Microsoft Researchの研究者は、「息を吸いながら」喋る時に出る非常に小さな音を利用した音声入力インタフェースデバイス「SilentVoice」を発表しました。
論文:SilentVoice: Unnoticeable Voice Input by Ingressive Speech
著者:Masaaki FUKUMOTO
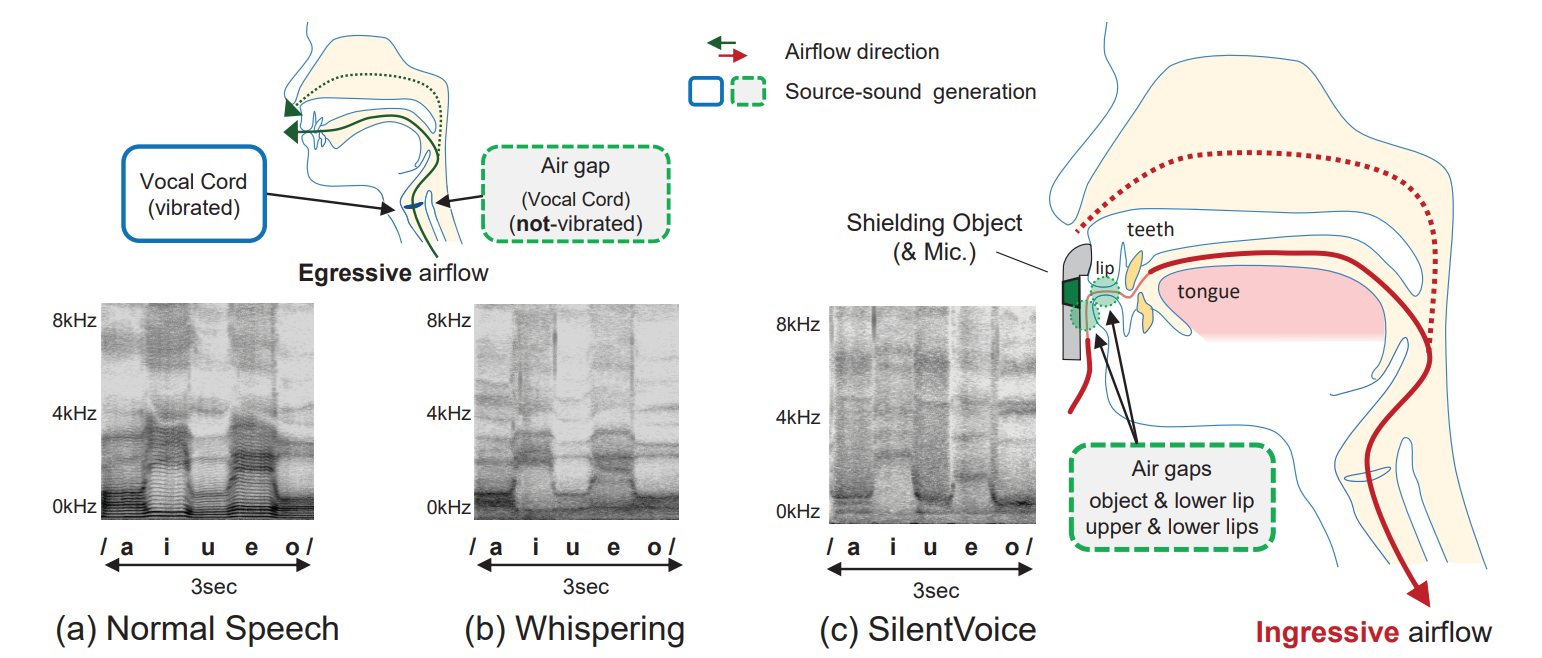
本論文は、ingressive speech(吸気発話)法を用いて、非常に小さい音(漏洩音量39dB未満)での音声入力を可能にするシステムを提案しています。静かな場所だけではなく、80dBの騒音環境下においても周囲に気づかれずに音声入力が行えます。
本提案手法は、我々の通常音声やささやき声のように、息を吐きながら喋るのとは逆に、息を「吸いながら」発話動作をした時に出る僅かな音声を用いるのが特徴です(通常は使われない喋り方なので少し慣れが必要ですが、15分程度で喋れるようになるとのことです(練習方法は論文末尾に掲載))。