東京大学と大阪大学の研究者たちは、Deep Learningにロボティクスの計算を組み合わせることで、複数のRGBカメラから人物の高精度なモーションキャプチャを行う技術を発表しました。
論文:Video Motion Capture from the Part Confidence Maps of Multi-Camera Images by Spatiotemporal Filtering Using the Human Skeletal Model
著者:Takuya Ohashi, Yosuke Ikegami, Kazuki Yamamoto, Wataru Takano, Yoshihiko Nakamura

本論文は、複数台のカメラ映像から屋内外、服装を問わずマーカレスでモーションキャプチャを行う技術を提案します。
本提案手法は、4台のカメラを同期させて、異なる方向から人物のビデオ映像を録画し、それぞれをDeep Learning処理して画像から関節の存在確率を推定します。そして、これらを参考にして、多自由度の人間骨格モデルを動かすことで、運動の3次元再構成を行います。
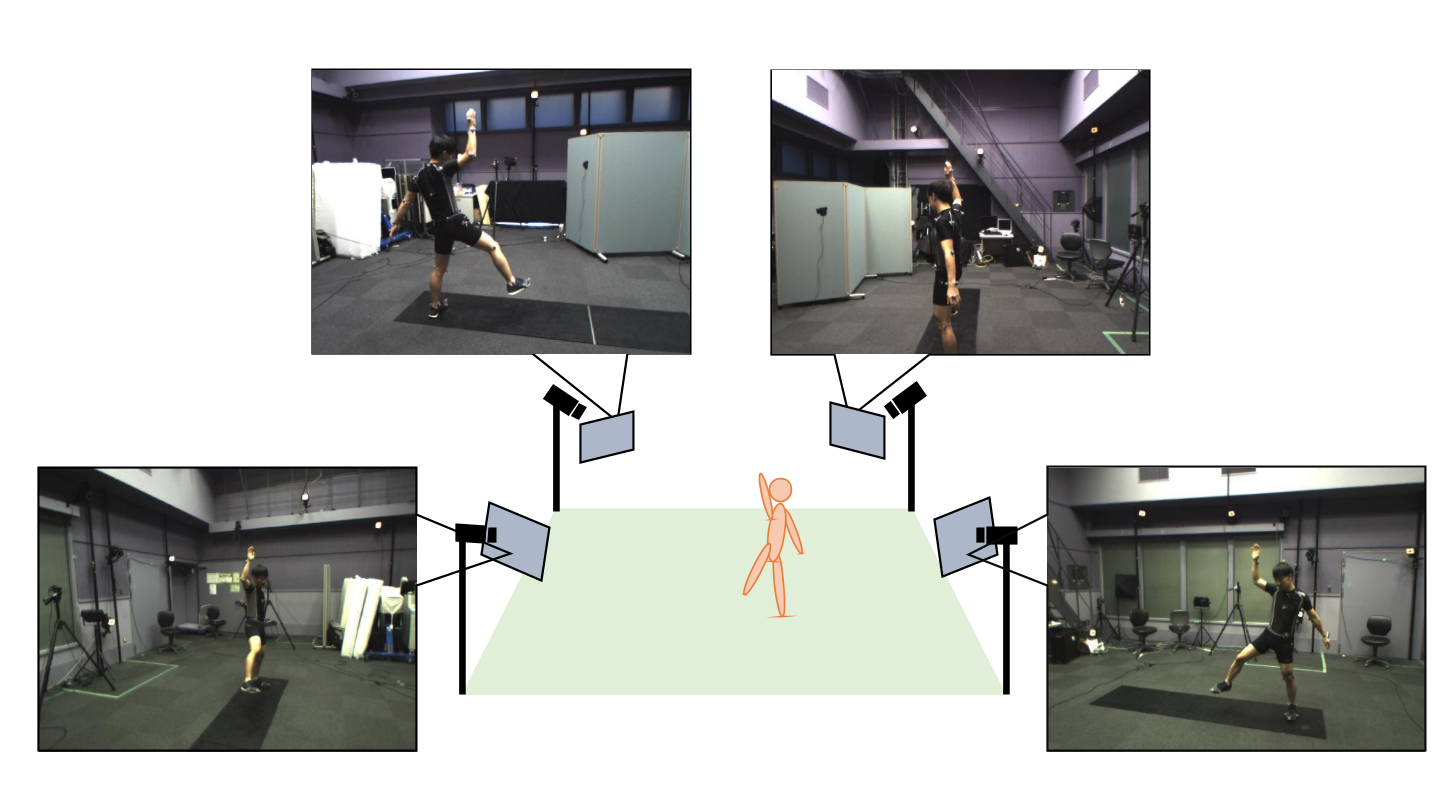
具体的に説明をすると、まず、各カメラから求めた存在確率を台数分組み合わせることで、関節が存在する空間上での位置を推定します。次に、骨格の構造と運動の連続性を考慮しつつ、これを目標位置とした、2回の逆運動学計算に落とし込みます。そして、この問題を繰り返し解くことによって、高精度のモーションキャプチャを実現します。

また、同グループは、上記手法にロボティクスの効率的計算法を組み合わせることで、骨格の運動だけでなく身体に働く力や筋の活動まで可視化するシステム「VMocap」を構築し、全てがリアルタイムで自動的に行えることを実証しました。
これにより、屋内、屋外、着ている服装を問わずビデオ映像だけからのリアルタイムの運動解析が可能になり、さらに、撮影から骨格の運動の3次元再構成、運動に必要な筋活動の推定と可視化までを、自動で効率的に行う技術を確立しました。
また、本研究は、先日開催された国際会議のIROS2018にて、Best Paper Award Finalistにも選ばれました。
追記(2019.1.17)
論文が公開されました。