Machine Learningを用いた論文2018を精選し一覧(60本程)にしました。Seamless Supporter Programに参加されている方は、完全版(100本程)をこちらより閲覧することができます。

本論文は、fMRIで測定した人間の脳活動のみから、その人が見ている画像を機械学習を用いて再構成する技術を提案します。本提案手法は、人間が見ている画像を、fMRIで測定した脳活動パターンのみで知覚内容を視覚化します。また、一度見た画像を記憶し、画像を見ていない状態から心の中でイメージする脳活動だけで再構成することも実証しました。
- 論文:Deep image reconstruction from human brain activity
- 著者:Guohua Shen, Tomoyasu Horikawa, Kei Majima, Yukiyasu Kamitani
- 所属:ATR(国際電気通信基礎技術研究所), 京都大学

本論文は、テキストによる説明文から画像を生成するGANを用いたアルゴリズムを提案します。例えば、黄色い体、黒い翼、短いくちばしの鳥といったキャプションをテキストで記述したとして、上画像のようなイメージを生成します。出力される画像は、コンピュータによってピクセルごとにゼロから作成されるため、この鳥が現実世界に実在するのではなくコンピュータが描画するイメージになります。
- 論文:AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks
- 著者:Tao Xu, Pengchuan Zhang, Qiuyuan Huang, Han Zhang, Zhe Gan4, Xiaolei Huang, Xiaodong He
- 所属:Microsoft Research, リーハイ大学, ラトガース大学, デューク大学
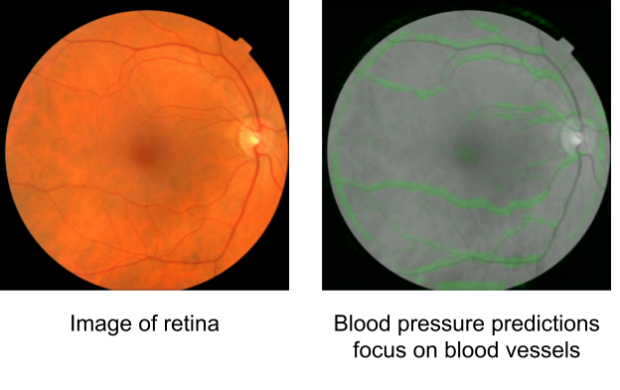
本論文は、目の網膜スキャンから機械学習を用いて心臓病を予測するコンピュータビジョンベースのアルゴリズムを提案します。コンピュータビジョン技術を用いて眼の網膜をスキャンすることで、画像から個人の年齢、性別、血圧、喫煙の有無などのデータを正確に推論することができます。
- 論文:Prediction of cardiovascular risk factors from retinal fundus photographs via deep learning
- 著者:Ryan Poplin, Avinash V. Varadarajan, Katy Blumer, Yun Liu, Michael V. McConnell, Greg S. Corrado, Lily Peng,Dale R. Webster
- 所属:Google Research, Verily
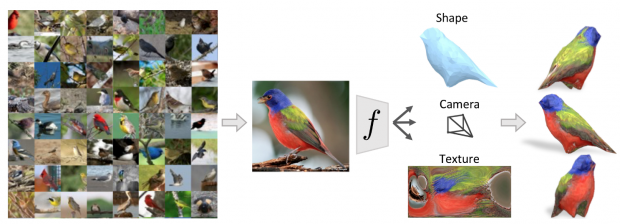
本論文は、3次元データに頼ることなく、CNN(Convolutional Neural Network)を用いて単一の画像から物体の3D構造を推定することを学ぶ計算モデルを提案します。単一の画像から物体の3D構造を推定する学習フレームワークです。
- 論文:Learning Category-Specific Mesh Reconstruction from Image Collections
- 著者:Angjoo Kanazawa,Shubham Tulsiani,Alexei A. Efros,Jitendra Malik
- 所属:UCバークレー

本論文は、画像に関する質問に回答し、その根拠となる説明をテキストで解説、さらに根拠となる箇所をビジュアル的にアノテーションすることで証拠も示すことができるニューラルネットワークモデルを提案します。上画像上段は、トッピングが多いホットドッグだから健康的な食事ではないとし、上画像下段は、様々な野菜が入っているから健康的な食事と判断しています。
- 論文:Multimodal Explanations: Justifying Decisions and Pointing to the Evidence
- 著者:Dong Huk Park, Lisa Anne Hendricks, Zeynep Akata, Anna Rohrbach, Bernt Schiele, Trevor Darrell, Marcus Rohrbach
- 所属:UCバークレー, アムステルダム大学, Max Planck Institute for Informatics, Facebook AI Research

本論文は、機械学習を用いて自然言語のテキストから色付きの3D形状を検索及び生成するエンドツーエンドのフレームワークを提案します。
- 論文:Text2Shape: Generating Shapes from Natural Language by Learning Joint Embeddings
- 著者:Kevin Chen, Christopher B. Choy, Manolis Savva, Angel X. Chang, Thomas Funkhouser, Silvio Savarese
- 所属:スタンフォード大学, プリンストン大学

本論文は、内部的に発した言葉(実際には声を出していない言葉)を読み取るサイレント音声認識技術「AlterEgo」を提案します。口元に密着するウェアラブル装置を使用し、装置に整備された4つの電極からユーザの顎や顔の神経筋信号を読み取ることで言葉を予想します。人には検出できない内部の微妙な動きを検出します。
- 論文:AlterEgo: A Personalized Wearable Silent Speech Interface
- 著者:Arnav Kapur, Shreyas Kapur, Pattie Maes
- 所属:MIT Media Lab

