UCSF Weill Institute for Neuroscienceによる研究チームは、脳活動の記録から音声合成を生成する機械学習を用いたブレインマシンインタフェースを発表しました。
論文:Speech synthesis from neural decoding of spoken sentences
著者:Gopala K. Anumanchipalli, Josh Chartier & Edward F. Chang
所属:UCSF Weill Institute for Neuroscience
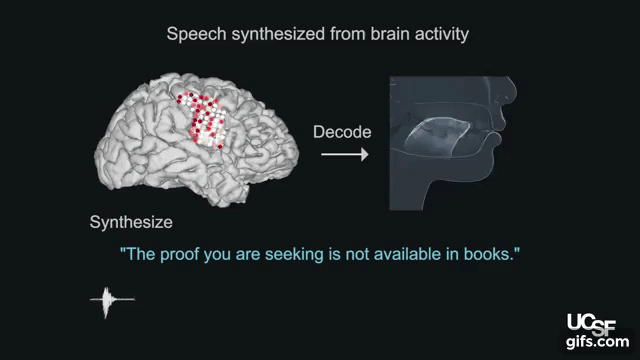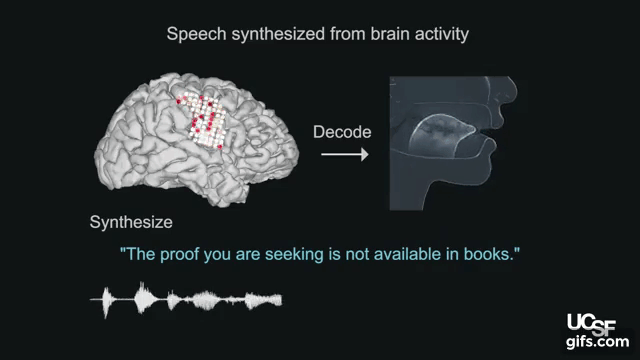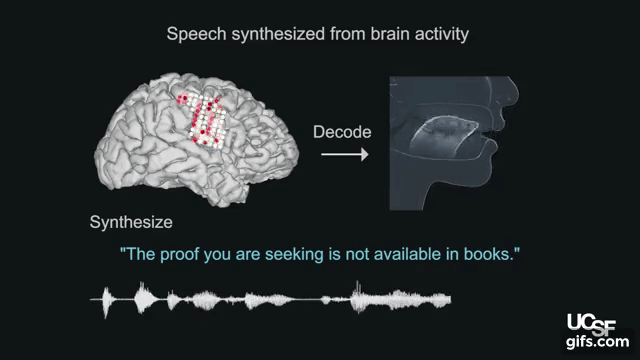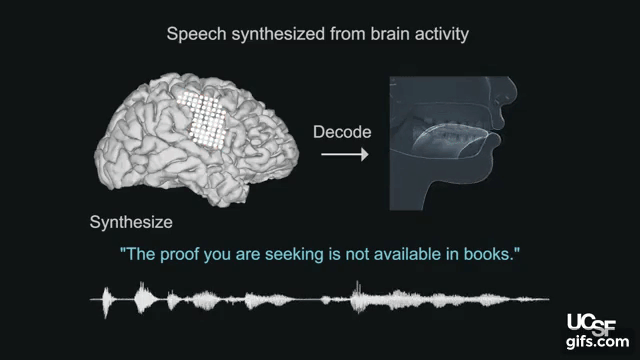
本論文は、脳の活動を使って声道(喉頭、咽頭、口腔、鼻腔など)の動きをシミュレートし制御することによって合成音声を生成するブレインマシンインタフェースを提案します。
人間は、脳からの指示により約100の筋肉に働きかけ、唇、顎、舌、喉などを動かし続け、息を吹き込むことで音を生成します。本提案では、音声がどのように聞こえるかによってではなく、声道の物理的運動(調音動作)が脳内でどのように調整されるのかを研究することで脳-音声合成を検証します。脳活動の記録は、UCSF Epilepsy Centerで治療を受ける5名のボランティアから測定します。電極を頭蓋内に埋め込み脳領域を記録します。

記録した脳活動から声道の動きをシミュレートするため、そして声道の動きを合成音声に変換するために、機械学習アルゴリズムによる2つのニューラルネットワークを活用します。本提案モデルを用いることで、脳活動から声道の動きを復元し、そこから本人の声に近似の合成音声への変換を可能にします。出力結果は、以下の動画で確認できます。