本ページは、人工知能(AI, Artificial Intelligence)、機械学習(Machine Learning)、深層学習(Deep Learning)に関する最新論文を厳選し、時系列順に随時更新、一覧にしている場所です。
また、本ページのようにアーカイブベースではなく、速報ベースで取得したい方は、月1回の配信で最新論文を紹介するWebコンテンツもあります。
初めての方はこちら。
索引
最初に、索引として「A~Z」順に並べています。 索引を飛ばす場合はこちら。
- 3D Ego-Pose Estimation via Imitation Learning
- 3D Hair Synthesis Using Volumetric Variational Autoencoders
- 3D-SIS: 3D Semantic Instance Segmentation of RGB-D Scans
A
- A Deep Learning-Based Model for Head and Eye MotionGeneration in Three-party Conversations
- A Face-to-Face Neural Conversation Model
- ALIGNet: Partial-Shape Agnostic Alignment via Unsupervised Learning
- AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks
- Audio to Body Dynamics
- Automatic Unpaired Shape Deformation Transfer
B
- Bio-LSTM: A Biomechanically Inspired Recurrent Neural Network for 3D Pedestrian Pose and Gait Prediction
- Brain-inspired automated visual object discovery and detection
C
- CariGANs: Unpaired Photo-to-Caricature Translation
- Character Representation Adaption in Individual Manga
- Computational Foresight: Forecasting Human Body Motion in Real-time for Reducing Delays in Interactive System
- Computational Mirrors: Blind Inverse Light Transport by Deep Matrix Factorization
D
- DeepFly, a deep learning-based approach for 3D limb and appendage tracking in tethered adult Drosophila
- DeepLens: Shallow Depth Of Field From A Single Image
- Deep image reconstruction from human brain activity
- Deep Inertial Poser: Learning to Reconstruct Human Pose from Sparse Inertial Measurements in Real Time
- DeepMimic: Example-Guided Deep Reinforcement Learning of Physics-Based Character Skills
- Deep Multispectral Painting Reproduction via Multi-Layer, Custom-Ink Printing
- DeepType: Multilingual Entity Linking by Neural Type System Evolution
- Deep Single Image Portrait Relighting
- Deep Video Portraits
- DeepWrinkles: Accurate and Realistic Clothing Modelin
- DenseBody: Directly Regressing Dense 3D Human Pose and Shape From a Single Color Image
- DensePose: Dense Human Pose Estimation In The Wild
- Depth Prediction Without the Sensors: Leveraging Structure for Unsupervised Learning from Monocular Videos
- Designing Chain Reaction Contraptions from Causal Graphs
- Document Rectification and Illumination Correction using a Patch-based CNN
- DReCon: data-driven responsive control of physics-based characters
E
- Ego-Pose Estimation and Forecasting as Real-Time PD Control
- End-to-end Recovery of Human Shape and Pose
- Everybody Dance Now
- Everybody’s Talkin’: Let Me Talk as You Want
- Everyday Eye Contact Detection Using Unsupervised Gaze Target Discovery
- Exploring Neural Networks with Activation Atlases
F
- FaceForensics: A Large-scale Video Dataset for Forgery Detection in Human Faces
- Fast and Deep Deformation Approximations
- Few-shot Video-to-Video Synthesis
- Finding Tiny Faces in the Wild with Generative Adversarial Network
- From Faces to Outdoor Light Probes
- FSGAN: Subject Agnostic Face Swapping and Reenactment
G
- GAN Dissection: Visualizing and Understanding Generative Adversarial Networks
- GAN Lab: Understanding Complex Deep Generative Models using Interactive Visual Experimentation
- Google Research Football: A Novel Reinforcement Learning Environment
- GRAINS: Generative Recursive Autoencoders for Indoor Scenes
H
- High-Fidelity Facial Reflectance and Geometry Inference From an Unconstrained Image
- How to Train Your Dragon: Example-Guided Control of Flapping Flight
- HybridFusion: Real-Time Performance CaptureUsing a Single Depth Sensor and Sparse IMUs
I
- Image Inpainting for Irregular Holes Using Partial Convolutions
- InstaGAN: Instance-aware Image-to-Image Translation
- InteractionFusion: Real-time Reconstruction of Hand Poses andDeformable Objects in Hand-object Interactions
- Interactive Example-Based Terrain Authoring with Conditional Generative Adversarial Networks
- Interactive Sketch-Based Normal Map Generation with Deep Neural Networks
- Interactive Hand Pose Estimation using a Stretch-Sensing Soft Glove
- Interactive Image Segmentation via Backpropagating Refinement Scheme
- InverseFaceNet:Deep Single-Shot Inverse Face Rendering From A Single Image
J
K
L
- Large Pose 3D Face Reconstruction from a Single Image via Direct Volumetric CNN Regression
- Learning 3D Human Dynamics from Video
- Learning an Intrinsic Garment Space for Interactive Authoring ofGarment Animation
- Learning a Shared Shape Space for Multimodal Garment Design
- Learning Basketball Dribbling Skills Using Trajectory Optimization and Deep Reinforcement Learning
- Learning Category-Specific Mesh Reconstruction from Image Collections
- Learning Character-Agnostic Motion for Motion Retargeting in 2D
- Learning the Depths of Moving People by Watching Frozen People
- Learning to Dress: Synthesizing Human Dressing Motion via Deep Reinforcement Learning
- Learning To Fly: Computational Controller Design For Hybrid UAVs With Reinforcement Learning
- Learning to Localize Sound Source in Visual Scenes
- Learning to See in the Dark
- Learning Visual Importance for Graphic Designs and Data Visualizations
- Lip Movements Generation at a Glance
- LiveCap: Real-time Human Performance Capture from Monocular Video
- Looking to Listen at the Cocktail Party: A Speaker-Independent Audio-Visual Model for Speech Separation
M
- MarioNETte: Few-shot Face Reenactment Preserving Identity of Unseen Targets
- Mo2Cap2: Real-time Mobile 3D Motion Capture with a Cap-mounted Fisheye Camera
- Mode-Adaptive Neural Networks for Quadruped Motion Control
- MonoPerfCap: Human Performance Capture from Monocular Video
- Multimodal Explanations: Justifying Decisions and Pointing to the Evidence
- Multimodal Unsupervised Image-to-Image Translation
- Multi-view Relighting Using a Geometry-Aware Network
N
- Neural Animation and Reenactment of Human Actor Videos
- Neural Best-Buddies: Sparse Cross-Domain Correspondence
- Neural Human Video Rendering: Joint Learning of Dynamic Textures and Rendering-to-Video Translation
- Neural Rerendering in the Wild
- Neural State Machine for Character-Scene Interactions
- Neural Style-Preserving Visual Dubbing
- Neural Voice Puppetry:Audio-driven Facial Reenactment
- Noise2Noise: Learning Image Restoration without Clean Data
- Non-Stationary Texture Synthesis by Adversarial Expansion
O
P
- Parrotron: An End-to-End Speech-to-Speech Conversion Model and its Applications to Hearing-Impaired Speech and Speech Separation
- PlaneNet: Piece-wise Planar Reconstruction from a Single RGB Image
- PhotoShape: Photorealistic Materials for Large-Scale Shape Collections
- PIFu: Pixel-Aligned Implicit Function for High-Resolution Clothed Human Digitization
- Pose Proposal Networks
- Predicting eye movement patterns from fMRI responses to natural scenes
- Predicting Gaze in Egocentric Video by Learning Task-dependent Attention Transition
- Predictive and Generative Neural Networks for Object Functionality
- Probabilistic plant modeling via multi-view image-to-image translation
Q
R
- Real-Time Data-Driven Interactive Rough Sketch Inking
- Real-Time Hair Rendering using Sequential Adversarial Networks
- Real-Time Patch-Based Stylization of Portraits Using Generative Adversarial Network
- Recycle-GAN: Unsupervised Video Retargeting
- ReenactGAN: Learning to Reenact Faces via Boundary Transfer
- Reinforcement Learning for Improving Agent Design
- Relighting Humans: Occlusion-Aware Inverse Rendering for Full-Body Human Images
- Robust Flow-Guided Neural Prediction for Sketch-Based Freeform Surface Modeling
S
- Scalable Muscle-actuated Human Simulation and Control
- ScanComplete: Large-Scale Scene Completion and Semantic Segmentation for 3D Scans
- SC-FEGAN: Face Editing Generative Adversarial Network with User’s Sketch and Color
- Semantic Photo Manipulation with a Generative Image Prior
- Semantic Soft Segmentation
- SFV: Reinforcement Learning of Physical Skills from Videos
- Single Image Portrait Relighting
- Single-Image SVBRDF Capture with a Rendering-Aware Deep Network
- Sketch2Normal: Deep Networks for Normal Map Generation
- SketchyGAN: Towards Diverse and Realistic Sketch to Image Synthesis
- SoftCon: Simulation and Control of Soft-Bodied Animals with Biomimetic Actuators
- Speech synthesis from neural decoding of spoken sentences
- SubMe: An Interactive Subtitle System with English Skill Estimation Using Eye Tracking
- Stereo Magnification: Learning view synthesis using multiplane images
- Synthetic Defocus and Look-Ahead Autofocus for Casual Videography
- Synthesizing Programs for Images using Reinforced Adversarial Learning
T
- Temporal Cycle-Consistency Learning
- Text-based Editing of Talking-head Video
- The Mental Image Revealed by Gaze Tracking
- The Relightables:Volumetric Performance Capture of Humans with Realistic Relighting
- The Sound of Pixels
- Through-Wall Human Pose Estimation Using Radio Signals
- TileGAN: Synthesis of Large-Scale Non-Homogeneous Textures
- TOM-Net: Learning Transparent Object Matting from a Single Image
- Towards Learning a Realistic Rendering of Human Behavior
- Tracking Emerges by Colorizing Videos
- Transport-Based Neural Style Transfer for Smoke Simulations
U
- Unsupervised Image-to-Image Translation Networks
- Unsupervised Learning of Shape and Pose with Differentiable Point Clouds
- Using automated data augmentation to advance our Waymo Driver
V
- Vid2Game: Controllable Characters Extracted from Real-World Videos
- Video Inpainting by Jointly Learning Temporal Structure and Spatial Details
- Video-to-Video Synthesis
- VirtualHome: Simulating Household Activities via Programs
- Visual to Sound: Generating Natural Sound for Videos in the Wild
- VOCA: Capture, Learning, and Synthesis of 3D Speaking Styles
W
- When will you do what? – Anticipating Temporal Occurrences of Activities
- Who’s Better? Who’s Best? Pairwise Deep Ranking for Skill Determination
X
Y
Z
機械学習、 深層学習の最新研究一覧

