SenseTime Researchと南洋理工大学の研究者らは、ビデオにおける人物の顔の表情や動きを再構築する機械学習を用いた手法「ReenactGAN」を発表しました。
論文:ReenactGAN: Learning to Reenact Faces via Boundary Transfer
著者:Wayne Wu, Yunxuan Zhang, Cheng Li, Chen Qian, Chen Change Loy
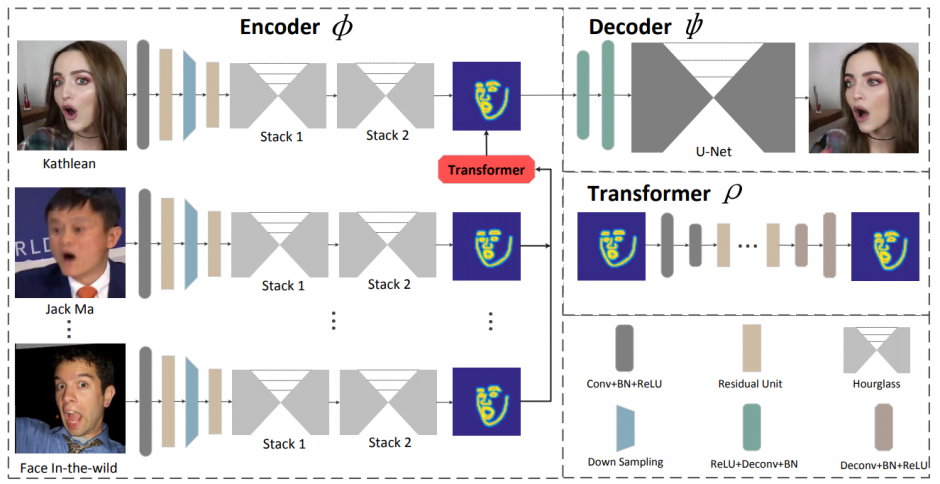
本稿は、映像内のターゲットである人物へ、別の人物の顔の表情や動きを転送する機械学習フレームワークを提案します。
本提案手法は、既存と違い、最初にすべての顔を境界の潜在空間にマップし、それを各特定の人物にデコードします。アーキテクチャは、全てにおいてフィードフォワードネットワークであり、潜在空間上でimage-to-imageの変換を直接行います。