Googleによる研究チームは、言語障害者の音声をテキスト変換なしに直接流暢な合成音声に変換する機械学習を用いた手法「Parrotron」を発表しました。
Fadi Biadsy, Ron J. Weiss, Pedro J. Moreno, Dimitri Kanvesky, Ye Jia
Google
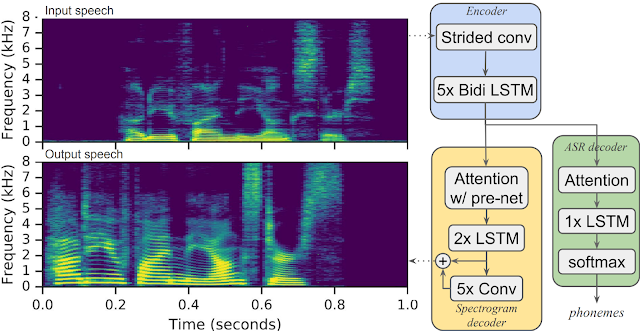
言語障害で悩む人たちは世界中に何百万人います。言語障害者にとって、音声認識系のデバイスを活用することは困難であり、言い換えるとデバイスを作るエンジニアたちの課題です。そこで本論文では、言語障害などで非定型の発話パターンを使用しているユーザの音声を、流暢な合成音声に変換するアプローチを提案します。
それは唇の動きなどの視覚的な合図ではなく、音声信号のみを考慮し、入出力音声ペアを使用して2段階で訓練するエンドツーエンドの機械学習アーキテクチャです。これにより、言語障害のある人でも音声アシスタントに対して、ワードエラー率の大幅軽減を可能にし利用できます。また本アーキテクチャは、音声信号からの分析で行うため、その他非定型の発話パターンを持つ人々たち、例えばALS、聴覚障害、筋ジストロフィーなどへの有効性も実証しました。ロシア語環境で育ち、若い頃から聴覚障害のあるDimitri Kanevsky氏、ロシア語ベースの非ネイティブ英語話者でエラー率89%から32%に減少を報告。以下の音声で比較できます。最初がオリジナルで、後が変換後の合成音声。