Deep Single Image Portrait Relighting
ポートレート画像を再照明するCNNを用いた手法。ソース画像とターゲット照明を入力に1024×1024の解像度で出力。類似研究で最高の解像度。大量の再照明顔画像データセットも公開中。動画
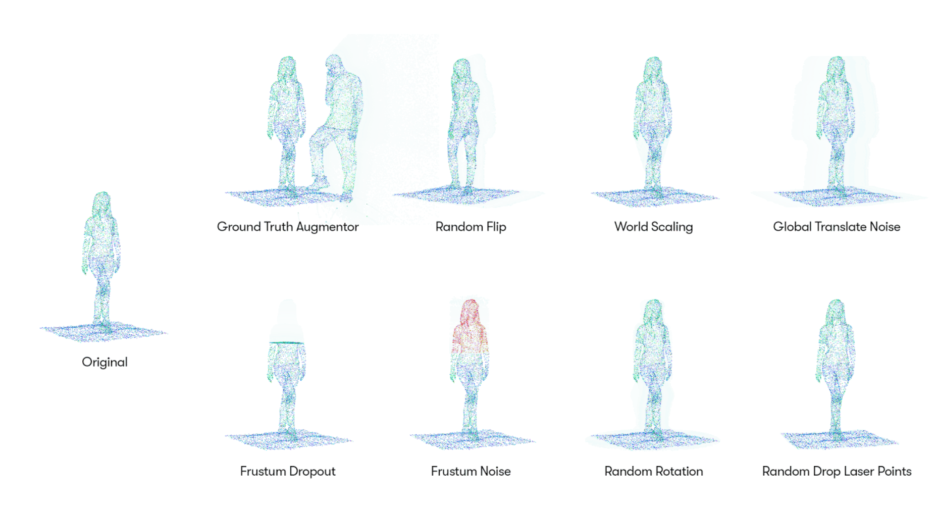
Using automated data augmentation to advance our Waymo Driver
本研究は、追加の収集やラベル付けのコストなしにデータから新しいデータの量と多様性を増やす手法。LIDARのオリジナルデータから複数のデータを生成。自動運転車が周囲の3Dオブジェクトを検出するための学習用データセットに活用する。

MarioNETte: Few-shot Face Reenactment Preserving Identity of Unseen Targets
寄稿:顔の静止画像に動きを合成し操る技術。首、口、目、眉の動きなど大小の動作を制御。今までより出力後の不自然を軽減した。動画
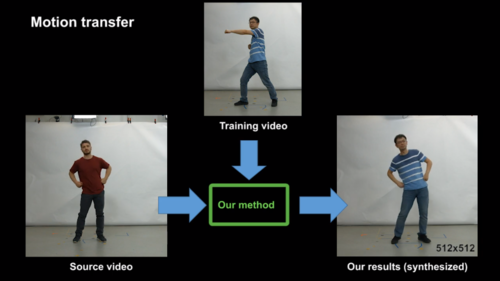
Neural Human Video Rendering: Joint Learning of Dynamic Textures and Rendering-to-Video Translation
CNNを用い、動画内の衣服を着た人物の全身運動を制御する合成技術の研究。人物Aの動きを人物Bへ転送。Bの外観は保持したままAの動きをさせる。合成後の服のシワの欠損を軽減。また人型スケルトンを動かしゲームのようにBを動かす。バレットタイムの生成も可能。動画
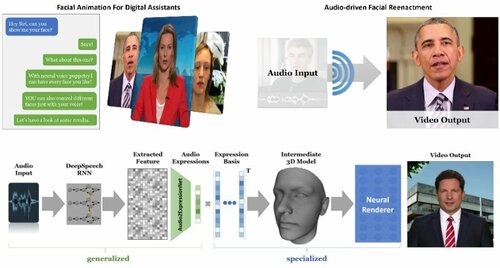
Neural Voice Puppetry:
Audio-driven Facial Reenactment
音声を入力を元に、その音声に合わせた写実的な顔のアニメーションを生成する深層学習を用いた手法。任意の音声(テキスト)を入力に、音声に合わせ指定する顔の口元を操り人形のように話させる。デジタルアシスタントの音声も好きな顔に変換可能。遠隔会議で自撮り写真に話させる等。動画

Everybody’s Talkin’: Let Me Talk as You Want
音声から、その音声を話すリアルな人のビデオを合成する手法を提案する研究。任意のソースオーディオから、表現パラメーターに変換するリカレントネットワークが用いられ、ターゲットのポートレート映像の口領域を編集する。動画

Document Rectification and Illumination Correction using a Patch-based CNN
文章が書かれたプリントをスマートフォンで撮影した画像の歪み(傾き、湾曲、しわ等)や照明による暗い部分等を、スキャンしたように均等に明るく平らな画像に変換する技術を提案する研究。

Few-shot Video-to-Video Synthesis
映像内の動きを抽出して画像に転送することで、リアルな合成動画を生成するGANを用いた手法を提案する研究。人の全身運動や顔の輪郭運動など、領域分割マスクや線画スケッチを基に、動かしたい画像に合成し写実的な映像に仕上げる。訓練データに含まれてなくても合成可能が新規性。動画

Computational Mirrors: Blind Inverse Light Transport by Deep Matrix Factorization
投影した映像が跳ね返った光の動き(影)から、その動きを予測し再現するシステムを提案する研究。プロジェクターで投影するスクリーンから跳ね返った光が反対側の壁に映る光の動き、その動きから映像を推定する機械学習を用いた手法。画像:左が跳ね返った光、中央が入力映像、右が出力結果。動画

DReCon: data-driven responsive control of physics-based characters
物理シミュレーションと、大量のモーションキャプチャデータを使用したデータ駆動型アニメーションシステム 「モーションマッチング」 とを組み合わせたキャラクター制御システムを提案する研究。深層学習を用いて訓練することで、実行コストを抑えた高品質アニメーションを実現する。動画

Neural State Machine for Character-Scene Interactions
モーションキャプチャデータからキャラクターとオブジェクトの相互作用を学習し、制御コマンドから高品質のアニメーションを生成する深層学習フレームワークを提案する研究。椅子に座ったり、荷物を持ち運んだりのアニメーションをリアルに生成。動画

The Relightables:Volumetric Performance Capture of Humans with Realistic Relighting
深層学習と独自の撮影機材を用い、3Dアバターを生成できるパフォーマンスキャプチャーシステム「The Relightables」を提案する研究。カスタムLightStage(RGBカメラ58台IRカメラ32台プロジェクタ16台照明331個)で全身キャプチャし任意バーチャルシーンに合わせ照明の当たり方を変えリアルな動きを表現。動画
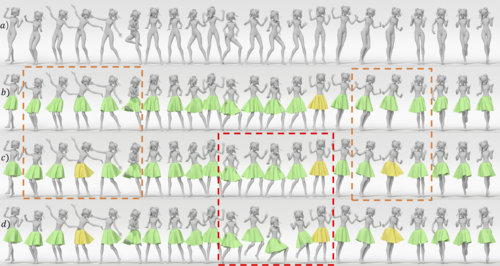
Learning an Intrinsic Garment Space for Interactive Authoring ofGarment Animation
半自動で衣服アニメーションを生成できるDeep learningを用いた手法を提案する研究。フレームを確認しながら、衣服形状を加えたり、モーションを一部変更したりして、インタラクティブに編集する。動画

Neural Style-Preserving Visual Dubbing
ビデオ内人物の口の動きを別のビデオ内人物の口の動きへ転送するGANを用いた手法を提案する研究。 ターゲット人物のアイデンティティを維持しながら、ソース人物の口の動きと声を転送できる。動画

SoftCon: Simulation and Control of Soft-Bodied Animals with Biomimetic Actuators
水中軟体動物の設計と制御をするためのdeep learningを用いたフレームワークを提案する研究。 タコ、ウナギ、ヒトデ、エイ、イカなど、さまざまな水中軟体動物のシミュレートを実証し、泳ぐ、つかむ、瓶から逃げるなどの多様な行動も学ぶ。リアルタイム制御も可能。動画

FSGAN: Subject Agnostic Face Swapping and Reenactment
別の画像に顔を転送するRNNをベースとしたネットワークを提案する研究。任意の動画内人物に、好きな顔を合成できる。髪型などはそのままに、顔の表面がシームレスに合成される。動画

Transport-Based Neural Style Transfer for Smoke Simulations
通常の画像から煙などの流体シミュレーションへスタイル転送できる機械学習を用いた手法を提案する研究。CNN(転移学習)を用いて、煙から特徴抽出を行い、その特徴と画像を合成する。動画

InteractionFusion: Real-time Reconstruction of Hand Poses andDeformable Objects in Hand-object Interactions
2台の深度センサーを用いて、手とオブジェクトのやり取りをリアルタイム且つより正確に再構築する機械学習を用いた手法を提案する研究。動画