吸気方向の気流を用いた場合「ポップノイズ(息吹きノイズ)」が発生しないため、マイクを口の正面直前(2mm以下)に置くことができ、高いS/N比で音声を捉えることが可能になります。また、マイクロホンのDC出力を用いて気流の方向を検出することで、通常発話とコマンド音声の分離が簡単に行える(精度98.8%)ため、音声アシスタントとの対話において、会話の先頭に「おまじない」の言葉をつける必要もなくなります。
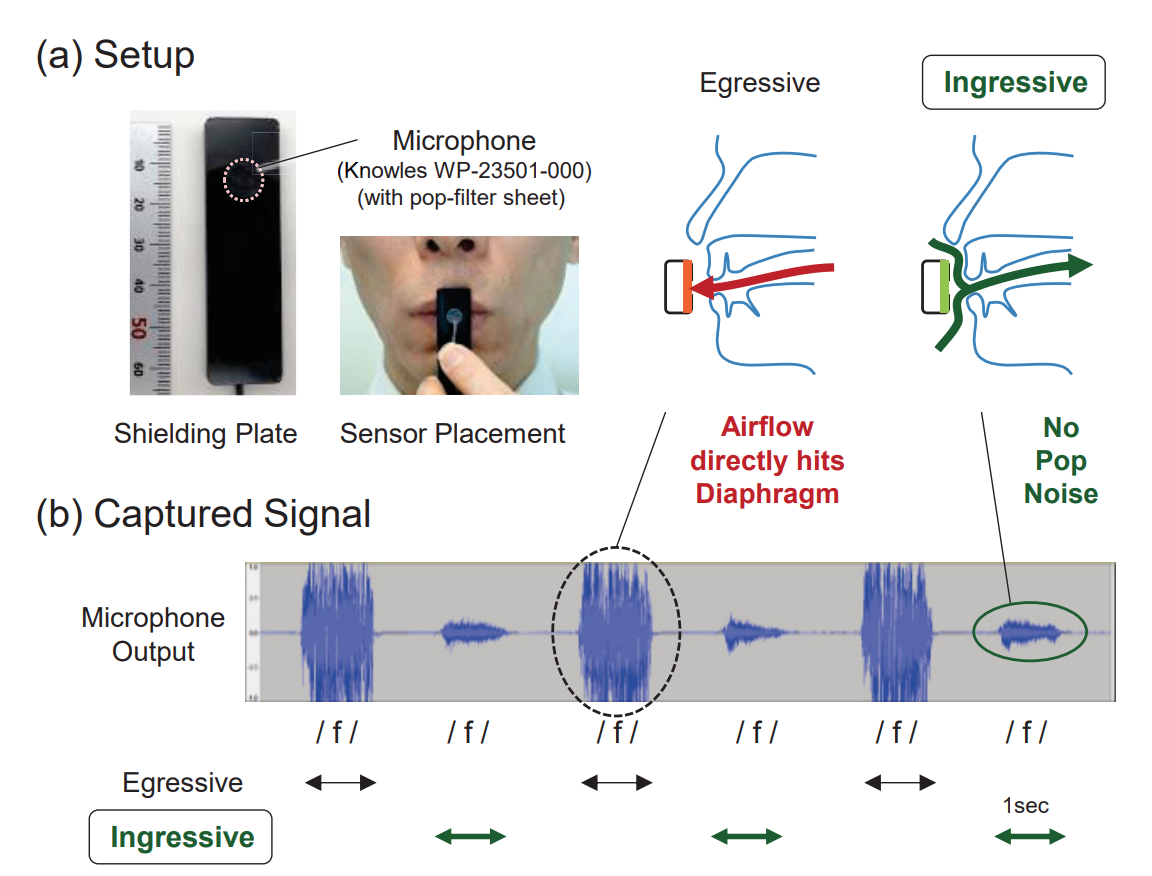
漏洩音量が39dB未満と非常に小さいため、静かな場所でも周囲に迷惑をかけることなく音声入力できます。また、マイクが口に非常に近い(超近接設置)ことで大きなノイズキャンセル効果が生まれるため、騒々しい環境(80dB)での使用も可能です。本提案手法は Bluetooth Headset などの機器に簡単に組み込むことが可能なほか、将来的には歯に埋め込むインプラント形式の人体拡張デバイスとしての使用もイメージしています。(下図右下)
