独マックス・プランク情報科学研究所(Max Planck Institute for Informatics/MPI-Inf)、香港大学、スタンフォード大学の研究者らは、人の高品質な3Dモデルを必要とせずに、ユーザ制御下の写実的なリアルアバタを生成するconditional GAN(generative adversarial network)を用いた手法を発表しました。
論文:Neural Animation and Reenactment of Human Actor Videos
著者:Lingjie Liu, Weipeng Xu, Michael Zollhoefer, Hyeongwoo Kim, Florian Bernard, Marc Habermann, Wenping Wang, Christian Theobalt

本論文は、人間のフォトリアリスティックな3Dモデルを必要とせずに、ユーザ制御下の実際の人間に近いアニメーションを生成するconditional GANを用いた手法を提案します。
ターゲットとなる人の静止画を異なる視点からカメラでキャプチャし、3Dキャラクタモデルを作成します。単眼カメラからのモーションデータを使用して3Dキャラクタモデルを操縦します。
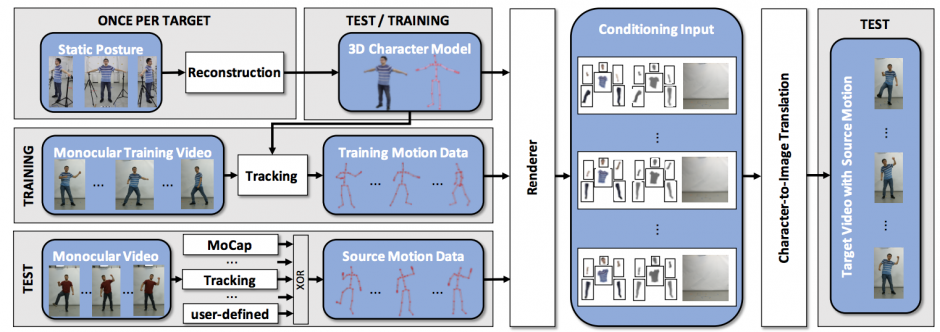
3Dキャラクタモデルを現実的な画像に変換するニューラルネットワークを訓練することで、最終的に、動きのある写実的な人物を生成します。以下の図は、キャラクタから画像に変換する概略図です。
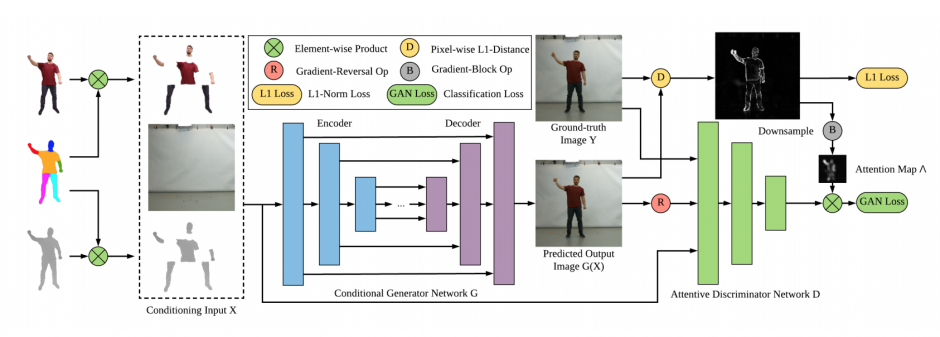
これらのことで、自分をベースとしたアバタを作成できるほか、別の人をベースにしたキャラクタも作成することを可能にします。

また、3Dモデルに基づく従来のレンダリング手法と比較して、制作コストを大幅に削減し、ユーザコントロール下のリアルなキャラクタを効率的に生成、演出することを可能にします。