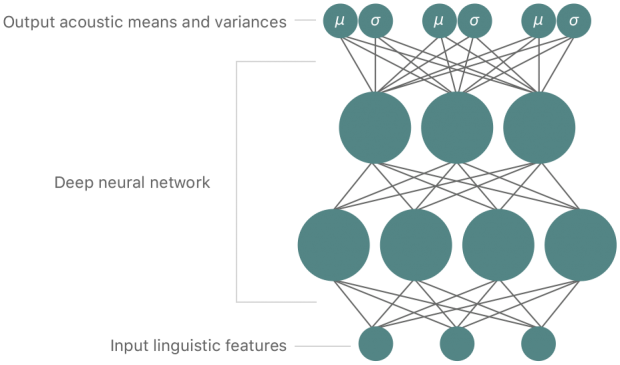
そして、iOS11で使用するTTSシステムもdeep MDNベースのHybrid Unit Selection Synthesisであり、何百人もの候補者から厳選した女性を採用し、20時間以上のスピーチを録音、データベースを作成しました。
その結果、新しいUS English Siriの声は、iOS9、iOS10に比べ、より自然に聞こえるようになりました。
今回発表した記事中にそれぞれ比較した音声が公開されており、聴き比べすることができ、iOS11の滑らかさを体感することができます。
関連
Disney Research等、音声データからそれに合わせた顔面アニメーションを生成するDeep Learningアプローチを論文にて公開 | Seamless