Semantic Photo Manipulation with a Generative Image Prior
画像内の編集したい部分をなぞるだけで、ニューラルネットワークが周囲と調和した違う画像に変えるツールを提案する研究。 1枚の画像に対して、カーソル操作でなぞればその部分がそれらしい画像に変更。動画
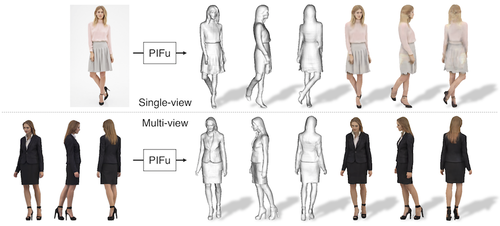
PIFu: Pixel-Aligned Implicit Function for High-Resolution Clothed Human Digitization
1枚の画像から服を着た人の3Dモデルを再構築できるdeep learningを用いた手法を提案する研究。被写体の背面など、見えない領域もそれらしい形状及びテクスチャを推定 。動画
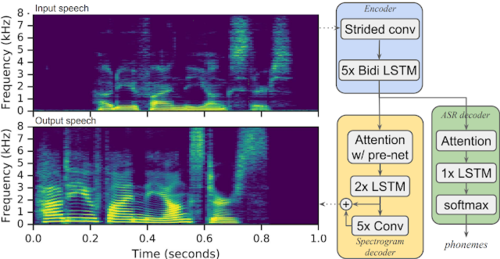
Parrotron: An End-to-End Speech-to-Speech Conversion Model and its Applications to Hearing-Impaired Speech and Speech Separation
言語障害者の音声を流暢な合成音声に直接変換する機械学習を用いた手法「Parrotron」を提案する研究。言語障害者の音声アシスタントへの入力エラー率を軽減。動画

Synthetic Defocus and Look-Ahead Autofocus for Casual Videography
スマートフォンカメラで気軽に撮影する映像において、背景ボケ映像(被写界深度の浅い映像)の表現を文脈に合わせてリアルタイムに合成する機械学習を用いた手法を提案する研究。静止画像ではなく動画。動画

Text-based Editing of Talking-head Video
動画内の人の会話をテキストベースに修正するだけで口の動きも音声と共に修正できる機械学習を用いた手法を提案する研究。言い間違いなどの部分的な箇所を自然に修正できる。 動画
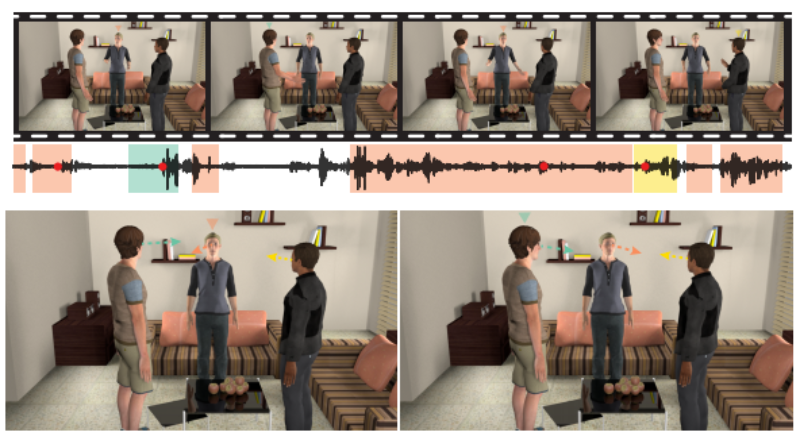
A Deep Learning-Based Model for Head and Eye MotionGeneration in Three-party Conversations
3人対話で各アバターの視線や頭胴部などの動きを会話に合わせて自動生成するdeep learningを用いた手法を提案する研究。音声信号を入力に、話者の目と頭の動的方向を推定。動画

Learning To Fly: Computational Controller Design For Hybrid UAVs With Reinforcement Learning
ドローンと飛行機を組み合わせたハイブリットUAVの制御システムを自動設計する機械学習を用いた手法を提案する研究。 ローター制御(マルチコプターモード)とウィング制御(飛行機モード) を切り替えて飛行。動画

Single Image Portrait Relighting
スマートフォンカメラで撮影した人物画像の照明環境を後から変更できるLight Stageと機械学習を用いたリライティング法を提案する研究。 LightStageで取得した 顔データセットで訓練。動画
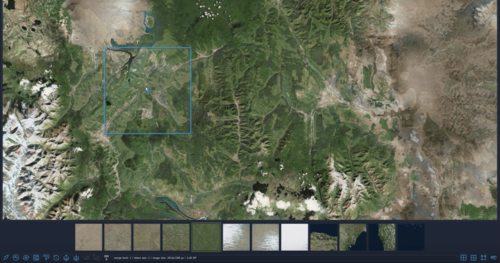
TileGAN: Synthesis of Large-Scale Non-Homogeneous Textures
大規模な不均一テクスチャをより高精度に生成するGANを用いたテクスチャ合成技術「TileGAN」を提案する研究。 サンプル画像を入力に、類似した大規模で自然な画像に合成する。動画

Multi-view Relighting Using a Geometry-Aware Network
屋外画像の太陽光だけを変更及び制御できる機械学習を用いたマルチビューリライティングシステムを提案する研究。屋外画像の光を変更するため、太陽の位置、それによる影の位置を再構築する。動画

Neural Rerendering in the Wild
ネット上の異なる角度や距離から撮影した観光地のランドマーク画像群から3Dシーンを生成するより現実的にレンダリングできる機械学習フレームワークを提案する研究。公に入手可能な写真を唯一の入力に、さまざまな照明条件下でリアルな3Dシーンを生成する。動画
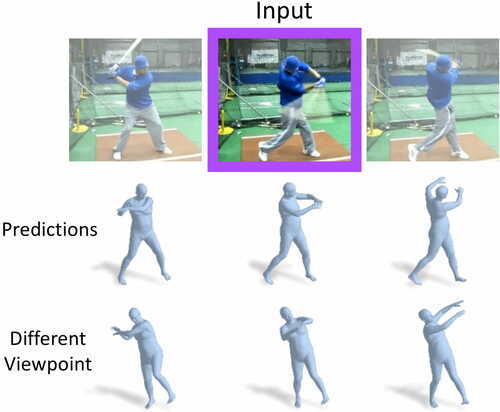
Learning 3D Human Dynamics from Video
1枚の2D静止画像から人物の過去と未来の3Dポーズの動きを推定する機械学習を用いたフレームワークを提案する研究。動画
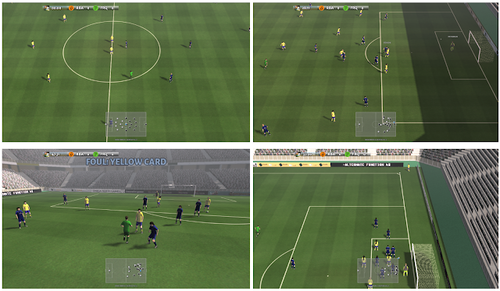
Google Research Football: A Novel Reinforcement Learning Environment
サッカーのビデオゲームをマスターするための強化学習環境である「Google Research Football Environment」を提案する研究。チーム内のすべてのプレイヤーを制御し、選手間のパスの仕方を学び、ゴールを決めるための動きを学習する。動画

Ego-Pose Estimation and Forecasting as Real-Time PD Control
1台の頭部装着型カメラからの一人称視点映像を入力に自身の3D姿勢をリアルタイムに推定する手法を提案する研究。 歩行や走行 、しゃがむなどの動きを屋内外で推定。また、動きの未来予測として、将来の動きを生成可能。動画
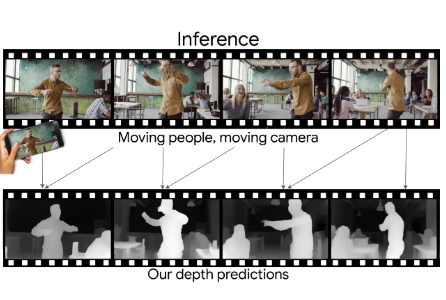
Learning the Depths of Moving People by Watching Frozen People
シーン内の人とカメラの両方が移動していても1台の単眼カメラから深度を予測するDeep Learningを用いた手法を提案する研究。 ぼかし領域のリアルタイム操作、オブジェクトの除去と挿入、ビューの3D化などを可能にする。動画

Vid2Game: Controllable Characters Extracted from Real-World Videos
映像内から抜き出した人物をそのままゲームキャラクタに変換する手法「Vid2Game」を提案する研究。通常のビデオ内から人物の動きを抜き出し、別の背景に登場させ上下左右にコントロールすることを可能にする。動画

Interactive Hand Pose Estimation using a Stretch-Sensing Soft Glove
外部光学機器を必要とせずにリアルタイムに手のポーズを推定するDeep Learningを用いたストレッチセンシングソフトグローブを提案する研究。安価に高精度なハンドトラッキング を可能にする。動画
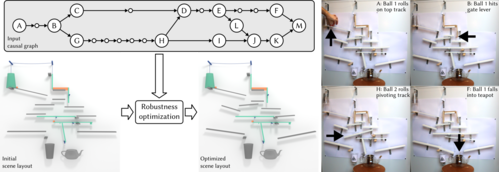
Designing Chain Reaction Contraptions from Causal Graphs
ピタゴラ装置を設計する物理シミュレーションと機械学習を用いた計算フレームワークを提案する研究。 ユーザによって提供される原因結果グラフ技法の大雑把なレイアウト図を入力に、物理ベースのシミュレーションと機械学習を用いて条件下でレイアウトを最適化 する。動画
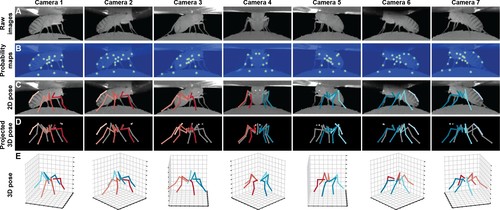
DeepFly, a deep learning-based approach for 3D limb and appendage tracking in tethered adult Drosophila
ハエの動きを3Dで姿勢推定できるDeep learningを用いたモーションキャプチャ「DeepFly」を提案する研究。どこでも登れたりのハエの身体能力を手足の動作から探究し、小型の自律飛行ロボットを設計するために活用する。動画
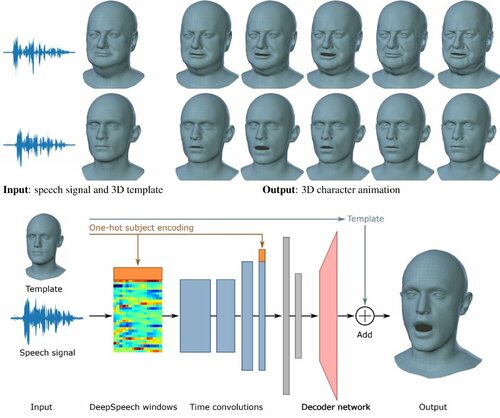
VOCA: Capture, Learning, and Synthesis of 3D Speaking Styles
音声から顔アニメーションを生成するdeep learningを用いた手法「VOCA」を提案する研究。任意の音声信号と静的キャラクタメッシュを入力に、自動的にリアルな喋るキャラクタアニメーションを出力する。動画
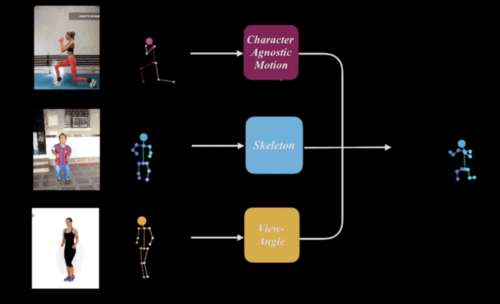
Learning Character-Agnostic Motion for Motion Retargeting in 2D
人の動きを別動画内人物へリターゲティングするDeep Learningを用いた手法を提案する研究。任意のモーションを任意のスケルトンと組み合わせて、任意のビュー方向から2D再構築することを可能にする。動画

