Pinscreen、南カリフォルニア大学、USC Institute for Creative Technologiesの研究者らは、1枚の入力顔画像から、モバイル端末に3Dアバターを作成し、自身の表情を介して制御できるdeep learningモデル「paGAN(photoreal avatar GAN)」を発表しました。
論文:paGAN: Real-time Avatars Using Dynamic Textures
著者:Koki Nagano, Jaewoo Seo, Jun Xing, Lingyu Wei, Zimo Li, Shunsuke Saito, Aviral Agarwal, Jens Fursund, Hao Li

顔画像を入力に画像ベースの動的3Dアバターを生成しモバイル端末上でリアルタイムレンダリングしている様子
本論文は、条件付き敵対的生成ネットワーク(Conditional Generative Adversarial Networks)を用いて、モバイル端末でリアルタイムに制御可能な写実的なアバターを作成できるエンドツーエンドのdeep learningフレームワークを提案します。
本提案手法は、アップロードした単一の顔画像(ニュートラルポーズ)を入力に、3次元顔フィッティングを行い、ベースメッシュやGANの条件で使用される画像を抽出します。条件画像として、FACS(Facial Action Coding System)で制御可能な顔の表情付きテクスチャや法線画像などを用いることで、GANによる顔の表情合成を細部までコントロールできます。GANは、大規模な顔画像データセットで訓練されており、様々な人種や年齢に対応しています。
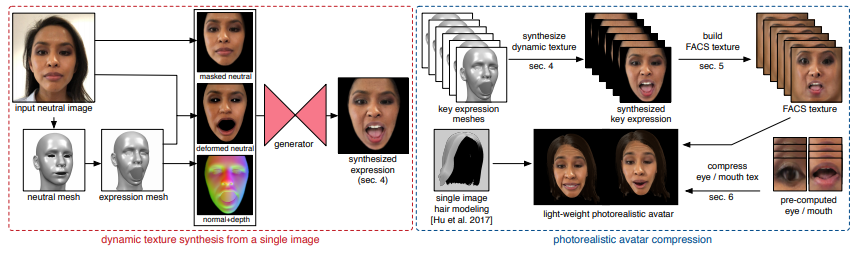
本システムの概要: (左)ニュートラルな顔画像に対して3次元顔フィッティングを行い、ベースメッシュやGANの条件で使用される画像を抽出する。GANを用いて、一枚画像からあらゆる顔の表情が合成できる。(右)左のGANを用いて、顔の表情、目線、口内をUVテクスチャとして事前計算し、圧縮されたモデルを用いることで、モバイルデバイス上でリアルタイムに制御可能なアバターを実現する。
ネットワークは、顔の表情だけでなく、入力画像からは見えない口の内部、視線方向も制御し、新しい顔画像を様々な視点から合成することができます。デスクトップ上でリアルタイムに動作する様子が動画内で確認できます。さらに、これらをモバイル端末上でリアルタイムに実行するために、表情のUVテクスチャを事前計算し、「圧縮モデル」に変換します。これにより、自身の表情を用いて、写実的なアバターをスマートフォン上でリアルタイムに操作することを可能にしています。
次のステップとして、横向き顔や、顔の遮蔽(メガネ、舌、手などによる)、顔への強い陰影を含む入力画像への対応が挙げられます。写実的なアバターを写真一枚から全自動で生成することができるため、ユーザーを取り込んだビデオゲーム、VR、Vtuberなどへの応用が期待されます。
本論文に関連したiphone向けのデモアプリがPinscreenからダウンロードできます。