アストン大学や南カリフォルニア大学などの研究チームは、仮想キャラクタにおいて、発声時の呼吸(息継ぎ)を再現するリアルタイム制御システムを発表しました。
論文:Speech Breathing in Virtual Humans: An Interactive Model and EmpiricalStudy
著者:Ulysses Bernardet, Sin-hwa Kang, Andrew Feng, Steve DiPaola,Ari Shapiro
所属:Aston University, University of Southern California, Simon Fraser University
本論文は、仮想キャラクタに、発話においての息継ぎ時の呼吸を生成する動的音声呼吸システムを提案します。人間が発声する場合も、発話の間に息継ぎのように呼吸を入れます。本提案は、そんな呼吸を音声合成時にも考慮し生成することで、より仮想キャラクタにリアリズムを付与するアプローチを行います。
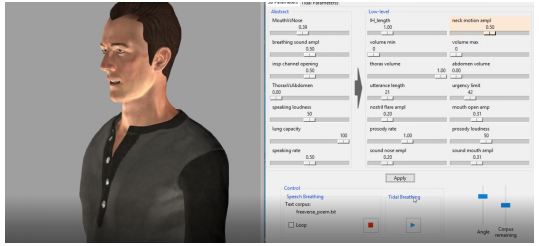
音声呼吸をシミュレートするためのモデルは、肺の容量、話す声の大きさ、口や鼻の呼吸、その他の要因に基づいて音声合成に追加されます。具体的には、音声合成を生成・制御する音声パラメータ(発話速度や音量など)と組み合わせて、呼吸を制御するパラメータモデルを作成します。モデルは、音(音声合成と呼吸)に加えて、形状(胸部、腹部、頭、鼻孔、口)の動きを生成します。
呼吸モデルには、吸気(息を吸い込むこと)と呼気(鼻や口から吐く息)2つのプロセスがコアにあります。リアルタイムに変更できるパラメータ制御システムは、それぞれ独立したパラメータに分かれており、肺活量や発声速度、発話の長さといった呼吸に影響する要因がパラメータ化されています。他にも鼻で呼気する、口で呼気するも調整できます。
これにより、仮想キャラクタをデザインするにあたり、Text-To-Speech (TTS)による音声合成に呼吸音および呼吸運動を併用することができ、より自然でリアルな表現ができるとします。デモ動画で、出力結果を確認することができます。