メガネ、ウォッチ、イヤホン、コンタクト、インプラントなどウェアラブルデバイスが多く研究されていますが、これらに対しての入力方法もまた多く研究されています。その中でも、音声入力という分野があります。声を出して指示し、所望のタスクを稼働させるインタフェースです。
しかしながら、街中や職場、学校、家など、周囲に人がいる状況で声を出す行為は羞恥心やプライバシーの問題でやりづらいのが現状です。この課題を解決するために、小声もしくは無発声で音声入力をするアプローチが研究されています。今回は、5本の研究を紹介します。
1 「息を吸いながら喋る」ことで周囲に気づかれずに音声入力を可能にするシステム「SilentVoice」
Microsoft Researchの研究者は、「息を吸いながら」喋る時に出る非常に小さな音を利用した音声入力インタフェースデバイス「SilentVoice」を発表しました。
論文:SilentVoice: Unnoticeable Voice Input by Ingressive Speech
著者:Masaaki FUKUMOTO(Microsoft Research)
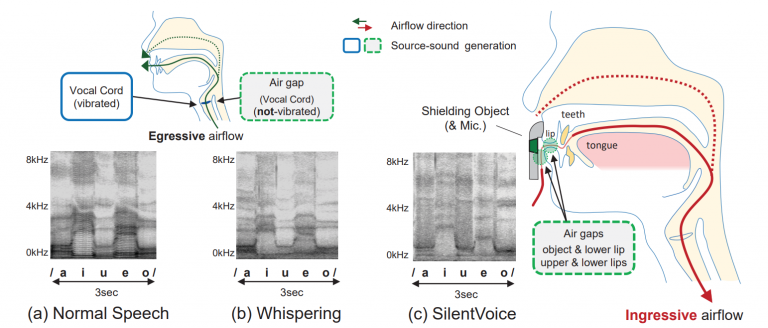
本論文は、ingressive speech(吸気発話)法を用いて、非常に小さい音(漏洩音量39dB未満)での音声入力を可能にするシステムを提案しています。静かな場所だけではなく、80dBの騒音環境下においても周囲に気づかれずに音声入力が行えます。