GRAINS: Generative Recursive Autoencoders for Indoor Scenes
もっともらしい3D屋内シーンを効率的に大量生成できるニューラルネットワーク「GRAINS」を提案する研究。長方形の部屋をベースに間取りを自動生成する。

Real-Time Patch-Based Stylization of Portraits Using Generative Adversarial Network
スタイル見本画像を動的な顔へリアルタイムに転送する機械学習を用いた手法「FaceStyleGAN」を提案する研究。被写体のアイデンティティを維持しながら、顔の表情だけを動かす。動画

PlaneNet: Piece-wise Planar Reconstruction from a Single RGB Image
1枚の画像から平面深度マップをピース単位で再構築する機械学習を用いた手法「PlaneNet」を提案する研究。動画
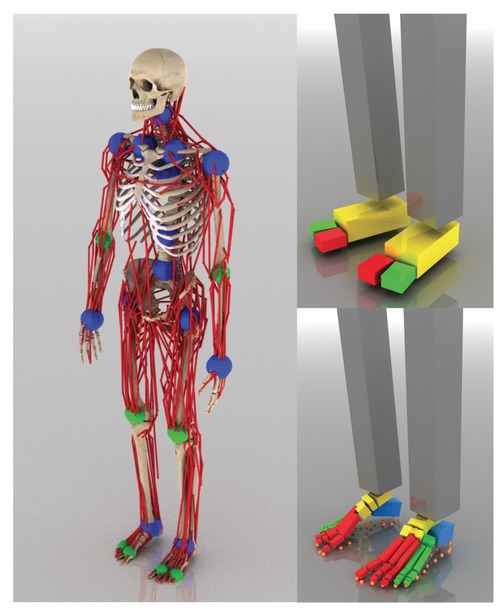
Scalable Muscle-actuated Human Simulation and Control
より現実的な人間の動きを構築するため、それら要因を考慮した最大346の筋腱ユニットの筋収縮で駆動する全身筋骨格モデルとその制御システムを提案する研究。骨と接続した8つの回転関節(膝と肘など)と14の臼状関節(腰、足首、肩、手首など)含む骨格筋に対応する284~346の筋腱ユニットで構成され、deep learningを用い物理シミュレーションで学習。動画
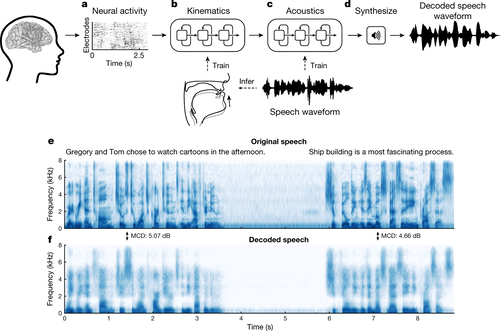
Speech synthesis from neural decoding of spoken sentences
脳活動から声道の動きをシミュレートし音声合成(本人の声に近似)を生成する機械学習を用いたブレインマシンインタフェースを提案する研究。声道の物理的運動(調音動作)が脳内でどのように調整されるのか、脳活動から声道の動きを復元し、そこから本人の声に近似の合成音声へ変換する。動画

Interactive Image Segmentation via Backpropagating Refinement Scheme
画像において物体を背景から分離する対話型画像セグメンテーションアルゴリズムを提案する研究。ユーザ注釈付きオブジェクトのセグメンテーションマスクを効率よく出力できる。動画
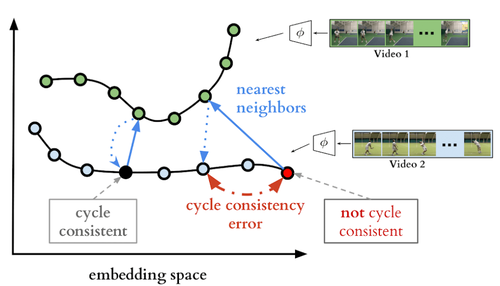
Temporal Cycle-Consistency Learning
複数の映像内のイベントを時間的に整列させる機械学習を用いたフレームワークを「Temporal Cycle Consistency (TCC)」を提案する研究。類似の複数ビデオにまたがって対応関係を見つけ整列させる学習法。動画

DenseBody: Directly Regressing Dense 3D Human Pose and Shape From a Single Color Image
CNNとUVマッピングを組み合わせて1枚の2D画像から人の3Dモデルを生成する中間タスクを省略したフレームワーク「DenseBody」を提案する研究。2D姿勢推定や2Dセグメンテーション、ヒートマップやマスクなどのサブタスクを中間に計算する2段階プロセスを省いた手法。単一RGB画像から身体形状へのマッピングを直接学習する。動画

Exploring Neural Networks with Activation Atlases
画像が提供されたときに、ニューラルネットワークがどのように画像分類するかを可視化するアプローチ「Activation Atlases」を提案する研究。分類途中の画像の集合体をWebページ上に層の数だけ表示。拡大や縮小、誤った分類をする要因を局所的に発見し修正することも可能。動画

SubMe: An Interactive Subtitle System with English Skill Estimation Using Eye Tracking
字幕付き動画を見る視線動向から英語レベルを推定し、各個人に適した英語学習を作成できるシステム「SubMe」を提案する研究。様々な英語レベルユーザの眼球運動をトラッキング。単語ベースではなく、1行ベースで分析。英語レベルが低いユーザの方が字幕への注視数が多く、費やす時間も多い傾向を用い、レベルに合わせた単語の日本語を提示する。動画

SC-FEGAN: Face Editing Generative Adversarial Network with User’s Sketch and Color
顔画像を直感的に編集(マスク、スケッチ、カラー入力)するだけで高品質な合成顔画像を生成する機械学習を用いた手法「SC-FEGAN」を提案する研究。サングラスから目に変更したり、前髪のスケッチで髪の毛のボリュームを加えたり、鼻へのスケッチで変形したり、目への色入力で紫ベースのアイラインを生成したりが可能。
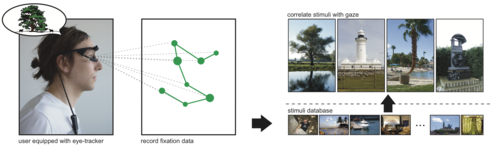
The Mental Image Revealed by Gaze Tracking
画像を思い出している眼球の動きからその画像を特定するCNNを用いた手法を提案する研究。画像を思い出す際に動く眼球運動から特徴点の位置を抽出し、データベース内から最良の画像を一致させる計算を行う。動画
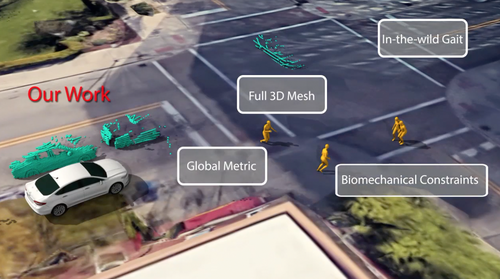
Bio-LSTM: A Biomechanically Inspired Recurrent Neural Network for 3D Pedestrian Pose and Gait Prediction
自動運転車における歩行者の次の動き位置を全身3Dメッシュから推定するシステム「Bio-LSTM」を提案する研究。車両のカメラやLiDAR、GPSからのデータを入力として受け取り、位置とSkinned Multi-Person Linear(SMPL)モデルパラメータで表される歩行者姿勢の全身3Dメッシュを出力する。動画

LiveCap: Real-time Human Performance Capture from Monocular Video
1台のカメラで撮影した映像から、ゆったりと着用する衣服を含めた人の動きをリアルタイムに3D再構築する機械学習を用いたフルボディパフォーマンスキャプチャシステム「LiveCap」を提案する研究。関節のある人の動きと、肌と衣服の非剛性の変形を自動的に推定することで、リアルタイムのフルボディパフォーマンスキャプチャを実現する。動画
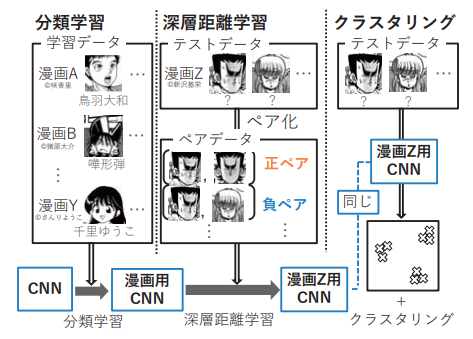
Character Representation Adaption in Individual Manga
漫画内のキャラクタに対して、クラスタリングすることでキャラクタの顔分類を行う手法を提案する研究。漫画内のキャラクタに適応した特徴抽出器を作成するために、最初に教師あり学習によって漫画に汎用性のある特徴抽出器を作成し、その後深層距離学習により漫画内のキャラクタに適応した特徴抽出器を作成、最後に、その特徴抽出器から得られる特徴量に対してK-meansを適用することで分類を行う。

InstaGAN: Instance-aware Image-to-Image Translation
画像内の特定領域をより自然に変換させるGANを用いた手法「InstaGAN」を提案する研究。画像とそれに対応するインスタンス属性のセットの両方を変換するニューラルネットワークアーキテクチャ。

