東京大学の研究者らは、一人称視点ビデオにおける注視を予測し可視化するための機械学習モデルを発表しました。
論文:Predicting Gaze in Egocentric Video by Learning Task-dependent Attention Transition
著者:Yifei Huang, Minjie Cai, Zhenqiang Li, Yoichi Sato

本稿は、一人称視点ビデオにおいて、タスクに依存する視線固定の時間的変化のパターンを探索することによって、注視予測のための計算モデルを提案します。
人の視線は、各固定の間に同じ対象物上に留まる傾向があり、大きな頭の動きと共に大きな視線シフトがほとんどの場合生じること、そして、注視領域のパターンは、実行されるタスクに依存し、データから学習することができると考えます。本提案手法は、主に3つのモジュールで構成されます。
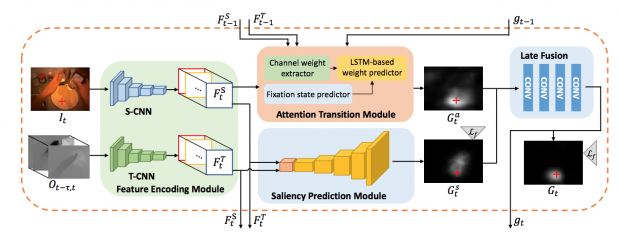
第1のモジュールは、ビデオフレームからCNN(Convolutional Neural Network)を用いて、直接顕著性マップ(SP)を生成します。第2のモジュールは、頭部の動きに基づいて、視線固定の時間的変化からRNN(Recurrent Neural Network)により各フレームのための注意マップ(AT)を生成します。
最後のモジュールは、最初の2つのモジュールから得た顕著性マップと注意マップを融合し、最終的な注視マップをFCN (Fully Convolutional Network) に基づいて生成します。これらのことで、一人称視点ビデオにおいて、より正確な注視予測を実証にします。