本提案手法は、我々の通常音声やささやき声のように、息を吐きながら喋るのとは逆に、息を「吸いながら」発話動作をした時に出る僅かな音声を用いるのが特徴です(通常は使われない喋り方なので少し慣れが必要ですが、15分程度で喋れるようになるとのことです(練習方法は論文末尾に掲載))。吸気方向の気流を用いた場合「ポップノイズ(息吹きノイズ)」が発生しないため、マイクを口の正面直前(2mm以下)に置くことができ、高いS/N比で音声を捉えることが可能になります。また、マイクロホンのDC出力を用いて気流の方向を検出することで、通常発話とコマンド音声の分離が簡単に行える(精度98.8%)ため、音声アシスタントとの対話において、会話の先頭に「おまじない」の言葉をつける必要もなくなります。
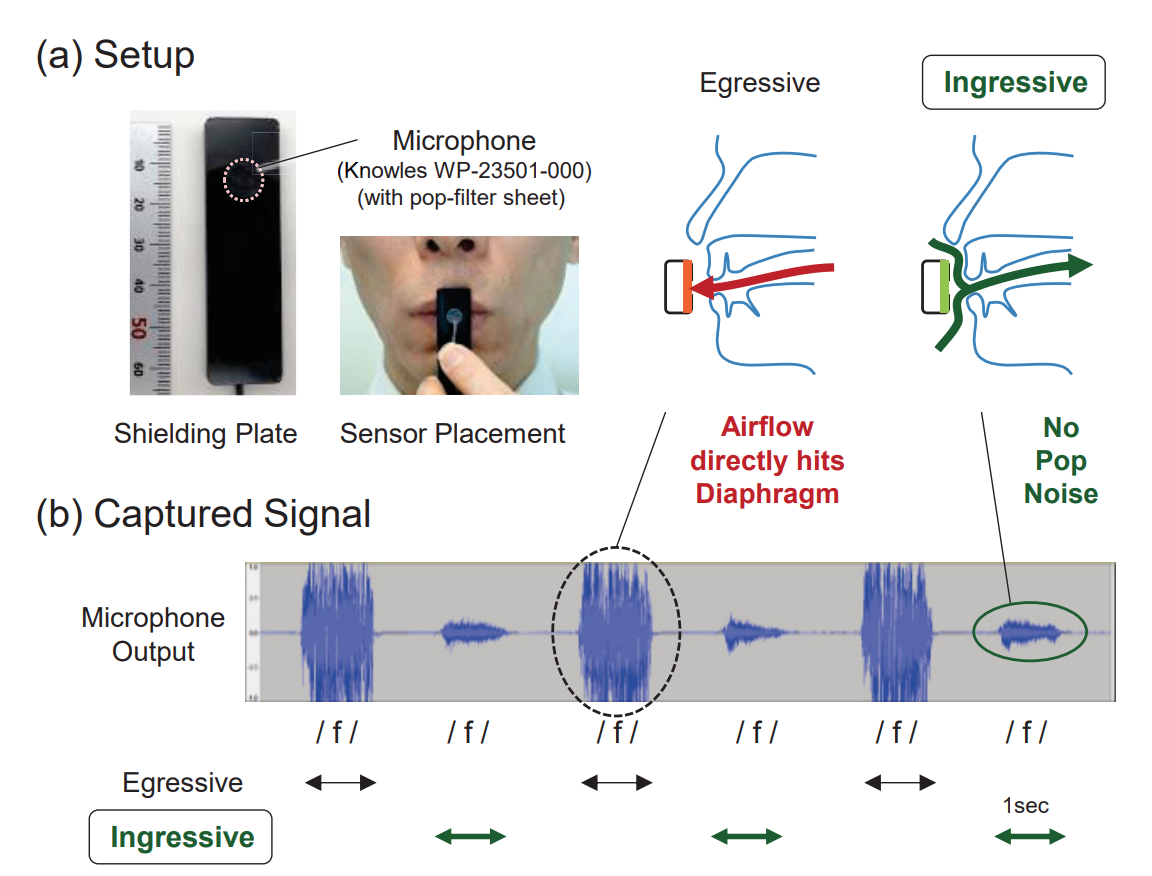
漏洩音量が39dB未満と非常に小さいため、静かな場所でも周囲に迷惑をかけることなく音声入力できます。また、マイクが口に非常に近い(超近接設置)ことで大きなノイズキャンセル効果が生まれるため、騒々しい環境(80dB)での使用も可能です。本提案手法は Bluetooth Headset などの機器に簡単に組み込むことが可能なほか、将来的には歯に埋め込むインプラント形式の人体拡張デバイスとしての使用もイメージしています。(下図右下)