本論文は、仮想キャラクタのアクロバットな動きをよりリアルに再現する強化学習を用いた手法「DeepMimic」を提案します。提案手法は、強化学習フレームワークを用いて、ブレイクダンスや武道のようなアクロバットな動きもコンピュータアニメーションで自然な動きとして再現する手法です。フレームワークにキャラクタ、参照動作(基準動作)、タスク(目的の動き)を与えることで、ベースとなる参照動作を模倣しながらタスクを実行することを学習します。スキルを熟達するまで何度も訓練します。
- 論文:DeepMimic: Example-Guided Deep Reinforcement Learning of Physics-Based Character Skills
- 著者:Xue Bin Peng,Pieter Abbeel,Sergey Levine,Michiel van de Panne
- 所属:カリフォルニア大学バークレー校, ブリティッシュコロンビア大学
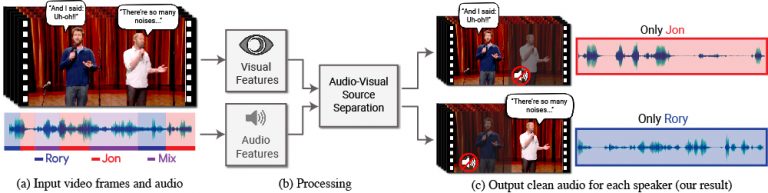
本論文は、Deep learningを用いて、複数の音から1人の音声だけを抜き出す視聴覚音声分離モデル「Looking to Listen at the Cocktail Party」を提案します。他の人の音声や背景の雑音などの混合音から単一の音声信号を分離するDeep learningを用いたモデルで、使用すると、特定の人の発話が強調され、他のすべての音声は抑制されたビデオを生成することができます。
- 論文:Looking to Listen at the Cocktail Party: A Speaker-Independent Audio-Visual Model for Speech Separation
- 著者:Ariel Ephrat, Inbar Mosseri, Oran Lang, Tali Dekel, Kevin Wilson, Avinatan Hassidim, William T. Freeman, Michael Rubinstein
- 所属:Google Research
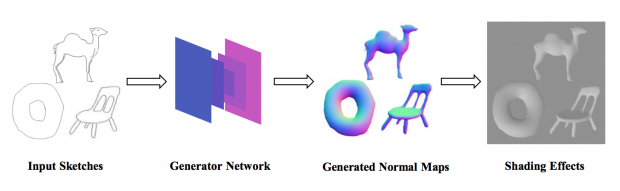
本論文は、手書きスケッチからリアルタイムに法線マッピング(ノーマルマッピング)を自動生成するGANを用いたインタラクティブシステムを提案します。ネットワークは、入力スケッチを法線マップに変換し、リアルタイムのスケッチ・ツー・ノーマルを実現します。
- 論文:Interactive Sketch-Based Normal Map Generation with Deep Neural Networks
- 著者:Wanchao Su, Dong Du, Xin Yang, Shizhe Zhou, Hongbo Fu
- 所属:香港城市大学, 中国科学技術大学, 大連理工大学, 湖南大学
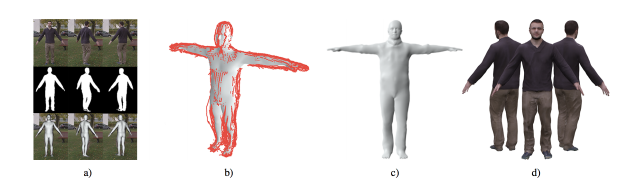
本論文は、1台の単眼カメラから3Dアバターを4.5mm精度で生成する機械学習を用いた手法を提案します。スマートフォンの既存カメラや、PCのウェブカメラを用いて、その前でぐるっと回るだけでスキャンされます。提案手法は、フレームを前景と背景に分類するCNNベースのビデオセグメンテーション方法を用いて人物を背景から分離し、SMPLモデルを使用してポーズを計算、シルエットを取り除き形状を最適化、テクスチャを計算しパーソナライズされたブレンドシェイプモデルを生成します。
- 論文:Video Based Reconstruction of 3D People Models
- 著者:Thiemo Alldieck, Marcus Magnor, Weipeng Xu, Christian Theobalt, Gerard Pons-Moll
- 所属:ブラウンシュヴァイク工科大学, Max Planck Institute for Informatics
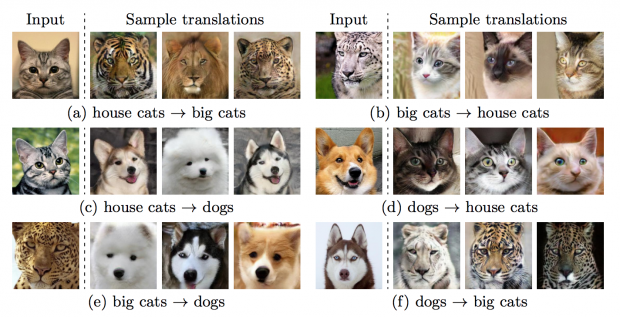
本論文は、1枚の画像を多様な画像に変換するGANを用いたフレームワーク「Multimodal Unsupervised Image-to-image Translation (MUNIT)」を提案します。上画像のように、猫を犬に変換したり、猫をトラやライオンに変換したり、1枚の画像から様々な画像を生成することを可能にします。
- 論文:Multimodal Unsupervised Image-to-Image Translation
- 著者:Xun Huang, Ming-Yu Liu, Serge Belongie, Jan Kautz
- 所属:コーネル大学, NVIDIA
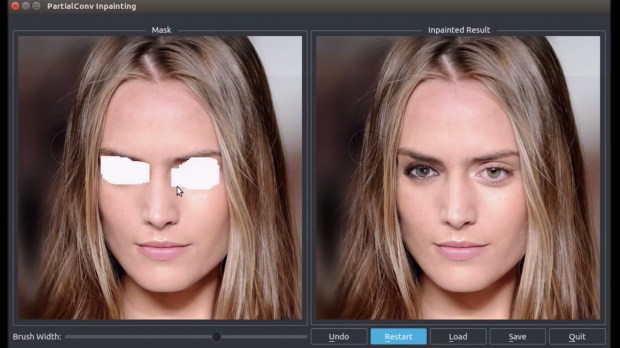
本論文は、画像内の一部を削除し、リアルに修復するDeep learningを用いた画像修復技術を提案します。画像内の修正したい箇所をマスクし、除去したあとを自然に見せる代替を生成し再構築します。多様な形状やサイズなどにも対応しており、またマスクが大きくなっても精度が急激に低下することなく実行することが可能です。
- 論文:Image Inpainting for Irregular Holes Using Partial Convolutions
- 著者:Guilin Liu, Fitsum A. Reda, Kevin J. Shih, Ting-Chun Wang, Andrew Tao, Bryan Catanzaro
- 所属:NVIDIA
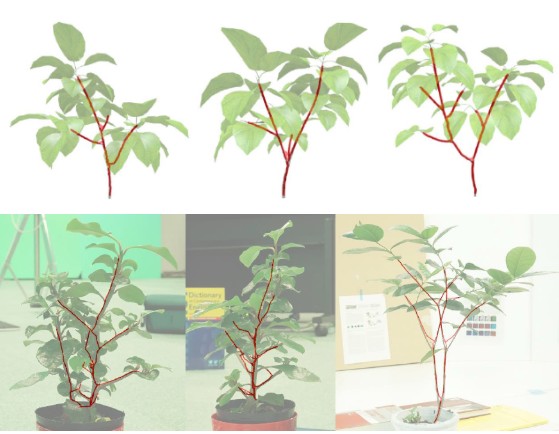
本論文は、植物を複数方向から撮影した画像から、植物の3次元「枝構造」を正確に再現する手法を提案します。Deep learningの技術を用いて、葉などに隠された枝の存在確率を推定し3次元復元することにより、見えない部分も含めた枝の構造を正確に再現します。具体的には、各画像(葉つきの植物画像)を画像変換により枝の存在確率を表す画像に変換し、これを使って三次元復元を行います。
- 論文:Probabilistic plant modeling via multi-view image-to-image translation
- 著者:Takahiro Isokane, Fumio Okura, Ayaka Ide, Yasuyuki Matsushita, Yasushi Yagi
- 所属:Osaka University, JST PRESTO

本論文は、機械学習を用いて露出が少ない状態で撮影された暗い写真(低光量画像)を修正するパイプラインを提案します。具体的には、FCN(Fully Convolutional Network)を用いて、色変換、デモザイク、ノイズリダクションなど、RAWデータの画像処理をエンド・ツー・エンドで学習します。
- 論文:Learning to See in the Dark
- 著者:Chen Chen, Qifeng Chen, Jia Xu, Vladlen Koltun
- 所属:イリノイ大学アーバナ・シャンペーン校, Intel Labs

