KAIST、MIT CSAIL、カリフォルニア・マーセッド大学の研究者らは、画像シーンとその音声から画像のどこから音が鳴っているかの音源を推定する機械学習を用いた手法を発表しました。
論文:Learning to Localize Sound Source in Visual Scenes
著者:Arda Senocak, Tae-Hyun Oh, Junsik Kim, Ming-Hsuan Yang, In So Kweon
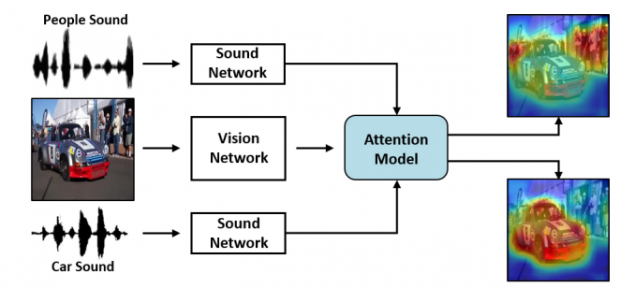
本稿は、画像と音のペアから、その音源が画像中のどこから鳴っているかの音の視覚情報を教師なし学習で推定するアーキテクチャを提案します。
本提案手法は、two-streamネットワークアーキテクチャを用いており、サウンドネットワーク、ビジュアルネットワーク、アテンションモデルの3つのコンポーネントから構成されます。サウンドネットワークとビジュアルネットワークの情報を統合し、ローカライゼーションネットワークで音源位置を生成します。
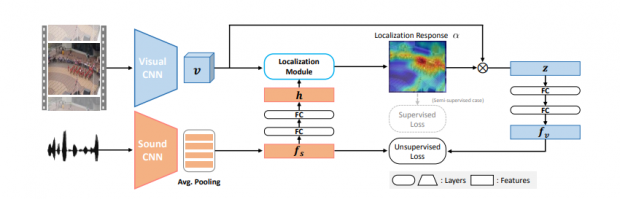
これらのことで、画像と音のペアから音源位置の一部を視覚化することを可能にし、画像内の音の種類によってインタラクティブに変更することもできます。
また、本ネットワークの精度を補強するという意味で、半教師付き学習を用いて向上させています。著者はこう述べます。「ハトの迷信行動」と同じことがネットワークでも起きたからだと。
「ハトの迷信行動」とは、定期的な時間間隔で餌を与える箱にハトを入れておくという実験で、ハトは餌が与えられるとその時に行っていた行動(羽をばたつかせるとか首をかしげるとか等)をトリガーだと勘違いし、何度も繰り返しているうちに、その行動が餌がもらえるトリガーだと信用する、このプロセスが人間が迷信を信じる課程と似ているためそう呼ばれるようになりました。
つまり、この現象がニューラルネットワークでも起こったため、音声付きのビデオを見るだけでは完全に学習することはできず、誤った結論を修正するためには少人数の事前知識を必要とすると。