ロチェスター大学と武漢大学の研究者らは、音声に合わせて唇画像を動作させる機会学習を用いた手法を発表しました。
論文:Lip Movements Generation at a Glance
著者:Lele Chen, Zhiheng Li, Ross K. Maddox, Zhiyao Duan, Chenliang Xu
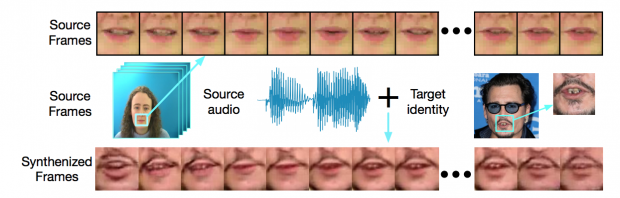
(女性の音声スピーチと男性の唇画像を合成)
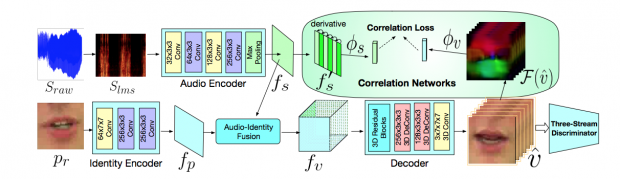
本稿は、任意の音声スピーチから、与えられた唇画像を合成してスピーチに合った唇運動を生成する手法を提案します。ソース音声とターゲット画像を合成し、人物のアイデンティティと共に画像の一貫性を保持しながらリアルに描写することを目指します。
本提案手法は、音声と唇を入力に、Audio-Identity fusion networkで特徴を融合し、Correlation Networkで音声と唇の遅延部分の強化を行い、ThreeStream discriminator(GAN)で生成されたビデオか実際のビデオかを識別し精度を高めます。