スタンフォード大学やUberATGなどによる研究チームは、単眼カメラから人の動きと物体との相互作用における因果関係を学習する機械学習モデルを発表しました。
論文:Learning a Generative Model for Multi-Step Human-Object Interactions from Videos
著者:He Wang, Sören Pirk, Ersin Yumer, Vladimir G. Kim, Ozan Sener, Srinath Sridhar, Leonidas J. Guibas
所属:Stanford University, Uber ATG, Adobe Research, Intel Labs
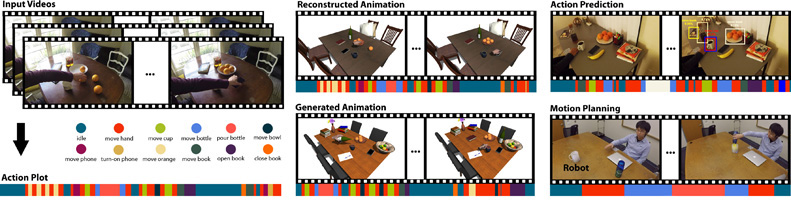
本論文は、単眼カメラのRGBビデオから人間の手の動きとオブジェクトとの相互作用における因果関係を学習することによって、多様なマルチステップインタラクションを再構築するために使用できる生成モデルを提案します。
本提案手法は、相互作用を符号化するため、そのアクションの含まれるオブジェクト、オブジェクトの状態、およびそれらの因果関係を記述するアクションプロットを作成し、アクションプロットを使用して、Recurrent Neural Network(RNN)からモデルを訓練します。

訓練したモデルを使用することで、インタラクション予測やアニメーション合成、ロボット行動計画などのアプリケーション作成に活かすことができます。映像では、将来の行動予測として、ユーザがコップを欲しい時にロボットエージェントが移動して手元に動いてくるといったことをデモンストレーションを披露します。