Video Inpainting by Jointly Learning Temporal Structure and Spatial Details
動画の欠落領域を連続的に補完するdeep learningを用いた手法を提案する研究。動画内の各フレーム内の欠けている部分を埋めるだけでなく、連続するフレーム間の一貫性を保つことを可能にする。動画

Brain-inspired automated visual object discovery and detection
断片画像のみから物体の全体像を識別するコンピュータビジョンシステムを提案する研究。椅子の後ろに隠れた犬の足としっぽのみを見ただけで、犬という全体像を思い浮かぶ人間の認識能力を模倣する。
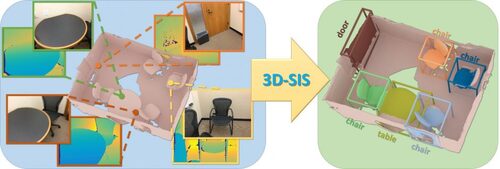
3D-SIS: 3D Semantic Instance Segmentation of RGB-D Scans
RGB-Dセンサから3Dセマンティックセグメンテーションを推定する機械学習を用いた手法「3D-SIS」を提案する研究。RGB-Dセンサで記録したマルチビューを使用して、2Dカラー画像 と3Dジオメトリデータから学習するニューラルネットワーク、オブジェクトバウンディングボックス、クラスラベル、インスタンスマスクを予測する。動画
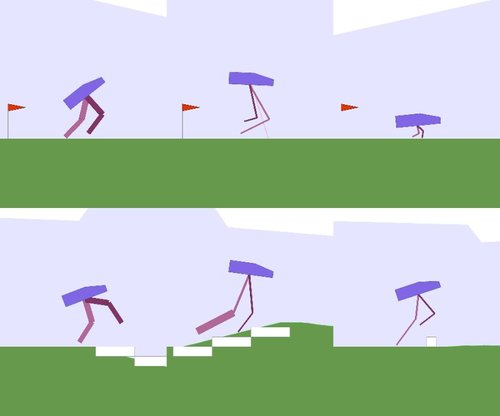
Reinforcement Learning for Improving Agent Design
脳内だけでなく、環境に最適なボディデザインも学習することで、より高いパフォーマンスを達成させる手法を提案する研究。化学習において、報酬を最大化するだけでなく、同時にエージェントのデザインも学習する。

GAN Dissection: Visualizing and Understanding Generative Adversarial Networks
GANにおいて、どのユニットがどのオブジェクトクラスに影響を与えているかを視覚化し理解する分析フレームワークを提案する研究。ユニットレベル、オブジェクトレベル、シーンレベルでGANを視覚化し、GANのプロセスにおいて、何が何に影響を与えているかの因果効果を理解する。動画

HybridFusion: Real-Time Performance CaptureUsing a Single Depth Sensor and Sparse IMUs
1台の深度カメラと慣性計測装置(inertial measurement unit、IMU)を用いて、服を着ている人の全身運動を再構築するパフォーマンスキャプチャシステム「HybridFusion」を提案する研究。動画

Predicting eye movement patterns from fMRI responses to natural scenes
fMRIの活動から眼球運動パターンをCNN(Convolutional Neural Network)を用いて直接予測し、活動マップを元画像にオーバーレイし再構成するアプローチの研究。脳がどのようにこの能力を調整するか、どのように脳がその複雑な計算を素早く実行するか、正確な脳計測を使用して、自然な風景を見るときに人の目がどのように動くかを推定する。

Deep Multispectral Painting Reproduction via Multi-Layer, Custom-Ink Printing
Deep learningとフルカラー&マルチマテリアル3Dプリンタを組み合わせて絵画(油絵等)を再現するRePaintシステムの研究。分光反射率を再現し、フルカラー&マルチマテリアル3Dプリンタを用いて複製できる。動画
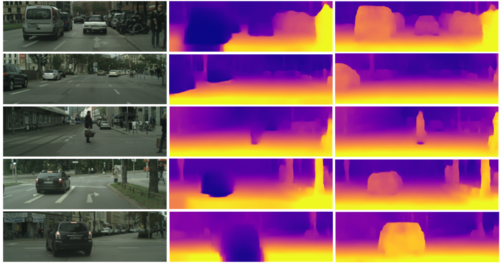
Depth Prediction Without the Sensors: Leveraging Structure for Unsupervised Learning from Monocular Videos
単眼カメラの映像だけから深度とエゴモーションを推定する教師なし学習を用いた手法を提案する研究。シーン内の動的オブジェクト(例:移動する車、人、自転車など)がどこに向かっているかを検出でき、静的オブジェクトでも、潜在的に移動する可能性があるか検出する。

Learning to Dress: Synthesizing Human Dressing Motion via Deep Reinforcement Learning
着衣アニメーションを生成する深層強化学習を用いた手法の研究。人間モデルの関節角と速度、衣服の頂点位置、触覚(衣服の内側と接触しながら着衣するため)、表面情報、タスクベクトルなどを学習する。動画
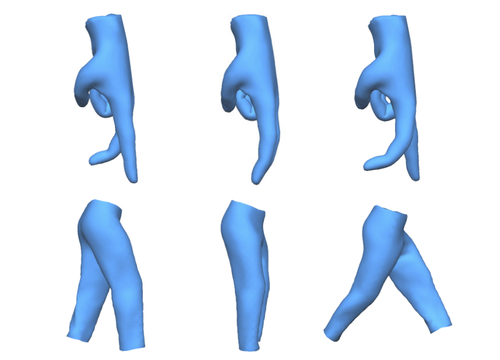
Automatic Unpaired Shape Deformation Transfer
ソース形状からターゲット形状にメッシュ変形を転送するGANを用いたアーキテクチャを提案する研究。例えば、細い人の動作を太い人へ、フラミンゴの動作を人へ、馬の動作を像へ、顔の動作を人へ等を転送する。動画

DeepLens: Shallow Depth Of Field From A Single Image
スマートフォンカメラなどの一般的なカメラで撮影された1枚の画像にDoF(Depth of field:被写界深度)効果を生成する機械学習を用いた手法「DeepLens」を提案する研究。焦点位置やぼかし加減も調整できる。動画
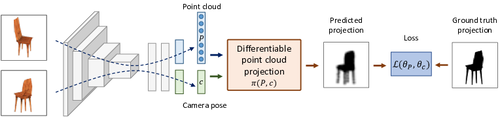
Unsupervised Learning of Shape and Pose with Differentiable Point Clouds
2D投影から、点群表現を用いて3D物体の姿勢と形状を学習する手法の研究。同じオブジェクトの2つのビューを入力に、対応する形状(点群として表される)とカメラの姿勢を予測し、投影モジュールを使用して予測されたカメラポーズから推定された形状のビューを生成する。動画
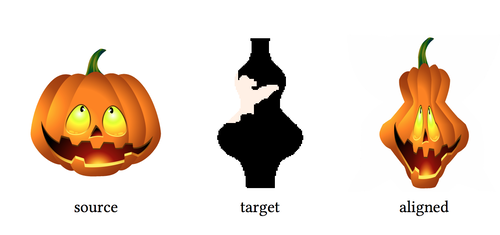
ALIGNet: Partial-Shape Agnostic Alignment via Unsupervised Learning
ソース形状を別のターゲット形状に合わせ調整することで新しいインスタンスを生成するCNNを用いた手法「ALIGNet」を提案する研究。ソース形状とターゲット形状のランダムなペアから、教師なしの訓練スキームを介して、FFDグリッドを計算することを学び、入力のソースとターゲット形状の間のマッピングを学習する。

CariGANs: Unpaired Photo-to-Caricature Translation
ペアになっていない1枚の顔写真から似顔絵を生成する敵対的生成ネットワークGANを用いた手法の研究。パラメータを調整もしくはカリカチュアの例を与えることで、カラーやテクスチャのスタイルも変更できる。

Single-Image SVBRDF Capture with a Rendering-Aware Deep Network
1枚の写真からdeep learningを用いてSVBRDFを推定しモデリングする手法の研究。ピクセルごとのノーマル、拡散アルベド、鏡面アルベド、物質表面の粗さに対応する4つのマップを予測する。

Relighting Humans: Occlusion-Aware Inverse Rendering for Full-Body Human Images
服を着た人の全身画像1枚とそのマスクから、CNNを用いて、どのような陰影(明るい部分や暗い部分)になるかを推定し再現する研究。反射率や照明だけでなく、画素ごとに光の遮蔽を9次元の球面調和関数 (spherical harmonics; SH) の係数として符号化した光伝達マップも推定。様々な照明環境下で、人物画像の再照明をより写実的に実現する。動画

PhotoShape: Photorealistic Materials for Large-Scale Shape Collections
既存の3D形状に対して、各部分にSV-BRDFによるマテリアルを自動的に割り当てるdeep learningを用いたテクスチャリング・システム「PhotoShape」の研究。3D形状に対して、自動的にフォトリアリスティックなテクスチャを割り当てるフレームワークを提案し、写実的で再現性のある3D形状を大量に生成する。動画

SFV: Reinforcement Learning of Physical Skills from Videos
動画内のアクロバットな動きから、その動きをキャラクタが習得するdeep learningを用いた手法の研究。単眼で撮影された通常の動画からアクロバットなスキル(動画内の人の動き)の姿勢推定から始まり、物理的なシミュレーションでスキルを再現し学習する。動画
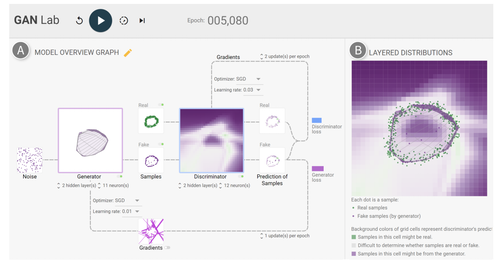
GAN Lab: Understanding Complex Deep Generative Models using Interactive Visual Experimentation
GANの学習プロセスをリアルタイムに可視化するWebブラウザベースの対話型視覚化ツール「GAN Lab」の研究。TensorFlow.jsを使用し実装されており、Webブラウザを介して行える。任意のパラメータに変更も可能。動画