本論文は、1台の単眼カメラで撮影した映像を入力に、人間のポーズから着用する衣服までを3D再構築するCNNを用いたマーカレスパフォーマンスキャプチャ技術「MonoPerfCap」を提案します。本提案手法を用いることで、人の姿勢推定だけでなく、着用する衣服などの動きも再構築することができ、自由な視点でレンダリングすることを可能にします。
- 論文:MonoPerfCap: Human Performance Capture from Monocular Video
- 著者:Weipeng Xu, Avishek Chatterjee, Michael Zollhoefer, Helge Rhodin, Dushyant Mehta, Hans-Peter Seidel, Christian Theobalt
- 所属:Max Planck Institute for Informatics, スイス連邦工科大学ローザンヌ校(EPFL)
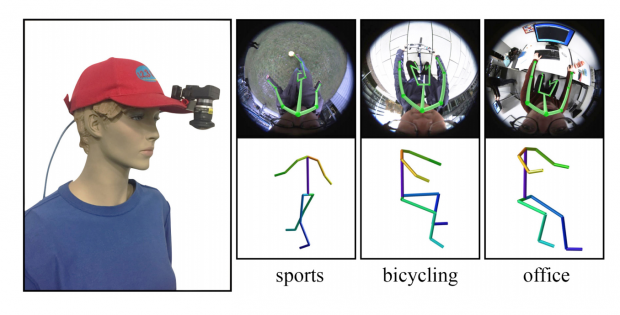
本論文は、帽子に1台の魚眼カメラを装着し自身の体をリアルタイムに3D姿勢推定するCNNベースのアプローチ「Mo2Cap2」を提案します。標準の野球帽の縁に取り付けられた単一の魚眼カメラから撮影し、顔から下の身体部分の姿勢推定を可能にします。
- 論文:Mo2Cap2: Real-time Mobile 3D Motion Capture with a Cap-mounted Fisheye Camera
- 著者:Weipeng Xu, Avishek Chatterjee, Michael Zollhoefer, Helge Rhodin, Pascal Fua, Hans-Peter Seidel, Christian Theobalt
- 所属:Max Planck Institute for Informatics, Saarland Informatics Campus, Stanford University, EPFL

本論文は、2枚の画像から類似したポイントを抽出し対応付けするスパース推定フレームワーク「Neural Best-Buddies」を提案します。2枚のペア画像から重要な特徴だけを検索し抽出、共通の外観を持たない画像間の対応付けを可能にする手法です。これにより、結合画像の作成、自動画像モーフィングなど、外見が異なるオブジェクト同士の自然なハイブリッド画像作成を可能にします。
- 論文:Neural Best-Buddies: Sparse Cross-Domain Correspondence
- 著者:Kfir Aberman, Jing Liao, Mingyi Shi, Dani Lischinski, Baoquan Chen, Daniel Cohen-Or
- 所属:AICFVE Beijing Film Academy, Tel-Aviv University, Microsoft Research Asia, Shandong University, Hebrew University of Jerusalem, Peking University
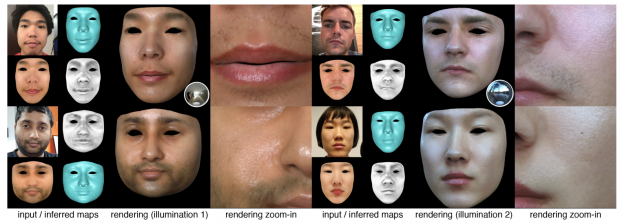
本論文は、1枚の画像から顔の形状と反射率をCNNを用いて推定しモデル化する手法を提案します。1枚の画像から顔の反射率およびジオメトリデータをCNNを用いて推定し、異なる照明条件や任意の視点でレンダリングすることができます。これにより、1枚の画像からより現実的な3D顔面モデルを生成することを可能にします。
- 論文:High-Fidelity Facial Reflectance and Geometry Inference From an Unconstrained Image
- 著者:SHUGO YAMAGUCHI, SHUNSUKE SAITO, KOKI NAGANO,YAJIE ZHAO, WEIKAI CHEN, KYLE OLSZEWSKI,SHIGEO MORISHIMA,HAO LI
- 所属:Waseda University, USC Institute for Creative Technologies, Pinscreen, University of Southern California

© Krenz Cushart, Krenz’s Artwork Sketch Collection 2004-2013 (www.krenzartwork.com)
本論文は、FCN(Fully Convolutional Networks)を用いて、ラフスケッチを入力に自動で線画を出力する手法を提案します。途切れた線を自然につなぎ、不要な線を効率的に消し、自動出力された線画を効果的に修正することができます。
- 論文:Real-Time Data-Driven Interactive Rough Sketch Inking
- 著者:シモセラ エドガー, 飯塚里志, 石川博
- 所属:早稲田大学

本論文では、ニューラルネットワークを用いて、より現実的に滑かな動きを実現する四足歩行キャラクタのリアルタイム制御技術を提案します。リアルタイムに四足歩行キャラクタを制御し、より自然なアニメーションを生成します。
- 論文:Mode-Adaptive Neural Networks for Quadruped Motion Control
- 著者:HE ZHANG, SEBASTIAN STARKE, TAKU KOMURA, JUN SAITO
- 所属:エディンバラ大学, Adobe Research

本論文は、ビデオ内の顔の表情、頭の動き、目の動きや瞬きを外観を維持しながら制御する機械学習を用いた手法を提案します。ソースビデオの人物(顔)からターゲットビデオの人物(顔)へ転送し、3Dアニメーションを再構築します。ソースビデオの人物がターゲットビデオの人物のアイデンティティと外観を維持しながら、頭部姿勢、顔の表情、目の動きや瞬きを制御することを可能にします。
- 論文:Deep Video Portraits
- 著者:H. Kim, P. Garrido, A. Tewari, W. Xu, J. Thies, M. Nießner, P. Perez, C. Richardt, M. Zollhöfer, C. Theobalt
- 所属:MPI Informatics, Technical University of Munich, Technicolor, University of Bath, Stanford University

本論文は、顔認識システムを混乱させプライバシ保護するGANを用いたシステムを提案します。画像内の人物顔を識別するように設計された顔認識ツールを動的に混乱させ、ユーザのプライバシを守ります。画像ベースの検索、特徴の識別、感情特定、人種の推定、自動的に抽出することができる他のすべての顔ベースの属性も混乱させることができるとしています。
- 論文:Adversarial Attacks on Face Detectors using Neural Net based Constrained Optimization
- 著者:Avishek Bose, Parham Aarabi
- 所属:University of Toronto

本論文は、光学式モーションキャプチャで取得したデータのエラーをニューラルネットワークを用いて修正する手法を提案します。本提案手法は、モーションキャプチャデータの大規模なデータベースを用いて、隠れたマーカ、誤ラベルが付いたマーカ、マーカのノイズを含むマーカデータに現れるエラーをエミュレートするように設計された機能を用いてニューラルネットワークで訓練し、自動化パイプラインを構築します。
- 論文:Robust Solving of Optical Motion Capture Data by Denoising
- 著者:Daniel Holden
- 所属:Ubisoft La Forge, Ubisoft, Canada

本論文は、deep learningを用いて、モバイル機器上でキャラクタを高品質かつリアルタイムに動かすための仕組みキャラクタリグ技術を提案します。これにより、計算時間を5倍〜10倍に短縮でき、ローエンドのマシンやモバイル上で複雑なフィルム品質のリグをリアルタイムに実行することを可能にします。
- 論文:Fast and Deep Deformation Approximations
- 著者:Stephen Bailey,Dave Otte,Paul Dilorenzo,James F. O’Brien
- 所属:University of California, Berkeley, DreamWorks Animation

本論文は、人が壁の後ろにいる場合でも、無線信号を解析し、正確な人の姿勢を抽出するニューラルネットワークシステムを提案します。本提案手法は、低電力のワイヤレスRF信号(WiFiより1000倍低電力)を送信し、環境からの反射を受信し分析、人間の骨格を推定します。
- 論文:Through-Wall Human Pose Estimation Using Radio Signals
- 著者:Mingmin Zhao, Tianhong Li, Mohammad Abu Alsheikh, Yonglong Tian, Hang Zhao, Antonio Torralba, Dina Katabi
- 所属:Massachusetts Institute of Technology

