IWR Heidelberg Universityの研究者らは、ビデオ内の人物において、動きはそのままに人の外観だけを入れ替え可能なdeep learningを用いた手法を発表しました。
論文:Towards Learning a Realistic Rendering of Human Behavior
著者:Patrick Esser, Johannes Haux, Timo Milbich, Björn Ommer

上段が動きの元となるバットスイングの画像で、下段3つが本提案手法の出力結果
本論文は、モーションキャプチャデータとRGBビデオデータから訓練できる人間の行動の現実的な制御とレンダリングのための、データ駆動型機械学習フレームワークを提案します。
本提案手法は、動きの元となるインプットフレームと、それをコピーするターゲットの外観を入力に、deep learningを用いて生成します。フレームワークには、ポーズ推定アルゴリズムOpenPoseと運動モデルPFNetが統合されています。
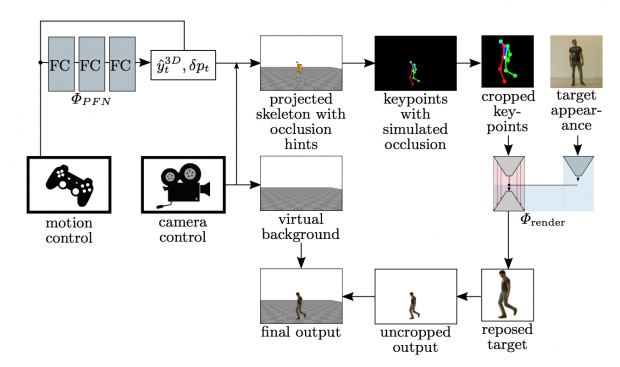
メソッドは、インプットフレームのキーポイントとバウンディングボックスへの変換を推定し、ターゲットの外観でレンダリング、再構築されたターゲットを元のインプットフレームの位置に合わせることで出力します。生成されたフレームは元のビデオ上に置かれます。
本フレームワークを活用することで、ビデオ内の人の動きを、別の人に置き換えて同じ動きをさせることが可能となります。