3D Hair Synthesis Using Volumetric Variational Autoencoders
1枚の画像から3Dヘアを再構築するdeep learningを用いたモデリング法の研究。予測された髪の向きと髪型の概形に基づき、ストランドを頭部モデルの頭皮から成長させ毛髪の束を合成する。動画

Learning a Shared Shape Space for Multimodal Garment Design
衣服の2Dスケッチから折り目(ひだ)付きの3D衣服を任意の身体に合わせて生成できる手法の研究。折り目パターンを含む衣服スケッチから、2D衣服の縫製パターンと3Dボディ形状パラメータを自動的に推測し、取得したパラメータからドレープされた3D衣服形状を予測する。出来上がった衣服は、元のスタイル(折り目パターン、シルエットなど)を維持しながら、異なる身体形状にリターゲットも可能。動画

複数人の2Dポーズをリアルタイムに高速検出する「Pose Proposal Networks(PPN)」の研究。 リサイズ後の入力画像からRegion proposal (RP/物体領域候補予測) フレームワークで身体部位のバウンディングボックスを検出し、CNNを使って部位を検出する。動画

顔のエッジ映像から様々なリアル顔映像に変換するGANを用いた手法の研究。 セグメンテーションマスクから背景や自動車を出力、顔のエッジマップから人物の顔を出力、ポーズから人の踊りを出力、ビデオからビデオへの変換が可能となる。動画

Robust Flow-Guided Neural Prediction for Sketch-Based Freeform Surface Modeling
手書きの2Dスケッチから3DサーフェスをモデリングするCNNを用いた手法の研究。 入力であるスケッチ図(深度ポイント、曲率のヒント等含む)をもとに、DFNetを用いて表面の曲率方向を決める流れ場を回帰し、GeomNetを用いて深度マップおよび法線マップを生成する。動画

Deep Inertial Poser: Learning to Reconstruct Human Pose from Sparse Inertial Measurements in Real Time
6つの慣性計測装置(IMU)のみを全身に装着し、リアルタイムの3D姿勢推定を実行するdeep learningを用いた手法「DIP(Deep Inertial Poser)」の研究。動画
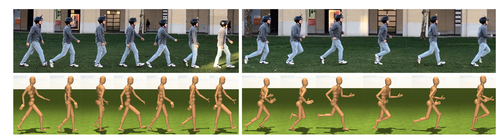
3D Ego-Pose Estimation via Imitation Learning
頭に取り付けた1台のカメラからの一人称視点映像で本人の3Dポーズを推定する模倣学習を用いた手法の研究。モーションキャプチャデータ、ヒューマノイドモデル、物理シミュレータを活用した模倣学習法を採用。動画

Towards Learning a Realistic Rendering of Human Behavior
ビデオ内の人の動きを、別の人の外観に置き換えて同じ動きをさせるdeep learningを用いた手法の研究。動画

Recycle-GAN: Unsupervised Video Retargeting
別のビデオスタイルに動画を自動的に変換するGAN(Generative Adversarial Network)を用いたビデオリターゲット技術「Recycle-GAN」の研究。顔の表情と動きを人物から別の人物(またはキャラクタ)に変換、白黒フィルムをカラーに変換、花の開花を別の花へ変換、風が強い風景動画を穏やかな風の風景動画に変換、などが可能。動画

Neural Animation and Reenactment of Human Actor Videos
ビデオ内の人の動きだけを別のビデオ内の人に転送するconditional GANを用いた手法の研究。事前に3Dモデルを作成し、動きと組み合わせて実現する。動画

異なるビデオ内の人物間の動きを転送する機械学習を用いた手法の研究。ソースビデオ内の人の動きをターゲットビデオ内の人へ転送し、外見はそのままに動作だけを入れ替える。GANを用い、合成ビデオの精度を上げる。動画

画像の前景オブジェクトと背景を分離し再合成するCNNを用いた手法の研究。入力である元画像のテクスチャと色情報を分析し、訓練されたCNNと組み合わせることで、その画像内のオブジェクトが実際に何であるかを区別する。動画

Real-Time Hair Rendering using Sequential Adversarial Networks
参考画像から髪の色具合を3Dモデルへ適用できるGANを用いた3Dヘアレンダリングの研究。自然な髪の画像を入力に、髪の色、照明、繊維レベルの構造へ分解しエンコード、毛髪を逆順で適用していき現実的なCGモデルを再構築する。動画

Learning Basketball Dribbling Skills Using Trajectory Optimization and Deep Reinforcement Learning
バスケットボールをするコンピュータアニメーションキャラクタをより現実的に表現する深層強化学習を用いた物理ベースの手法の研究。足の間をドリブル、背中の周囲にボールを回す、などを学習し、スキルから別のスキルへの移行方法も学習。 正確なボールの動きと、それに合った腕などの動きを生成する。動画

DeepWrinkles: Accurate and Realistic Clothing Modelin
動きに合わせて自然なシワも表現するより現実的な衣服の再構築法「DeepWrinkles」の研究。 4Dスキャンから現実的な衣服の変形を生成するための機械学習フレームワーク。 全体的な形状と細かなシワなどを回復できるより現実的な衣服の変形を取得する。動画

Predicting Gaze in Egocentric Video by Learning Task-dependent Attention Transition
一人称視点ビデオにおいて、注視を予測し可視化する機械学習を用いた手法の研究。2つのモジュールを融合し、 最終的な注視マップを生成、一人称視点ビデオにおける注視予測を出力する。動画
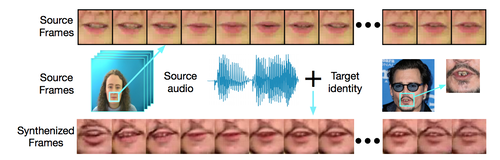
Lip Movements Generation at a Glance
音声スピーチに合わせて唇画像を動作させる機械学習を用いた手法の研究。ソース音声とターゲット画像を合成し、人物のアイデンティティを保持しながらリアルに描写する。動画
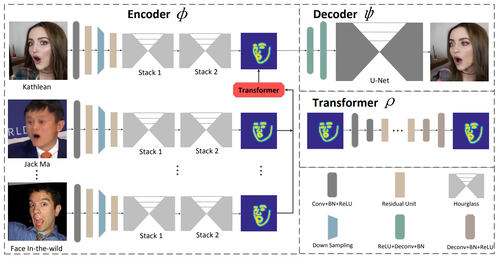
ReenactGAN: Learning to Reenact Faces via Boundary Transfer
動画内の人物へ別の顔の表情や動きを転送し再構築する機械学習フレームワーク「ReenactGAN」を提案する研究。動画

Predictive and Generative Neural Networks for Object Functionality
単一の3Dオブジェクトに対してどのように相互作用するかの機能性を推定し可視化する手法の研究。単一の3Dオブジェクトに対しての機能性を推定し、周囲のオブジェクトとどのように相互作用するかを示すシーンを生成するニューラルネットワークアーキテクチャ。

Non-Stationary Texture Synthesis by Adversarial Expansion
見本のテクスチャから類似したより大規模で現実的なテクスチャに拡張するGANを用いたテクスチャ合成法の研究。見本テクスチャ同士の融合も可能。生成した大規模テクスチャをシャッフルして、動いているように見せることも可。

Finding Tiny Faces in the Wild with Generative Adversarial Network
画像内の小さくぼやけた顔も検出するGANを用いた手法の研究。画像中の10×10ピクセルほどの小さな顔でも高解像度の顔に生成するアルゴリズムを使用する。

SketchyGAN: Towards Diverse and Realistic Sketch to Image Synthesis
人が描いたスケッチから現実的な写真を生成する機械学習を用いた手法の研究。似た画像を検索してくるのではなく、スケッチから新しい画像を生成する。

Noise2Noise: Learning Image Restoration without Clean Data
画像のノイズやアーティファクト、フィルムグレイン等を除去するDeep learningを用いた手法の研究。ノイズの多い画像とクリーンな画像のペアを使用するのではなく、ノイズ画像のみを用いて同等またはそれに近いパフォーマンスで自動的に除去し写真を強化する。動画
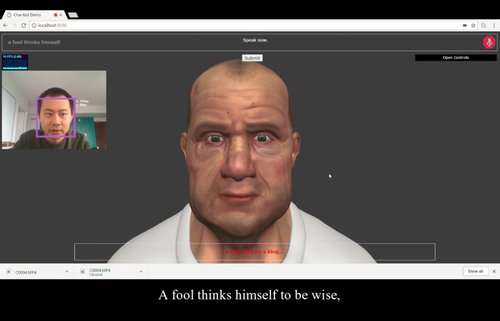
A Face-to-Face Neural Conversation Model
テキストもしくは動画による会話文の入力に対して、自然言語による返答と、同時にそれに合う適切な顔のジェスチャを生成するニューラルネットワークモデルを提案する研究。ボットとの会話のために、テキスト情報と顔情報の両方を用いた適切な応答の生成を可能に。動画
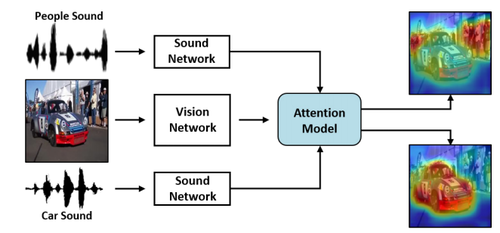
Learning to Localize Sound Source in Visual Scenes
画像や動画内のどこから音が鳴っているかの音源を推定する機械学習を用いた手法の研究。画像と音のペアから、その音源が画像中のどこから鳴っているかの音の視覚情報をヒートマップで提示する。動画

Who’s Better? Who’s Best? Pairwise Deep Ranking for Skill Determination
2つの動画内で行われている技能(手術、絵を描く、ピザ生地をこねる、箸を使う)を評価し、どちらが上手かを推定するCNNを用いた手法の研究。