本論文は、2Dの群衆動画から人間の姿勢を推定し、身体のテクチャも貼ってくれるCNNを用いたシステム「DensePose」を提案します。これらのことで、複数人が密集した2D画像から人体それぞれの3Dモデルを計算し、画像ピクセルを人体のサーフェス座標に関連付けることができるとします。
- 論文:DensePose: Dense Human Pose Estimation In The Wild
- 著者:Rıza Alp Guler、Natalia Neverova、Iasonas Kokkinos
- 所属:INRIA-CentraleSupelec, Facebook AI Research
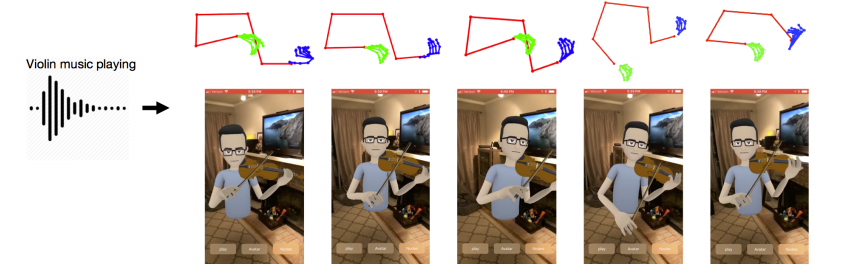
本論文は、バイオリンやピアノ演奏のオーディオを入力として取得し、アバタのアニメーションを作成、骨格予測のビデオを出力するニューラルネットワークを用いたアプローチを提案をします。音声信号から身体のジェスチャを予測します。
- 論文:Audio to Body Dynamics
- 著者:Eli Shlizerman, Lucio Dery, Hayden Schoen, Ira Kemelmacher-Shlizerman
- 所属:Facebook Inc, Stanford University, University of Washington

本論文は、屋内シーンの深度データを入力に、CNNを用いて欠落部分を推定、ラベル付きボクセルの3Dモデルを生成する手法を提案します。本提案手法は、室内シーンにおける深度データを入力に、Fully-CNNを用いたScanCompleteネットワークアーキテクチャから欠落しているジオメトリを推定し、最大1480×1230×64ボクセル(約70×60×3m)としての再構築を出力します。
- 論文:ScanComplete: Large-Scale Scene Completion and Semantic Segmentation for 3D Scans
- 著者:Angela Dai, Daniel Ritchie, Martin Bokeloh, Scott Reed, Jürgen Sturm, Matthias Nießner
- 所属:Stanford University, Brown University, Google, DeepMind, Technical University of Munich

本論文は、ビデオ内の特定のオブジェクトに追跡し色付けすることで、コンピュータビジョンにおけるビジュアルトラッキングの教師なし学習を可能にする技術を提案します。大量のラベル付きデータセットを不要にします。
- 論文:Tracking Emerges by Colorizing Videos
- 著者:Carl Vondrick, Abhinav Shrivastava, Alireza Fathi,Sergio Guadarrama, Kevin Murphy
- 所属:Google Research
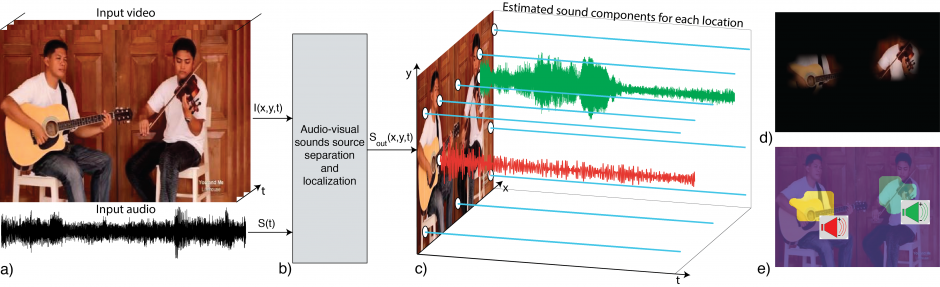
本論文は、音楽ビデオから特定の楽器音だけを分離する教師なし学習アーキテクチャ「PixelPlayer」を提案します。訓練したシステムは、特定の楽器をピクセルレベルで識別したり、それらの楽器に関連付けられたサウンドを抽出することができます。
- 論文:The Sound of Pixels
- 著者:Hang Zhao, Chuang Gan, Andrew Rouditchenko, Carl Vondrick, Josh McDermott, Antonio Torralba
- 所属:Massachusetts Institute of Technology
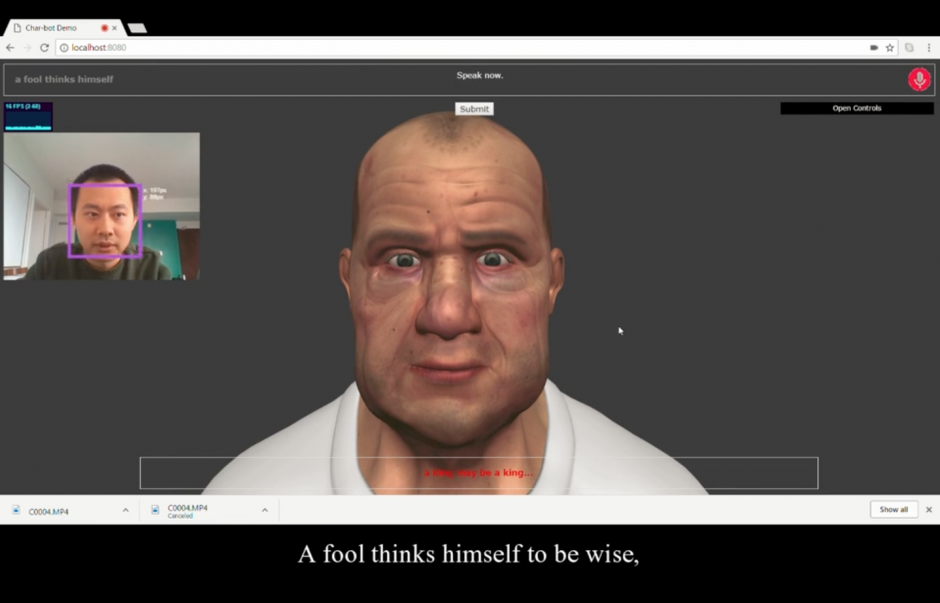
本論文は、テキストもしくは動画による会話文の入力に対して、自然言語による返答と、同時にそれに合う適切な顔のジェスチャを生成するニューラルネットワークモデルを提案します。これらのことで、ボットとの会話のために、テキスト情報と顔情報の両方を用いた適切な応答の生成を可能にしました。
- 論文:A Face-to-Face Neural Conversation Model
- 著者:Hang Chu, Daiqing Li, Sanja Fidler
- 所属:University of Toronto, Vector Institute

本論文は、画像のノイズやアーティファクト、フィルムグレイン等を取り除くDeep learningを用いた手法を提案します。3Dレンダリングや写真の修正、MRI画像などの医療データの改善、天体画像などの低照度撮影まで、幅広い用途への活用が期待されます。
- 論文:Noise2Noise: Learning Image Restoration without Clean Data
- 著者:Jaakko Lehtinen, Jacob Munkberg, Jon Hasselgren, Samuli Laine, Tero Karras, Miika Aittala, Timo Aila
- 所属:NVIDIA, Aalto University, MIT CSAIL

本論文は、スケッチから画像を合成するGANを用いたエンドツーエンドの手法を提案します。入力は、オブジェクトを示すスケッチで、出力は類似のオブジェクトを含む現実的な画像です。
- 論文:SketchyGAN: Towards Diverse and Realistic Sketch to Image Synthesis
- 著者:Wengling Chen, James Hays
- 所属:Georgia Institute of Technology, Argo AI