2 口パクから発話内容を検出する超音波エコー映像とdeep learningを組み合わせた無発声音声システム「SottoVoce」
東京大学とソニーコンピュータサイエンス研究所による研究チームは、 声を出すことなく口パク動作を行うだけで発話内容を認識する無発声音声を、超音波エコー映像とdeep learningを組み合わせて検出するシステム「SottoVoce (ソット・ヴォーチェ、音楽用語で 「ささやくように」)」を発表しました。
論文:SottoVoce: 超音波画像と深層学習による無発声音声インタラクション, インタラクション2019
SottoVoce: An Ultrasound Imaging-Based Silent Speech Interaction Using Deep Neural Networks, ACM CHI 2019
著者:暦本 純一(東大/ソニーCSL),木村 直紀,河野 通就(東大)
Naoki Kimura, Michinari Kono, Jun Rekimoto

本論文は、超音波エコー映像を用いて、利用者の無発声音声(実際に声帯を振動させずに発話のときと同様に口や舌を動かしたときに、その発話内容を認識する音声)を検出するdeep learningと組み合わせたシステムを提案します。従来では、無発声音声を検出する場合、話者の口唇や顔全体の映像をカメラで撮影する方式や、筋電図(EMG)によって口腔に近い筋肉の動きを推定する方式などが研究されてきましたが、本アプローチは、超音波イメージングによる無発声音声認識を採用します。
本提案は、顎の下側に取り付けられた超音波イメージングプローブによって口腔内の状況を計測し、観察される口腔内の情報からニューラルネットワークを用いて音響特徴を生成します。ニューラルネットワークは超音波画像の列を音響特徴ベクトルに変換します。この処理を画像系列に順次適用して、音響特徴ベクトルの列を生成します。最後に、音響特徴ベクトルの列をGriffin Lim手法により音声波形に復元し、オーディオスピーカから再生することで音声合成として無発声音声を出力します。
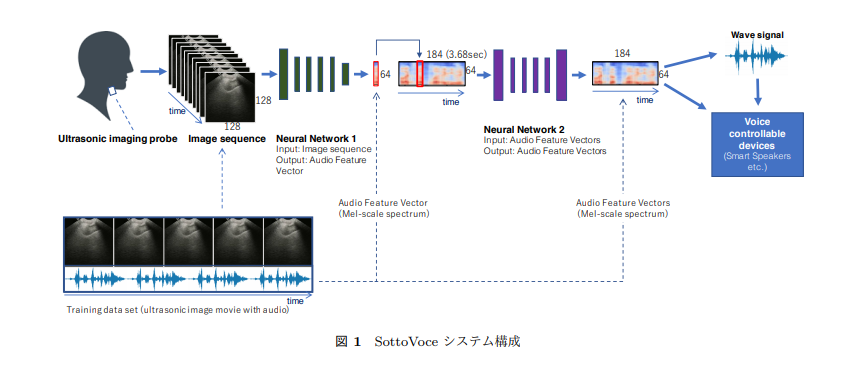
この出力結果を用いて、生成した音声合成からAmazon Echoなどのスマートスピーカ(無改造)を制御できるかを実験し、結果、制御できることも実証しました。これにより、人間とコンピュータが緊密に連携した種々のインタラクションが可能になり、また、咽頭の障害、声帯機能障害、高齢による発声困難者に対して、声によるコミュニケーションを取り戻すための支援技術に発展できると考えています。
本手法を用いれば、新しいウェアラブルコンピュータのフォームファクタが可能になります。顎下の超音波プローブと、骨伝導性イヤホンまたはオープンエアイヤホンを組み合わせたシステムです。これを用いると、街を歩きながらでも無発声音声を駆使してコンピュータを制御し対話することを可能にします。

本手法を用いることで、利用者側でも口パクを調整してうまく音声になるように歩み寄る傾向がありました。これは、ニューラルネットが学習しているだけでなく、ニューラルネットによって外在化されたフィードバックを通じて、人間側も学習していることになります。これは、人間とAIとが密接に一体化した新しいインタラクションの方向を示しているとも言え、「人間とAIの統合(Human-AI Integration)」と呼んでいます。今回のような無発声発話だけではなく、楽器の習得や語学習得、スポーツなど、様々な人間の技能習得プロセスに展開可能だと考えています。
3 口にくわえたマウスピース型静電容量センサから舌の動きを検出し無発声音声や舌ジェスチャを認識するサイレントスピーチシステム「TongueBoard」
Googleの研究チームは、口にくわえたマウスピース型静電容量センサから口腔内の舌の動きを検出し、無発声音声や舌ジェスチャを認識するシステム「TongueBoard」を発表しました。
論文:TongueBoard: An Oral Interface for Subtle Input
著者:Richard Li, Jason Wu, Thad Starner(Google Research & Machine IntelligenceMountain View, CA, USA)

本論文は、マウスピース型の静電容量センサを用いて、口腔内の静電容量を計測し舌の動きから無発声音声と舌のジェスチャを認識するデバイスを提案します。
デバイスは、言語療法で活用するための市販品SmartPalate – CompleteSpeechを使用します。SmartPalateは、124の静電容量式タッチセンサで構築されており、舌の位置を正確に捉えることができるデバイスです。具体的には、取得した静電容量値データをDataLinkで処理し、標準のUSBケーブルを介してラップトップまたはスマートフォンに送信、口腔内の視覚的表現に変換します。これら検出した舌の動きを分類し、語彙やジェスチャと結び付けることでコンピュータとやり取りをします。

