東京大学とソニーコンピュータサイエンス研究所による研究チームは、 声を出すことなく口パク動作を行うだけで発話内容を認識する無発声音声を、超音波エコー映像とdeep learningを組み合わせて検出するシステム「SottoVoce (ソット・ヴォーチェ、音楽用語で 「ささやくように」)」を発表しました。
論文:SottoVoce: 超音波画像と深層学習による無発声音声インタラクション, インタラクション2019
SottoVoce: An Ultrasound Imaging-Based Silent Speech Interaction Using Deep Neural Networks, ACM CHI 2019
著者:暦本 純一(東大/ソニーCSL),木村 直紀,河野 通就(東大)
Naoki Kimura, Michinari Kono, Jun Rekimoto

本論文は、超音波エコー映像を用いて、利用者の無発声音声(実際に声帯を振動させずに発話のときと同様に口や舌を動かしたときに、その発話内容を認識する音声)を検出するdeep learningと組み合わせたシステムを提案します。従来では、無発声音声を検出する場合、話者の口唇や顔全体の映像をカメラで撮影する方式や、筋電図(EMG)によって口腔に近い筋肉の動きを推定する方式などが研究されてきましたが、本アプローチは、超音波イメージングによる無発声音声認識を採用します。
本提案は、顎の下側に取り付けられた超音波イメージングプローブによって口腔内の状況を計測し、観察される口腔内の情報からニューラルネットワークを用いて音響特徴を生成します。ニューラルネットワークは超音波画像の列を音響特徴ベクトルに変換します。この処理を画像系列に順次適用して、音響特徴ベクトルの列を生成します。最後に、音響特徴ベクトルの列をGriffin Lim手法により音声波形に復元し、オーディオスピーカから再生することで音声合成として無発声音声を出力します。
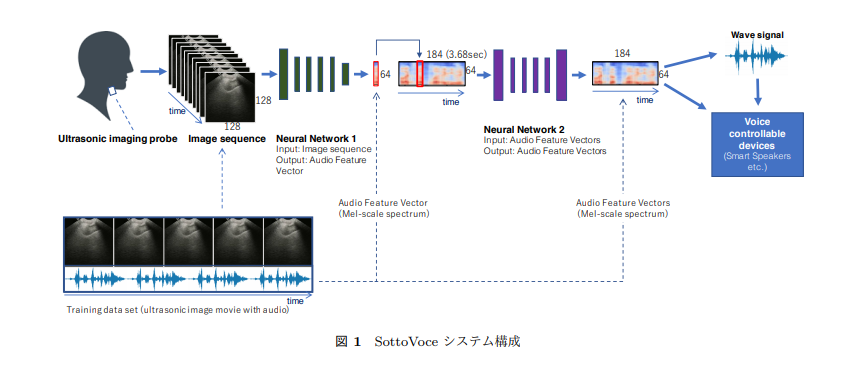
この出力結果を用いて、生成した音声合成からAmazon Echoなどのスマートスピーカ(無改造)を制御できるかを実験し、結果、制御できることも実証しました。これにより、人間とコンピュータが緊密に連携した種々のインタラクションが可能になり、また、咽頭の障害、声帯機能障害、高齢による発声困難者に対して、声によるコミュニケーションを取り戻すための支援技術に発展できると考えています。
本手法を用いれば、新しいウェアラブルコンピュータのフォームファクタが可能になります。顎下の超音波プローブと、骨伝導性イヤホンまたはオープンエアイヤホンを組み合わせたシステムです。これを用いると、街を歩きながらでも無発声音声を駆使してコンピュータを制御し対話することを可能にします。

本手法を用いることで、利用者側でも口パクを調整してうまく音声になるように歩み寄る傾向がありました。これは、ニューラルネットが学習しているだけでなく、ニューラルネットによって外在化されたフィードバックを通じて、人間側も学習していることになります。これは、人間とAIとが密接に一体化した新しいインタラクションの方向を示しているとも言え、「人間とAIの統合(Human-AI Integration)」と呼んでいます。今回のような無発声発話だけではなく、楽器の習得や語学習得、スポーツなど、様々な人間の技能習得プロセスに展開可能だと考えています。