本論文は、見本のテクスチャから、類似したより大規模で現実的なテクスチャに拡張するGANを用いたテクスチャ合成法を提案します。1つの見本テクスチャに対して、別の画像を供給することで、融合した合成画像を出力したり、1つのソーステクスチャから複数の違う領域を抜き出しシャッフルなどして動的に表現した出力も可能です。
- 論文:Non-Stationary Texture Synthesis by Adversarial Expansion
- 著者:Yang Zhou, Zhen Zhu, Xiang Bai, Dani Lischinski, Daniel Cohen-Or, Hui Huang
- 所属:Shenzhen University, Huazhong University of Science & Technology, The Hebrew University of Jerusalem, Tel-Aviv University
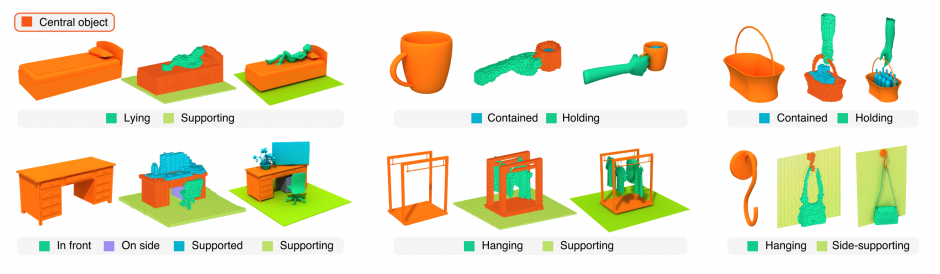
本論分は、単一の3Dオブジェクトに対してどのように使用するかの機能性を推定し可視化するCNNアーキテクチャを提案します。人間は、1つの物体だけを見てどう使うかなどの機能性を予測できます。そんな単一の3Dオブジェクトに対しての機能性を推定し、周囲のオブジェクトとどのように相互作用するかを示すシーンを生成するニューラルネットワークアーキテクチャです。
- 論文:Predictive and Generative Neural Networks for Object Functionality
- 著者:Ruizhen Hu, Zihao Yan, Jingwen Zhang, Oliver van Kaick, Ariel Shamir, Hao Zhang, Hui Huang
- 所属:Shenzhen University, Carleton University, The interdisciplinary Center, Simon Fraser University
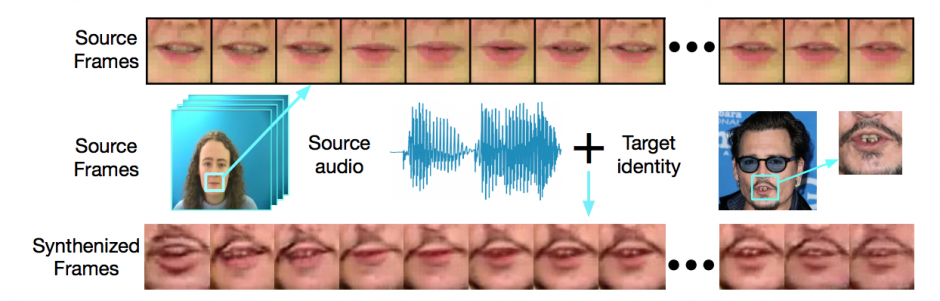
本論文は、任意の音声スピーチから、与えられた唇画像を合成してスピーチに合った唇運動をGANを用いて生成する手法を提案します。ソース音声とターゲット画像を合成し、人物のアイデンティティと共に画像の一貫性を保持しながらリアルに描写することを目指します。
- 論文:Lip Movements Generation at a Glance
- 著者:Lele Chen, Zhiheng Li, Ross K. Maddox, Zhiyao Duan, Chenliang Xu
- 所属:University of Rochester, Wuhan University

本論文は、 動きに合わせて自然なシワも表現する衣服の変形をリアルにシミュレートするための機械学習フレームワーク「DeepWrinkles」を提案します。生成された仮想シャツは、身体とは分離しているため、別のキャラクタ上にリターゲットすることも可能です。
- 論文:DeepWrinkles: Accurate and Realistic Clothing Modelin
- 著者:Zorah L¨ahner, Daniel Cremers, Tony Tung
- 所属:Facebook Reality Labs, Technical University Munich

本論文は、VRハンドトラッキングをリアルタイムに実行するCNNを用いたマーカベースの光学式モーションキャプチャシステムを提案します。キャプチャデータをラベリングするためにCNNを用いて推定し、リアルタイムで手の姿勢を再構築することを可能にするアプローチです。各手袋には、19個のマーカが整備されており、16台のOptitrackカメラでキャプチャします。
- 論文:Online Optical Marker-based Hand Tracking with Deep Labels
- 著者:Shangchen Han, Beibei Liu, Robert Wang, Yuting Ye, Christopher D. Twigg, Kenrick Kin
- 所属:Facebook Reality Labs

本論文は、ソースビデオ内の人からターゲットビデオ内の人へ動きを転送した合成ビデオを生成する機械学習アーキテクチャを提案します。本提案手法は、ソースビデオのフレームからポーズを検出し画像を生成、GANを用いて、ポーズと画像が生成した画像かどうかを区別、ポーズ画像からターゲット画像へのマッピングを学習します。
- 論文:Everybody Dance Now
- 著者:Caroline Chan, Shiry Ginosar, Tinghui Zhou, Alexei A. Efros
- 所属:UC Berkeley

本論文は、前景と背景をオブジェクトごとにピクセルベースで分離し、背景を置き換えたり、色を調整したりを自動でするCNNを用いたアプローチを提案します。本提案手法は、入力である元画像のテクスチャと色情報を分析し、訓練されたCNNと組み合わせることで、その画像内のオブジェクトが実際に何であるかを区別します。
- 論文:Semantic Soft Segmentation
- 著者:YAĞIZ AKSOY, TAE-HYUN OH, SYLVAIN PARIS, MARC POLLEFEYS, WOJCIECH MATUSIK
- 所属:MIT CSAIL, Adobe Research, Microsof, ETH Zürich

本論文は、別のビデオスタイルに動画を変換するGANを用いたデータ駆動型ビデオリターゲット技術を提案します。一方のビデオスタイルを別のビデオへ変換し再構築する教師なしのデータ駆動型アプローチです。顔の表情と動きを人物から別の人物(またはキャラクタ)に変換したり、白黒フィルムをカラーに変換したり、花の開花を別の花へ変換させたり、風が強い風景動画を穏やかな風の風景動画に変換したり、などが可能になります
- 論文:Recycle-GAN: Unsupervised Video Retargeting
- 著者:Aayush Bansal, Shugao Ma, Deva Ramanan, Yaser Sheikh
- 所属:Carnegie Mellon University, Facebook Reality Lab

本論文は、人の高品質な3Dモデルを必要とせずに、ユーザ制御下の写実的なリアルアバタを生成するconditional GANを用いた手法を提案します。人間のフォトリアリスティックな3Dモデルを必要とせずに、ユーザ制御下の実際の人間に近いアニメーションを生成します。自分をベースとしたアバタを作成できるほか、別の人をベースにしたキャラクタも作成することを可能にします。
- 論文:Neural Animation and Reenactment of Human Actor Videos
- 著者:Lingjie Liu, Weipeng Xu, Michael Zollhoefer, Hyeongwoo Kim, Florian Bernard, Marc Habermann, Wenping Wang, Christian Theobalt
- 所属:Max Planck Institute for Informatics, University of Hong Kong, Stanford University

