NVIDIA Researchの研究者らは、オブジェクト検出によるDeep learningの効率的な訓練のために、シーンの構造とコンテキストを考慮した合成データを生成するシステムを発表しました。
論文:Structured Domain Randomization: Bridging the Reality Gap by Context-Aware Synthetic Data
著者:Aayush Prakash, Eric Cameracci, Shaad Boochoon, Gavriel State, Mark Brophy, Omer Shapira, David Acuna, Stan Birchfield

オブジェクト検出のためのDeep learningを訓練するには、膨大な量のラベル付き訓練データが必要になりますが、手作業で訓練データにラベリングする作業は面倒で時間もかかります。
そこで、本論文では、訓練するための合成データを生成するStructured Domain Randomization(SDR)という手法によるシステムを提案します。実データではなく、シーンの構造とコンテキストを考慮した合成データで訓練することで効率的な学習を行います。
SDRによって生成された画像は、実際の画像上の物体検出のような知覚タスクのためにニューラルネットワークを訓練するために使用することができます。これらの合成データで使用するレーン、車、歩行者、道路標識、歩道などのオブジェクトは、位置、テクスチャ、形状、色、照明パラメータなどをランダム化することで、多様な合成シーンを生成することを可能にします。
本提案手法で生成した合成データによる訓練結果は、実データに匹敵する結果を報告します。
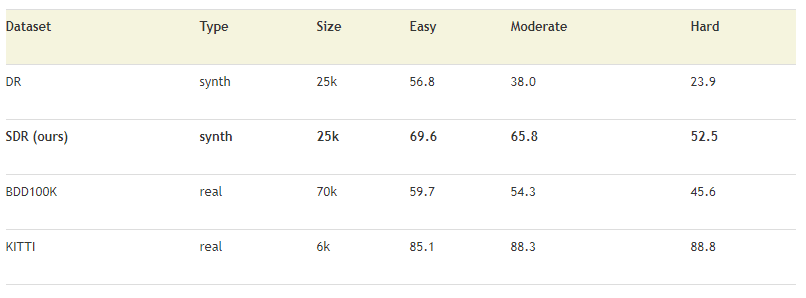
上図では、合成データ(DR、SDR)と実データ(BDD100K、KITTI)の比較を表にしています。SDRは、KITTIには及ばないもののBDD100Kよりかは優れていることを実証しました。さらに、KITTIとSDRを組み合わせたデータは、実際のKITTI単独よりも優れていることも実証しました。