Megviiなどの研究チームは、動画コンテンツの欠落部分を修復(補完)するdeep learningを用いた手法を発表しました。
論文:Video Inpainting by Jointly Learning Temporal Structure and Spatial Details
著者:Chuan Wang, Haibin Huang, Xiaoguang Han, Jue Wang
所属:Megvii (Face++) USA, Shenzhen Research Inst. of Big Data, CUHK (Shenzhen)

左が入力画像で、一番右が本物、右から2番目(CombCN)が本提案手法の出力結果
本論文は、ビデオフレームの規則的、またはランダムに欠けている領域を修復するための新しいデータ駆動型ビデオ修復法を提案します。
本提案手法は、各フレーム内の欠けている部分を埋めるだけでなく、連続するフレーム間の一貫性を保つことを可能にします。実行するために、2種類のサブネットワークを含むエンドツーエンドのdeep learningアーキテクチャを用います。時間構造予測に3D CNNを使用し、空間詳細復元に2D CNN(CombCN)を使用します。
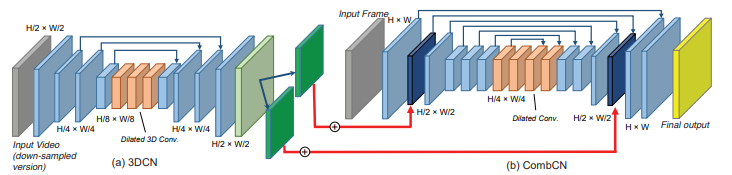
前者のサブネットワークは、ビデオを3Dボリュームとして扱い、入力ビデオのダウンサンプリングされたバージョンを3D CNNを使用して時間的構造を推定します。この出力を入力に、後者のサブネットワークにて、各フレームの詳細を修復し元解像度のビデオフレームを生成します。
これにより、動画内の欠落した領域を、連続するフレーム間の一貫性を保ちつつ、より自然に補完することを可能にします。