単語レベルの無発声音声分類および舌スワイプ検出のために、support vector machine (SVM)を用いて分類します。実験では、アプリケーション入力用の21単語と9つの舌ジェスチャを持つサイレントスピーチインタフェースを構築しました。これにより、声を出した時と同じ音声入力を無音で行うことができます。デモ動画では、スマートフォンでカレンダーの予定を追加したり、スマートグラスと組み合わせて歩行しながらテキストメッセージを送信したりしている様子を確認することができます。
4 機械学習を用いて内部的に発した言葉(実際には声を出していない言葉)を読み取るサイレント音声認識技術「AlterEgo」
MIT(マサチューセッツ工科大学)の研究者は、内部的に発した言葉(実際には声を出していない言葉)を読み取るサイレント音声認識技術「AlterEgo」を発表しました。
論文:AlterEgo: A Personalized Wearable Silent Speech Interface
Arnav Kapur, Shreyas Kapur, Pattie Maes(MIT Media Lab)

本技術は、実際に声を出していない言葉を読み取る内部音声認識デバイスを提案します。口元に密着するウェアラブル装置を使用し、装置に整備された4つの電極からユーザの顎や顔の神経筋信号を読み取ることで言葉を予想します。人には検出できない内部の微妙な動きを検出します。
単語と結びつける推定には、訓練された機械学習システムを用いており、ニューラルネットワークを使用して、特定の神経筋信号と特定の単語との相関関係を見出します。実験では、約92%の精度で正しく認識することができたと報告します。
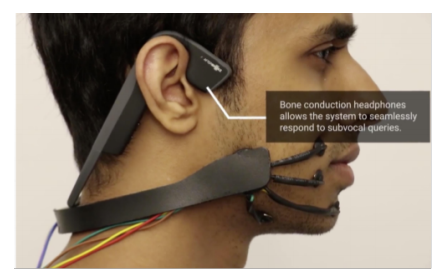
また、骨伝導ヘッドフォンと一体になっており、出力と入力を同時に静かな中で行うことも可能にします。これら機能を利用した実験が紹介されます。それは、チェスをプレイ中に相手の動きを静かに報告し、コンピュータが推奨する回答を静かに受け取って指すというものです。静かにマシーンに伝え、マシーンが手を考えユーザに骨伝導で伝えると。
また、デモ映像では、「時間は?」→「10:43AM」と現在の時間を聞いて受け取ったり、食品売り場にて3つの商品それぞれの金額を入力していき合計金額を受け取ったりしています。
5 脳活動から声道の動きをシミュレートし音声合成(本人の声に近似)を生成する機械学習を用いたブレインマシンインタフェース
UCSF Weill Institute for Neuroscienceによる研究チームは、脳活動の記録から音声合成を生成する機械学習を用いたブレインマシンインタフェースを発表しました。
論文:Speech synthesis from neural decoding of spoken sentences
著者:Gopala K. Anumanchipalli, Josh Chartier & Edward F. Chang (UCSF Weill Institute for Neuroscience)

本論文は、脳の活動を使って声道(喉頭、咽頭、口腔、鼻腔など)の動きをシミュレートし制御することによって合成音声を生成するブレインマシンインタフェースを提案します。
人間は、脳からの指示により約100の筋肉に働きかけ、唇、顎、舌、喉などを動かし続け、息を吹き込むことで音を生成します。本提案では、音声がどのように聞こえるかによってではなく、声道の物理的運動(調音動作)が脳内でどのように調整されるのかを研究することで脳-音声合成を検証します。脳活動の記録は、UCSF Epilepsy Centerで治療を受ける5名のボランティアから測定します。電極を頭蓋内に埋め込み脳領域を記録します。

記録した脳活動から声道の動きをシミュレートするため、そして声道の動きを合成音声に変換するために、機械学習アルゴリズムによる2つのニューラルネットワークを活用します。本提案モデルを用いることで、脳活動から声道の動きを復元し、そこから本人の声に近似の合成音声への変換を可能にします。出力結果は、以下の動画で確認できます。