Tracking Emerges by Colorizing Videos
ビデオ内の特定のオブジェクトに追跡し色付けする技術の研究。白黒ビデオの特定のオブジェクトを追跡し、色付けする機械学習を用いた手法。コンピュータビジョンにおけるビジュアルトラッキングに役立てる。
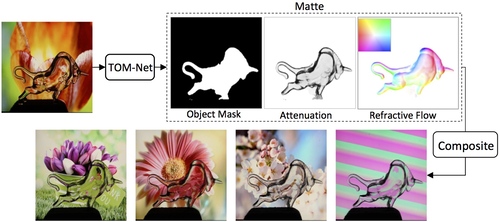
TOM-Net: Learning Transparent Object Matting from a Single Image
1枚の画像からガラスのような透明オブジェクトを切り抜き、新しい背景画像に反射特性含めより自然に合成するCNNアーキテクチャの研究。876の透明オブジェクトデータセットを作成。1枚の画像から反射特性を保存しながら前景オブジェクトを新しい背景画像にレンダリングさせる。動画
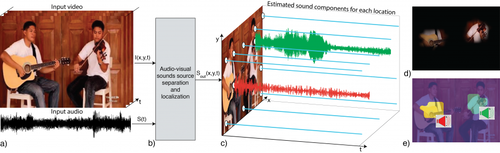
音楽ビデオから特定の楽器音だけを分離する教師なし学習アーキテクチャ「PixelPlayer」の研究。動画から音を生成する画像領域を見つけ出し、特定の楽器の音を分離する。20以上の一般的に見られる楽器の音を識別できる。動画

ScanComplete: Large-Scale Scene Completion and Semantic Segmentation for 3D Scans
屋内シーンの深度データを入力に、CNNを用いて欠落部分を推定、ラベル付きボクセルの3Dモデルを生成する手法の研究。動画
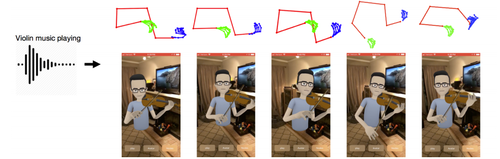
ニューラルネットワークを用いて、バイオリンやピアノ演奏のオーディオ入力からアバタの動きを推定するシステムの研究。 各ビデオの各フレームの上体と指を検出し、オーディオ機能と身体骨格のランドマークとの相関を学習ネットワークを構築。 音声信号から身体のジェスチャを予測する。動画

DensePose: Dense Human Pose Estimation In The Wild
人間の姿勢を2D画像から推定し、人体の表面にテクスチャをマッピングできる機械学習を用いたシステム「DensePose」の研究。 複数人が密集した2D画像から人体それぞれの3Dモデルを計算し、画像ピクセルを人体のサーフェス座標に関連付ける。動画
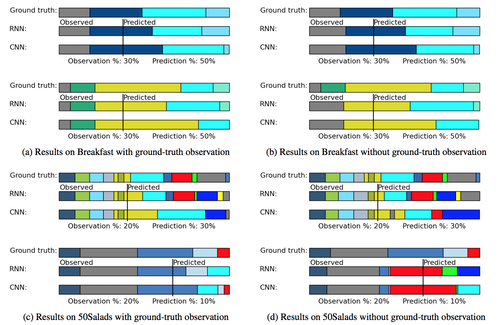
When will you do what? – Anticipating Temporal Occurrences of Activities
人の将来の行動予測(活動のタイミングと継続時間)を推定する機械学習システムの研究。5分以内に起こるすべての行動を推定する。例えば、料理の一連の動作をビデオシーケンスから学習し、新しい状況において調理人がいつどの時点で何を行うのかを予測するなど。動画

Through-Wall Human Pose Estimation Using Radio Signals
壁などに隠れる人の姿勢を推定するニューラルネットワークシステムの研究。低電力のワイヤレスRF信号(WiFiより1000倍低電力)を送信し、環境からの反射を受信し分析、人間の骨格を推定する。動画

Fast and Deep Deformation Approximations
deep learningを用いて、モバイル上でキャラクタを高品質かつリアルタイムに動かすキャラクタリグ技術の研究。メッシュ変形に必要な時間を短縮し計算量を削減する。
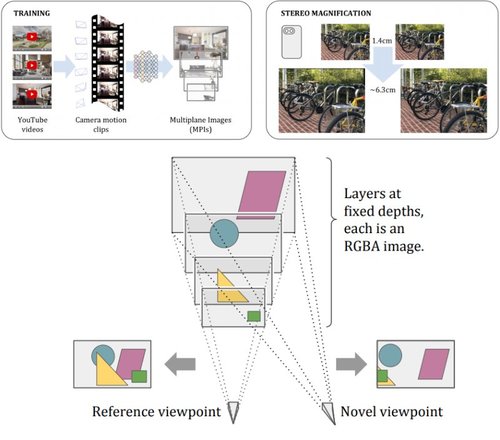
Stereo Magnification: Learning view synthesis using multiplane images
ステレオカメラ、VRカメラ、iPhone 7/Xなどのデュアルレンズカメラで撮影した画像から奥行き感ある現実的なビューを作成エンドツーエンドのDeep learningフレームワークの研究。動画

機械学習を用いて、ソースビデオの人物(顔)からターゲットビデオの人物(顔)へ転送し、3Dアニメーションを再構築するアプローチの研究。ソースビデオの人物がターゲットビデオの人物のアイデンティティと外観を維持しながら、頭部姿勢、顔の表情、目の動きや瞬きを制御する。動画
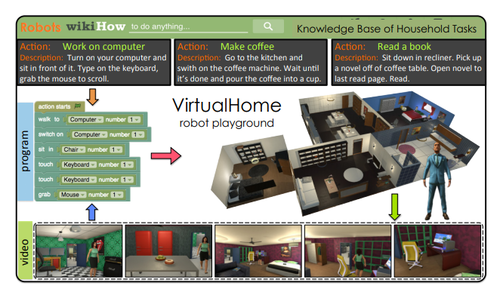
VirtualHome: Simulating Household Activities via Programs
ロボットに家事などの日常的なタスクを学習させる3Dシミュレータ「VirtualHome」の研究。「コーヒーを作る」などのさまざまなアクション約3,000のプログラムを使用してシステムを訓練する。動画

InverseFaceNet:Deep Single-Shot Inverse Face Rendering From A Single Image
1枚の画像から顔の姿勢、形状、反射率、照明を推定し再構築するDeep learningを用いたインバースレンダリング法の研究。動画

Mode-Adaptive Neural Networks for Quadruped Motion Control
ニューラルネットワークを用いて、より現実的に滑かな動きを実現する四足歩行キャラクタのリアルタイム制御技術の研究。27本の骨格モデルと81自由度。リアルタイムに四足歩行キャラクターのアニメーションを生成する。動画
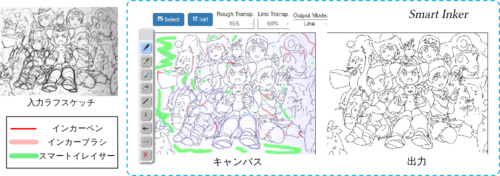
Real-Time Data-Driven Interactive Rough Sketch Inking
機械学習を用いて対話的にラフスケッチのペン入れができる編集ツールの研究。途切れた線を自然につなぎ、不要な線を効率的に消し、自動出力された線画を効果的に修正することが可能。動画
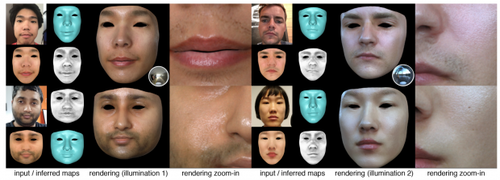
High-Fidelity Facial Reflectance and Geometry Inference From an Unconstrained Image
1枚の顔画像から顔の形状と反射率をCNNを用いて推定しモデル化する手法の研究。1枚の画像からより現実的な3D顔面モデルを生成する。動画

Neural Best-Buddies: Sparse Cross-Domain Correspondence
2枚のペア画像から重要な特徴だけをCNNを用いて検索し抽出、共通の外観を持たない画像間の対応付けを可能にする手法の研究。これにより、結合画像の作成、自動画像モーフィングなど、外見が異なるオブジェクト同士の自然なハイブリッド画像作成を可能にする。動画
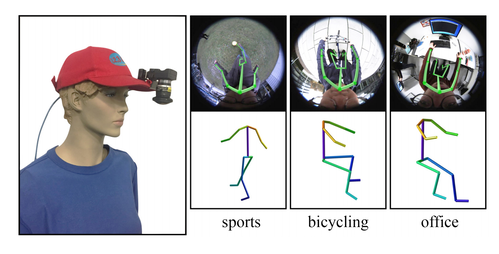
Mo2Cap2: Real-time Mobile 3D Motion Capture with a Cap-mounted Fisheye Camera
帽子の1台の魚眼カメラを下向きに装着し自身の体をリアルタイムに3D姿勢推定する手法の研究。これにより、自分の動きを3Dでキャプチャできる。

MonoPerfCap: Human Performance Capture from Monocular Video
1台の単眼カメラで撮影した映像を入力に、人間のポーズから着用する衣服までを3D再構築するマーカレスパフォーマンスキャプチャ技術「MonoPerfCap」の研究。 人の姿勢推定だけでなく、着用する衣服などの動きも再構築、自由な視点でレンダリング可能。動画

機械学習を用いて暗い環境で撮られた画像を修正するためのデータセットと手法の研究。 露出が少ない状態で撮影された暗い写真(低光量画像)を修正する。動画

Probabilistic plant modeling via multi-view image-to-image translation
植物を複数方向から撮影した画像から、植物の3次元「枝構造」を正確に再現するDeep learningを用いた手法の研究。 各画像(葉つきの植物画像)を画像変換により枝の存在確率を表す画像に変換し、これを使って三次元復元を行う。動画

From Faces to Outdoor Light Probes
自然光の屋外撮影した顔写真(LDR)を多様な照明環境条件(HDR)に対応の顔写真に変換できるライトプローブ推定技術の研究。ライトプローブを推定し、対応するHDR環境マップに合わせて顔をレンダリング、環境に合わせた顔写真に仕上げる。

Image Inpainting for Irregular Holes Using Partial Convolutions
画像内の一部を削除し修復するDeep learningを用いた画像修復法の研究。 画像内の修正したい箇所をマスクし、除去したあとを自然に見せる代替を生成し再構築する。 不規則な形状のマスクでも画像修復できる。動画