本論文は、ビデオ内の人物において、動きはそのままに人の外観だけを入れ替え可能なdeep learningを用いた手法を提案します。モーションキャプチャデータとRGBビデオデータから訓練できる人間の行動の現実的な制御とレンダリングのための、データ駆動型機械学習フレームワークです。
- 論文:Towards Learning a Realistic Rendering of Human Behavior
- 著者:Patrick Esser, Johannes Haux, Timo Milbich, Björn Ommer
- 所属:HCI, IWR, Heidelberg University
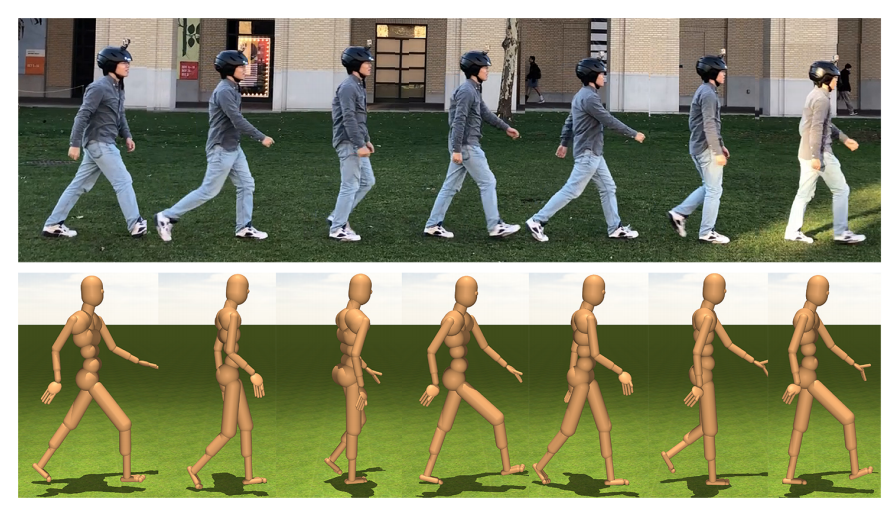
本論文は、頭に取り付けた1台のカメラからの一人称視点映像で本人の3Dポーズを推定する模倣学習を用いた手法を提案します。本提案手法は、頭部装着型カメラで撮影した映像を用いて、人の身体的に有効な3次元姿勢推定を行う目的で、モーションキャプチャデータ、ヒューマノイドモデル、物理シミュレータを活用した模倣学習法を採用します。
- 論文:3D Ego-Pose Estimation via Imitation Learning
- 著者:Ye Yuan, Kris Kitani
- 所属:Carnegie Mellon University

本論文は、複数人の2Dポーズをリアルタイムに高速検出する「Pose Proposal Networks(PPN)」を提案します。物体検出のフレームワークを活用して複数人の姿勢推定をリアルタイムに実行するCNNを用いたEnd-to-endのアプローチです。
- 論文:Pose Proposal Networks
- 著者:Taiki Sekii/関井 大気
- 所属:Konica Minolta

本論文は、CNNを用いて、手書きの2Dスケッチから3Dサーフェスを自動でモデリングするアプローチを提案します。サーフェスを表す法線マップと深さを推定するためにCNNを用います。
- 論文:Robust Flow-Guided Neural Prediction for Sketch-Based Freeform Surface Modeling
- 著者:Changjian Li, Hao Pan, Yang Liu, Xin Tong, Alla Sheffer, Wenping Wang
- 所属:The University of Hong Kong, Microsoft Research Asia, University of British Columbia

本論文は、ソースビデオを入力にフォトリアリスティックな合成ビデオを出力するGANを用いたフレームワークを提案します。これにより、セグメンテーションマスクから背景や自動車を出力したり、顔のエッジマップから人物の顔を出力したり、ポーズから人の踊りを出力したり、ビデオからビデオへの変換を可能にします。
- 論文:Video-to-Video Synthesis
- 著者:Ting-Chun Wang, Ming-Yu Liu, Jun-Yan Zhu, Guilin Liu, Andrew Tao, Jan Kautz, Bryan Catanzaro
- 所属:NVIDIA Corporation, MIT

本論文は、1枚の画像から3Dヘアを再構築するdeep learningを用いた手法を提案します。後頭部、暗い被写体、スタイライズされた画像など、非常に難しいケースも処理可能です。
- 論文:3D Hair Synthesis Using Volumetric Variational Autoencoders
- 著者:Shunsuke Saito, Liwen Hu, Chongyang Ma, Hikaru Ibayashi, Linjie Luo, Hao Li
- 所属:Pinscreen, University of Southern California, USC Institute for Creative Technologies, Snap
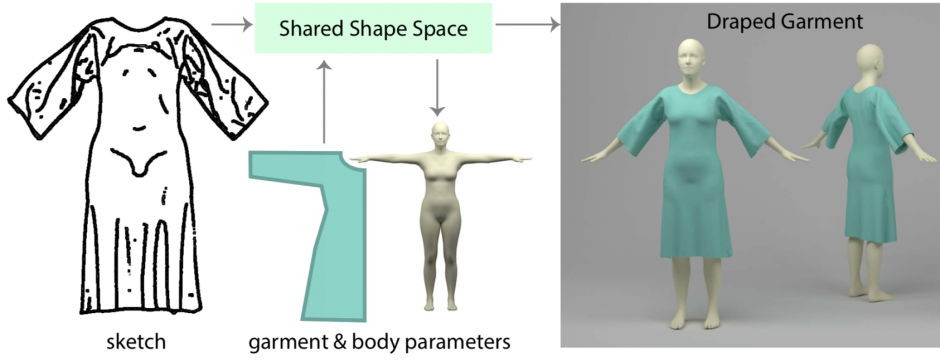
本論文は、衣服のスケッチを入力に、ドレープ含む3D衣服を設計するデータ駆動学習フレームワークを提案します。本提案手法は、折り目パターンを含む衣服スケッチから、2D衣服の縫製パターンと3Dボディ形状パラメータを自動的に推測し、取得したパラメータからドレープされた3D衣服形状を予測します。また、出来上がった衣服は、元のスタイル(折り目パターン、シルエットなど)を維持しながら、異なる身体形状にリターゲットすることが可能です。
- 論文:Learning a Shared Shape Space for Multimodal Garment Design
- 著者:Tuanfeng Y. Wang, Duygu Ceylan, Jovan Popovic, Niloy J. Mitra
- 所属:University College London, Adobe Research

本論文は、動画内のアクロバットな動きから、その動きをキャラクタが習得するdeep learningを用いた手法を提案します。本提案手法は、単眼で撮影された通常の動画からアクロバットなスキル(動画内の人の動き)の姿勢推定をするところから始まり、物理的なシミュレーションでスキルを再現することで3D姿勢推定を補完し、これを学習プロセスにて使用します。
- 論文:SFV: Reinforcement Learning of Physical Skills from Videos
- 著者:Xue Bin Peng, Angjoo Kanazawa, Jitendra Malik, Pieter Abbeel, Sergey Levine
- 所属:University of California, Berkeley

本論文は、既存の3D形状に対して、各部分にSV-BRDFによるマテリアルを自動的に割り当てるdeep learningを用いたテクスチャリング・システム「PhotoShape」を提案します。本提案手法は、本来手動で行うどこにどんなマテリアルを適応するかといった作業を、ネット上にある写真を参照として活用することでそのプロセスを自動化します。
- 論文:PhotoShape: Photorealistic Materials for Large-Scale Shape Collections
- 著者:Keunhong Park, Konstantinos Rematas, Ali Farhadi, Steve Seitz
- 所属:University of Washington, Allen Institute for AI

