Max Planck Institute for Intelligent Systems(MPI-IS)による研究チームは、音声から顔アニメーションを生成するdeep learningを用いた手法「VOCA」を発表しました。
論文:VOCA: Capture, Learning, and Synthesis of 3D Speaking Styles
著者:Daniel Cudeiro, Timo Bolkart, Cassidy Laidlaw, Anurag Ranjan, Michael J. Black
所属:Max Planck Institute for Intelligent Systems
GitHub – TimoBolkart/voca: Voice Operated Character Animation
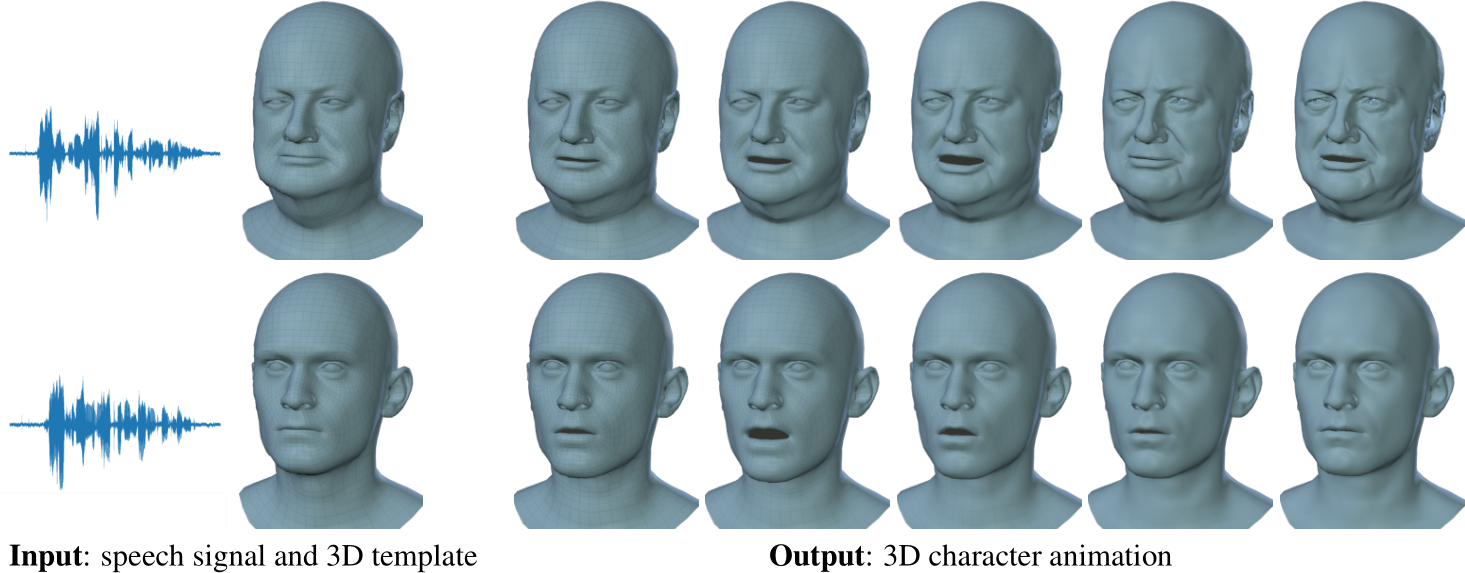
本論文は、音声で駆動するフェイスアニメーション・フレームワークを提案します。本提案は、音声信号と顔の動きを関連付けるために非線形回帰関数を用いてdeep learningで学習するアプローチです。これには大量の訓練データセットが必要ですので、4Dフェイススキャンの新しいデータセットを音声と共に収集しました。4Dスキャンは60fpsでキャプチャし、音声は3-5秒の英語で話された文章を収集します。このデータセットを「VOCASET」と呼んでいます。
ネットワークであるVOCA(Voice Operated Character Animation)では、音声信号を入力として受け取り、そこからDeepSpeech用いて特徴を抽出します。 エンコーダがオーディオ機能を低次元のembeddingに変換することを学習し、デコーダがこのembeddingを3D頂点にマッピングします。
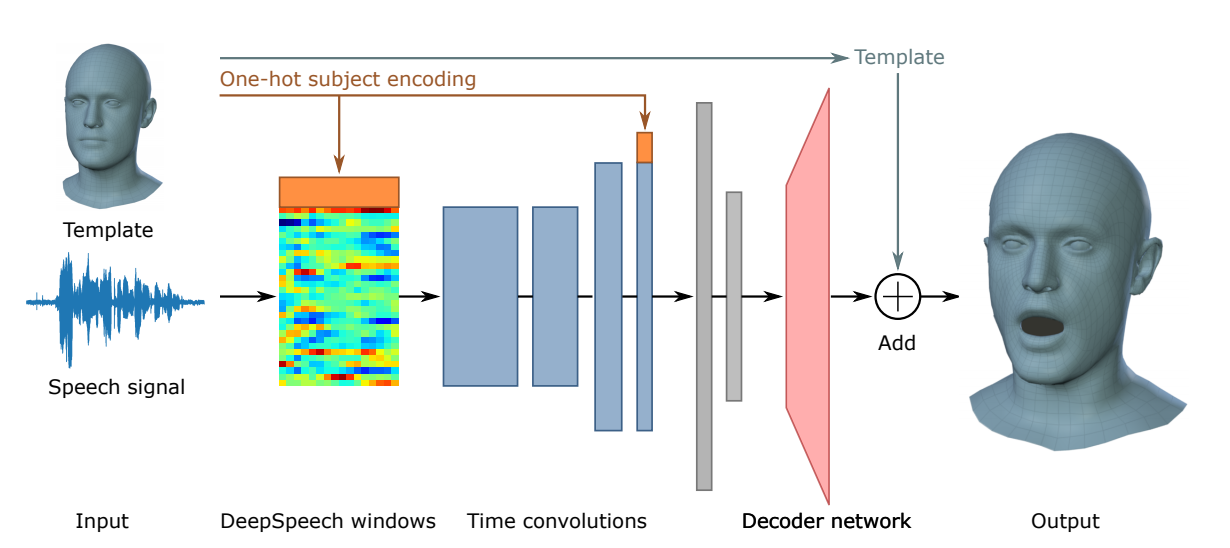
これにより、本モデルを使用すると任意の音声信号と静的キャラクタメッシュを入力に、自動的にリアルなキャラクタアニメーションを出力します。プロジェクトページからコードやモデル、データを使用できます。