Multimodal Unsupervised Image-to-Image Translation
1枚の画像を多様な画像に変換するGANを用いたフレームワークの研究。猫を犬に、猫をトラやライオンに変換する。 動画
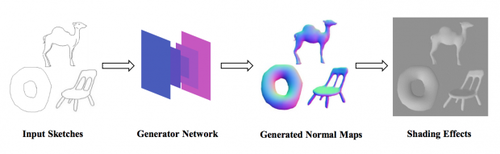
Interactive Sketch-Based Normal Map Generation with Deep Neural Networks
ニューラルネットワークを用いて、2D手書きスケッチからリアルタイムに法線マッピング(ノーマルマッピング)を生成するインタラクティブシステムの研究。動画

FaceForensics: A Large-scale Video Dataset for Forgery Detection in Human Faces
動画における人の顔の偽造を検出するDeep learningを用いた手法「FaceForensics」の研究。 目視では見破ることが困難な偽ビデオ を見抜くため訓練する。データセットも独自で作成。動画
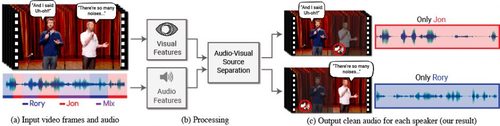
Looking to Listen at the Cocktail Party: A Speaker-Independent Audio-Visual Model for Speech Separation
複数音から特定の発話者だけの声を聞こえるようにするDeep learningを用いた視聴覚音声分離モデルの研究。複数の音から1人の音声だけを抜き出す。入力ビデオの聴覚信号と視覚信号の両方から分析しているのが特徴。動画
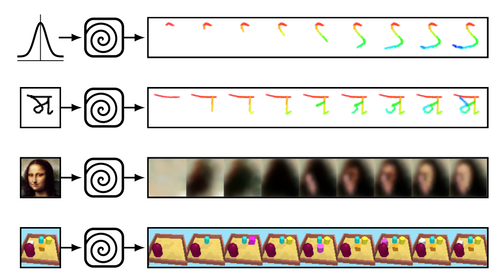
Synthesizing Programs for Images using Reinforced Adversarial Learning
数字、文字、肖像画などを描くときのブラシストロークを機械学習を用いて推定する研究。文字や画像などを描く時のブラシストロークを強化学習を用いて敵対的に訓練する。動画
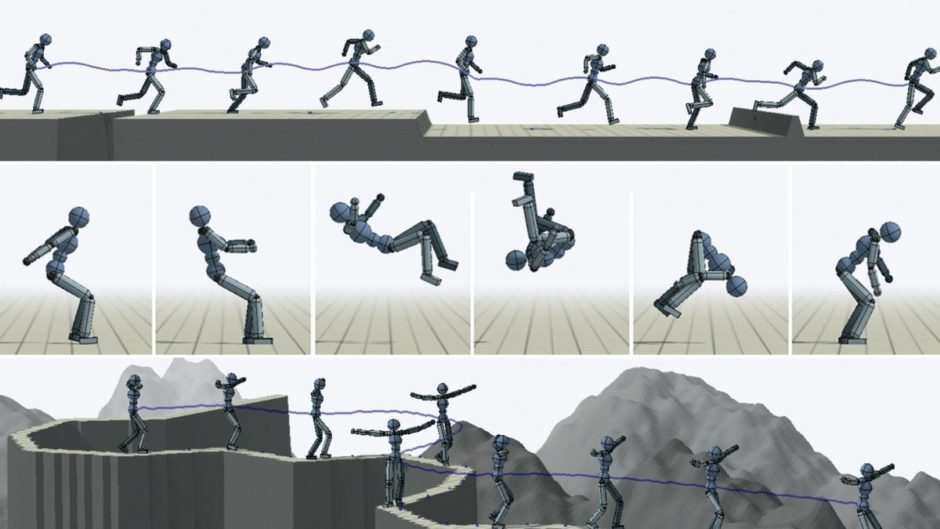
DeepMimic: Example-Guided Deep Reinforcement Learning of Physics-Based Character Skills
バーチャルキャラクタのアクロバットな動きをよりリアルに再現する強化学習を用いた手法「DeepMimic」を発表。フレームワークにキャラクタ、参照動作(基準動作)、タスク(目的の動き)を与え、ベースとなる参照動作を模倣しながらタスク実行を学習する。動画

Multimodal Explanations: Justifying Decisions and Pointing to the Evidence
画像に関する質問に回答し、その根拠を文字で説明、さらに根拠となる箇所を画像内で視覚的に示すニューラルネットワークモデルの研究。
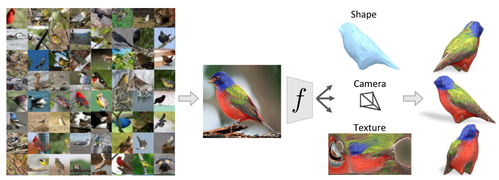
Learning Category-Specific Mesh Reconstruction from Image Collections
単一の画像から物体の3D構造を推定するCNNを用いたフレームワークの研究。学習したモデルは、オブジェクトの形状、カメラのポーズ、テクスチャを推定する。動画
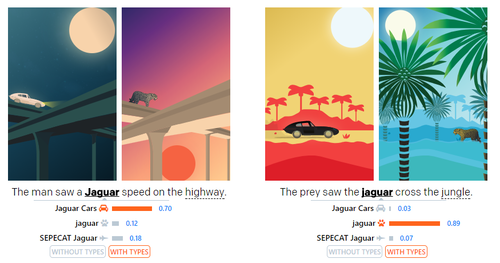
DeepType: Multilingual Entity Linking by Neural Type System Evolution
コンテキスト(文章の前後の脈絡、文脈)から単語の意味を予測するWikipediaを基にしたニューラルネットワークシステム「DeepType」の研究。

Deep image reconstruction from human brain activity
fMRI(機能的磁気共鳴画像法)によって測定された人間の脳活動のみから機械学習を用いて視覚像を再構成する研究。心の中でイメージした内容の画像化にも成功。動画

AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks
テキストによる説明文から画像を生成する敵対生成学習を用いた手法の研究。例えば、黄色い体、黒い翼、短いくちばしの鳥といったキャプションをテキストで記述したとして、画像のように生成する。

Sketch2Normal: Deep Networks for Normal Map Generation
手描きスケッチから法線マッピングを推論する敵対生成学習(Wasserstein GAN)を用いた手法の研究。

End-to-end Recovery of Human Shape and Pose
敵対的学習を用いて1枚の画像から自然な人体3Dモデルを再構成する研究。不自然な関節の曲がり方をしない角度制限や、細すぎる体など不自然な体型にしない制限などを学習し、より自然な人体3Dモデルを生成する。動画

Interactive Example-Based Terrain Authoring with Conditional Generative Adversarial Networks
直感的なユーザ入力で現実的なバーチャル地形を作成できるGANを用いたオーサリングツールの研究。 簡単なスケッチ入力から地形をモデリングする。動画
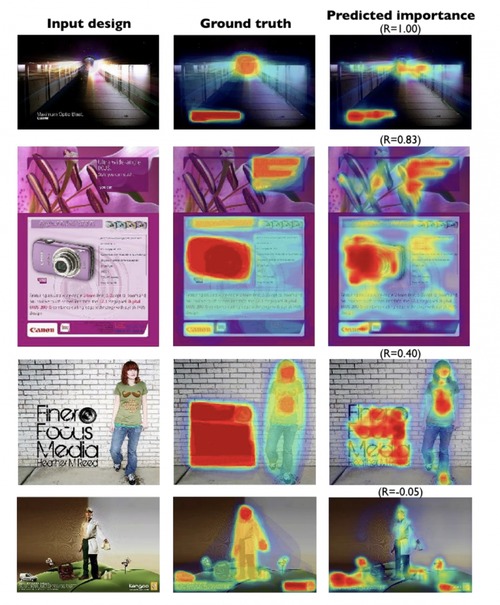
Learning Visual Importance for Graphic Designs and Data Visualizations
ポスターや広告などのグラフィックデザイン、データを視覚化した資料、この2つにおいて、人がその範囲内でどう見ているかを重要度ヒートマップでフィードバック提供してくれる相対的重要度を予測するニューラルネットワークモデルの研究。動画

Visual to Sound: Generating Natural Sound for Videos in the Wild
機械学習を用いてリアル音と見分けがつかない短い動画用の音を生成する研究。短いビデオクリップ用の現実的なサウンドトラックを生成する。
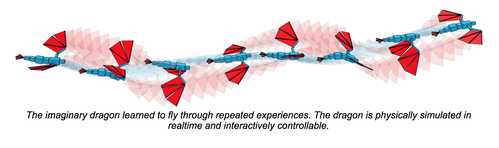
How to Train Your Dragon: Example-Guided Control of Flapping Flight
物理シミュレーションと機械学習を用いて、バーチャル飛行生物が空気力学的に自ら動く方法を学習するコンピュータアルゴリズムの研究。 急上昇、滑空、ホバリングなどの様々な運動スキルを身につけ、障害物にぶつからず自在に飛ぶことが可能。動画

Unsupervised Image-to-Image Translation Networks
インプットした画像を、異なるドメインに対応する画像に変換し出力する手法の研究。 例えば、冬のシーンを入力し同じ場所の夏のシーンを出力、晴れのシーンを入力し同じ場所の雨のシーンを出力、など。動画

Computational Foresight: Forecasting Human Body Motion in Real-time for Reducing Delays in Interactive System
機械学習を用いて0.5秒後の運動をリアルタイム推定する体動予測システムの研究。Kinectを用いて人間の動きを測定し、ニューラルネットワークを用いて、リアルタイムに0.5秒後の人間の動きを推定し出力する。動画

Everyday Eye Contact Detection Using Unsupervised Gaze Target Discovery
1台のカメラだけで任意の対象物がどれだけ注視されてるかをリアルタイム検出する機械学習を用いたアイコンタクト検出手法の研究。 カメラから顔と顔のランドマークを検出、視線の方向を推定 する。屋外でも複数人でもデータを取得可能。動画

Large Pose 3D Face Reconstruction from a Single Image via Direct Volumetric CNN Regression
1枚の2D顔写真から3D顔モデルを機械学習を用いて作成する研究。 60,000枚以上の2D写真と3D顔モデルデータセットをCNNで訓練した。