本論文は、1枚の着衣全身画像とマスクから、別の照明環境下でその人物の陰影(明るい部分や暗い部分)がどのようになるかを、より写実的に再現するCNNを用いた手法を提案します。本提案手法は、ある照明環境下で撮影された被写体が、別の照明環境下でどのような陰影になるかを色、形状、照明を推定し再現します。
- 論文:Relighting Humans: Occlusion-Aware Inverse Rendering for Full-Body Human Images
- 著者:Yoshihiro Kanamori, Yuki End
- 所属:University of Tsukuba, Toyohashi University of Technology

本論文は、動き回ることが可能な実写ベースの仮想空間を作成できるCNNを用いた自由視点レンダリング法を提案します。本提案手法は、実写画像から新規のビューを合成するレンダリング法「Image-based rendering(IBR)」を用いて行います。IBRは、現実的な品質を描画できますが、多くのアーティファクトに悩まされているのが現状です。そこで、本提案手法では、IBRのコア部分であるブレンドステップに、deep learningを用いるアプローチでアーティファクトを軽減させ、より写実的なレンダリングを可能にします。
- 論文:Deep Blending for Free-Viewpoint Image-Based Rendering
- 著者:Peter Hedman, Julien Philip, True Price, Jan-Michael Frahm, George Drettakis, Gabriel Brostow
- 所属:University College London, Inria, Université Côte d’Azur, UNC Chapel Hill, Niantic
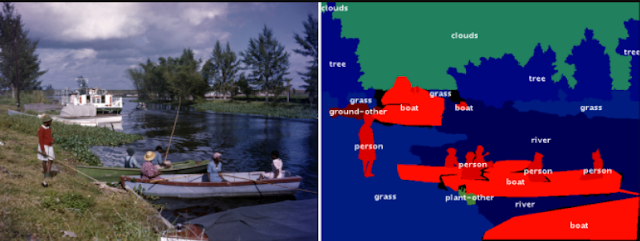
本論文は、画像内の全ての物体に効率的にラベリングする手動と機械学習をコラボしたツールを提案します。画像内のすべてのオブジェクトと背景領域のクラスラベルとアウトラインを注釈するための直感的なヒューマンマシンコラボレーション・インターフェースです。これにより、既存のLabelMeインターフェースより注釈時間が3分の1短いことを実験的に実証しました
- 論文:Fluid Annotation: A Human-Machine Collaboration Interface for Full Image Annotation
- 著者:Mykhaylo Andriluka, Jasper R. R. Uijlings, Vittorio Ferrari
- 所属:Google Research

本論文は、Deep Learningにロボティクスの計算を組み合わせることで、複数のRGBカメラから人物の高精度なモーションキャプチャを行う技術を提案します。本提案手法は、4台のカメラを同期させて、異なる方向から人物のビデオ映像を録画し、それぞれをDeep Learning処理して画像から関節の存在確率を推定します。そして、これらを参考にして、多自由度の人間骨格モデルを動かすことで、運動の3次元再構成を行います。これにより、屋内、屋外、着ている服装を問わずビデオ映像だけからのリアルタイムの運動解析が可能になり、さらに、撮影から骨格の運動の3次元再構成、運動に必要な筋活動の推定と可視化までを、自動で効率的に行う技術を確立しました。
- 論文:Video Motion Capture from the Part Confidence Maps of Multi-Camera Images by Spatiotemporal Filtering Using the Human Skeletal Model
- 著者:Takuya Ohashi, Yosuke Ikegami, Kazuki Yamamoto, Wataru Takano, Yoshihiko Nakamura
- 所属:東京大学, 大阪大学

本論文は、スマートフォンカメラなどの一般的なカメラで撮影された1枚の画像にDoF(Depth of field:被写界深度)効果を生成する機械学習を用いた手法
「DeepLens」を提案します。焦点位置やぼかし加減も調整できます。これにより、モバイルカメラからの画像からDoFを調整することができ、iPhoneのポートレートモードと違って、フォーカルポイントとアパーチャーサイズを柔軟に選択することが可能です。
- 論文:DeepLens: Shallow Depth Of Field From A Single Image
- 著者:Lijun Wang, Xiaohui Shen, Jianming Zhang, Oliver Wang, Zhe Lin, Chih-Yao Hsieh, Sarah Kong, Huchuan Lu
- 所属:Dalian University of Technology, ByteDance AI Lab, Adobe Research, Adobe Systems
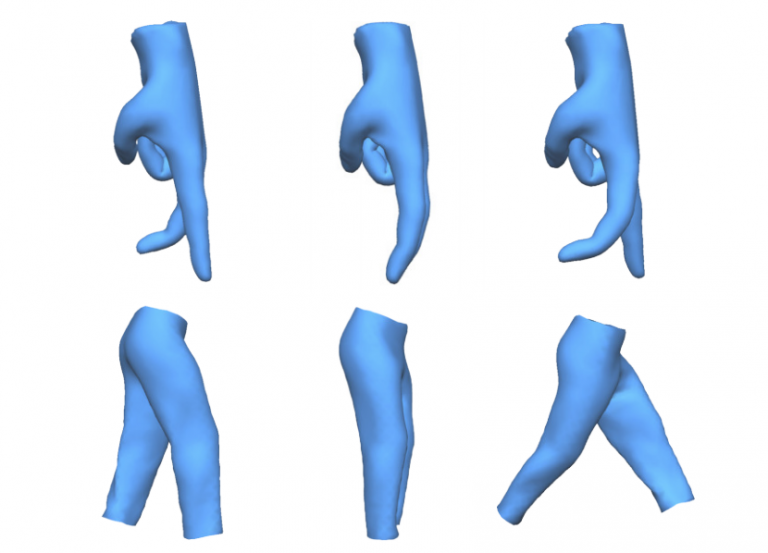
本論文は、ソース形状からターゲット形状にメッシュ変形を転送するGANを用いたアーキテクチャを提案します。ソース形状の変形を別のターゲット形状に、可能な限り類似した形でより自然に移すことを可能にします。例えば、細い人の動作を太い人へ、フラミンゴの動作を人へ、馬の動作を像へ、顔の動作を人へ、指の動作をズボンへ転送したりができます。
- 論文:Automatic Unpaired Shape Deformation Transfer
- 著者:LIN GAO, JIE YANG, YI-LING QIAO, YU-KUN LAI, PAUL L. ROSIN, WEIWEI XU, SHIHONG XIA
- 所属:Institute of Computing Technology, y, Chinese Academy of Sciences, University of Chinese Academy of Sciences, Cardiff University, Zhejiang University

本論文は、Deep Reinforcement Learning(深層強化学習/deepRL)を用いて、より自然な着衣アニメーションを生成するアルゴリズムを提案します。本提案手法は、着衣制御ポリシーを学習するためのdeepRLフレームワークに、布シミュレーションを組み込むことで実現します。具体的には、シャツの端をつかみ、シャツの開口部に手を入れて、袖を通して手を押すなどの様々なサブタスクに分解し、各サブタスクの制御ポリシーを個別に学習し、各サブタスクの入力分布を以前のサブタスクの出力分布と一致させることで実現します。
- 論文:Learning to Dress: Synthesizing Human Dressing Motion via Deep Reinforcement Learning
- 著者:Alexander Clegg, Wenhao Yu, Jie Tan, C. Karen Liu, Greg Turk
- 所属:The Georgia Institute of Technology, Google Brain

本論文は、1枚の入力顔画像から、モバイル端末に3Dアバターを作成し、自身の表情を介して制御できるdeep learningモデル「paGAN(photoreal avatar GAN)」を提案します。ネットワークは、顔の表情だけでなく、入力画像からは見えない口の内部、視線方向も制御し、新しい顔画像を様々な視点から合成することができます。これにより、自身の表情を用いて、写実的なアバターをスマートフォン上でリアルタイムに操作することを可能にしています。
- 論文:paGAN: Real-time Avatars Using Dynamic Textures
- 著者:Koki Nagano, Jaewoo Seo, Jun Xing, Lingyu Wei, Zimo Li, Shunsuke Saito, Aviral Agarwal, Jens Fursund, Hao Li
- 所属:Pinscreen, USC Institute for Creative Technologies, University of Southern California
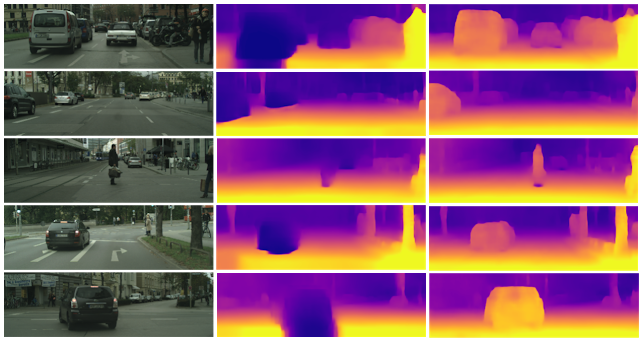
本論文は、単眼カメラで撮影したRGB画像を入力に、深度とエゴモーションを推定する教師なし学習を用いた手法を提案します。本提案手法は、ニューラルネットワークを用いて直接深度を学習するのではなく、個々のオブジェクトに分解するアプローチにより安価な単眼カメラのみで対処できることを実証しました。個々のオブジェクトとモーションを独立して3Dモデリングすることで、深度とエゴモーションを推定します。これにより、シーン内の動的オブジェクト(例:移動する車、人、自転車など)がどこに向かっているかを検出することができ、また、動いている物体だけでなく、静的オブジェクトでも、潜在的に移動する可能性があるかを学習し役立てます。
- 論文:Depth Prediction Without the Sensors: Leveraging Structure for Unsupervised Learning from Monocular Videos
- 著者:Vincent Casser, Soeren Pirk, Reza Mahjourian, Anelia Angelova
- 所属:Google Brain, Institute for Applied Computational Science, Harvard University, University of Texas at Austin
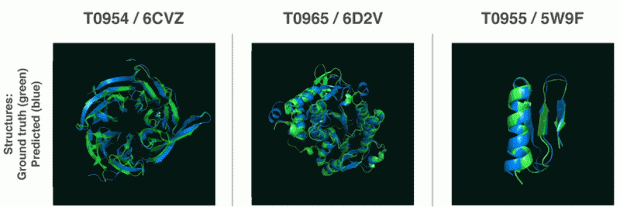
本論文は、アミノ酸配列を用いてタンパク質構造を推定する「AlphaFold」を提案します。アミノ酸配列からタンパク質の立体構造を理論的に(どのように折り畳まれるかを)予測する問題を「タンパク質の折りたたみ問題」と言います。本提案手法は、そんな「タンパク質の折りたたみ問題」を、アミノ酸配列からタンパク質の3Dモデルをdeep learningを用いて予測します。これにより、間違って折りたたまれたことによって発病する病気(アルツハイマー病、パーキンソン病、ハンチントン病等)の原因解明や、その治療への応用、そして生物への理解をより深めるために役立てます。
- 論文:De novo structure prediction with deep-learning based scoring
- 著者:R.Evans, J.Jumper, J.Kirkpatrick, L.Sifre, T.F.G.Green, C.Qin, A.Zidek, A.Nelson, A.Bridgland, H.Penedones, S.Petersen, K.Simonyan, D.T.Jones, K.Kavukcuoglu, D.Hassabis, A.W.Senior
- 所属:DeepMind

本論文は、fMRIを用いて脳活動から人がどこを注視しているかを機械学習を用いて推定し視覚化するアプローチを提案します。本提案手法は、脳がどのようにこの能力を調整するか、どのように脳がその複雑な計算を素早く実行するか、正確な脳計測を使用して、自然な風景を見るときに人の目がどのように動くかを推定します。
- 論文:Predicting eye movement patterns from fMRI responses to natural scenes
- 著者:Thomas P. O’Connell, Marvin M. Chun
- 所属:Yale University, Yale School of Medicine
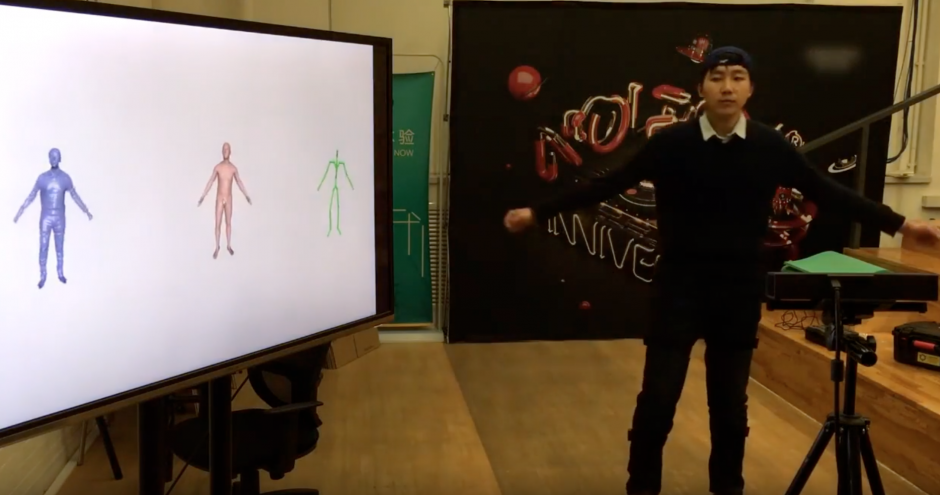
本論文は、1台の深度カメラと複数の慣性計測装置(inertial measurement unit、IMU)を用いて、服を着ている人の全身運動を再構築する新たなパフォーマンスキャプチャシステム「HybridFusion」を提案します。デプスマップとIMU測定値をもとに、新しいハイブリッドモーショントラッキングアルゴリズムを使用して、骨格運動と表面非剛体変形を同時に追跡します。深度カメラでは捉えきれない高速な動きによる隠蔽などを、IMUによる高いフレームレートの方向情報を提供することで補います。ユーザの腕に8つ、足に4つのIMUを付け、方向測定を行います。
- 論文:HybridFusion: Real-Time Performance CaptureUsing a Single Depth Sensor and Sparse IMUs
- 著者:Zerong Zheng, Tao Yu, Hao Li, Kaiwen Guo, Qionghai Dai, Lu Fang, Yebin Liu
- 所属:Tsinghua University, Beihang University, University of Southern California, Google, Tsinghua-Berkeley Shenzhen Institute

本論文は、動物の毛皮を現実的に再現するニューラルネットワークを用いた手法を提案します。光が毛皮に反射する方法を改良することで、より正確なレンダリングを実現しました。具体的には、ニューラルネットワークを用いて、「表面下散乱(Subsurface Scattering)」を計算し取り入れたことです。
- 論文:A BSSRDF Model for Efficient Rendering of Fur with Global Illumination
- 著者:LING-QI YAN, WEILUN SUN,HENRIK WANN JENSEN, RAVI RAMAMOORTHI
- 所属:University of California Berkeley, University of California San Diego