ハーバード大学と高麗大学校による研究チームは、画像において物体を背景から分離する対話型画像セグメンテーションアルゴリズムを発表しました。
論文:Interactive Image Segmentation via Backpropagating Refinement Scheme
著者:Won-Dong Jang, Chang-Su Kim
所属:Harvard University Cambridge, MA, Korea UniversityRepublic of Korea
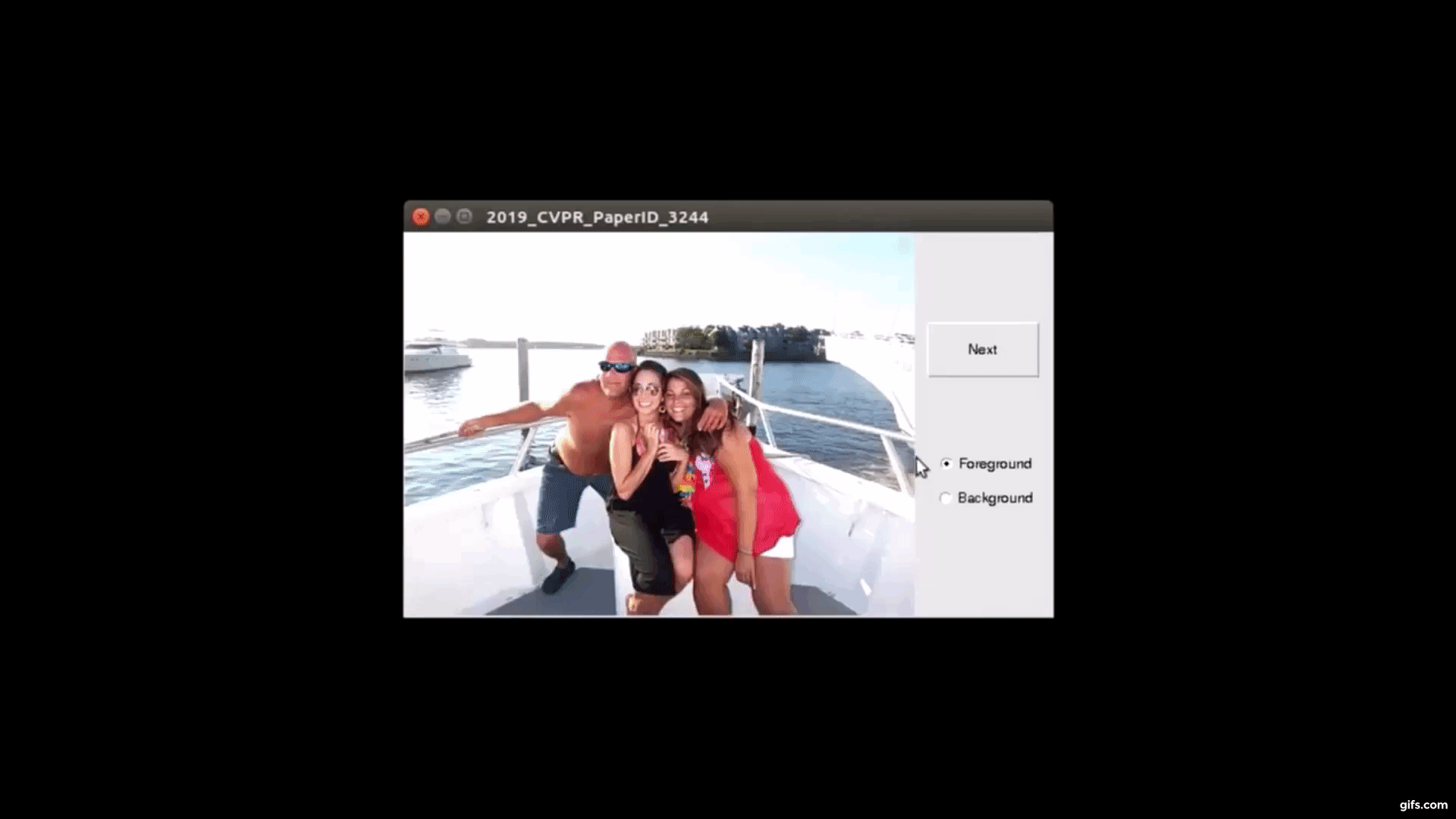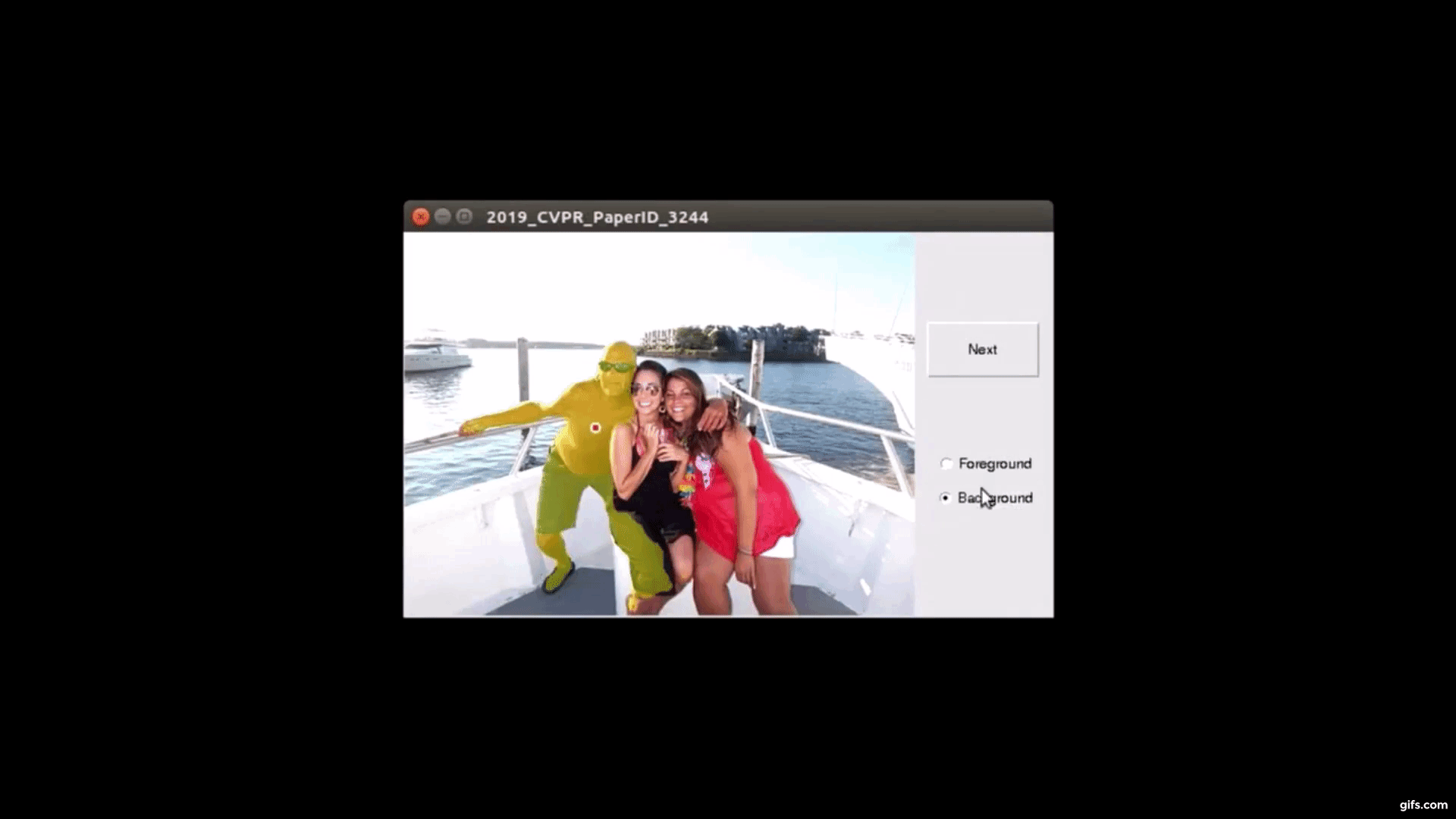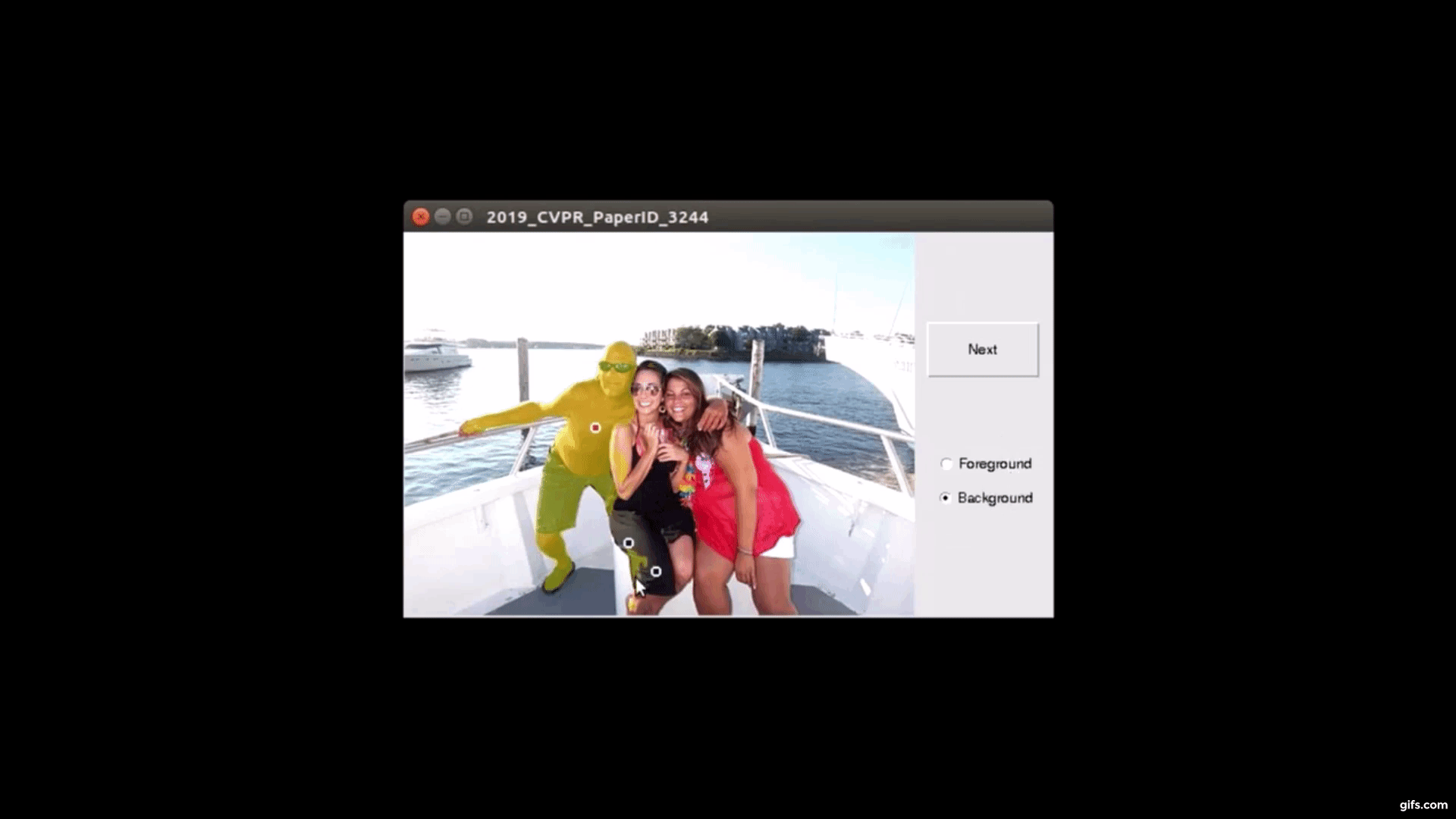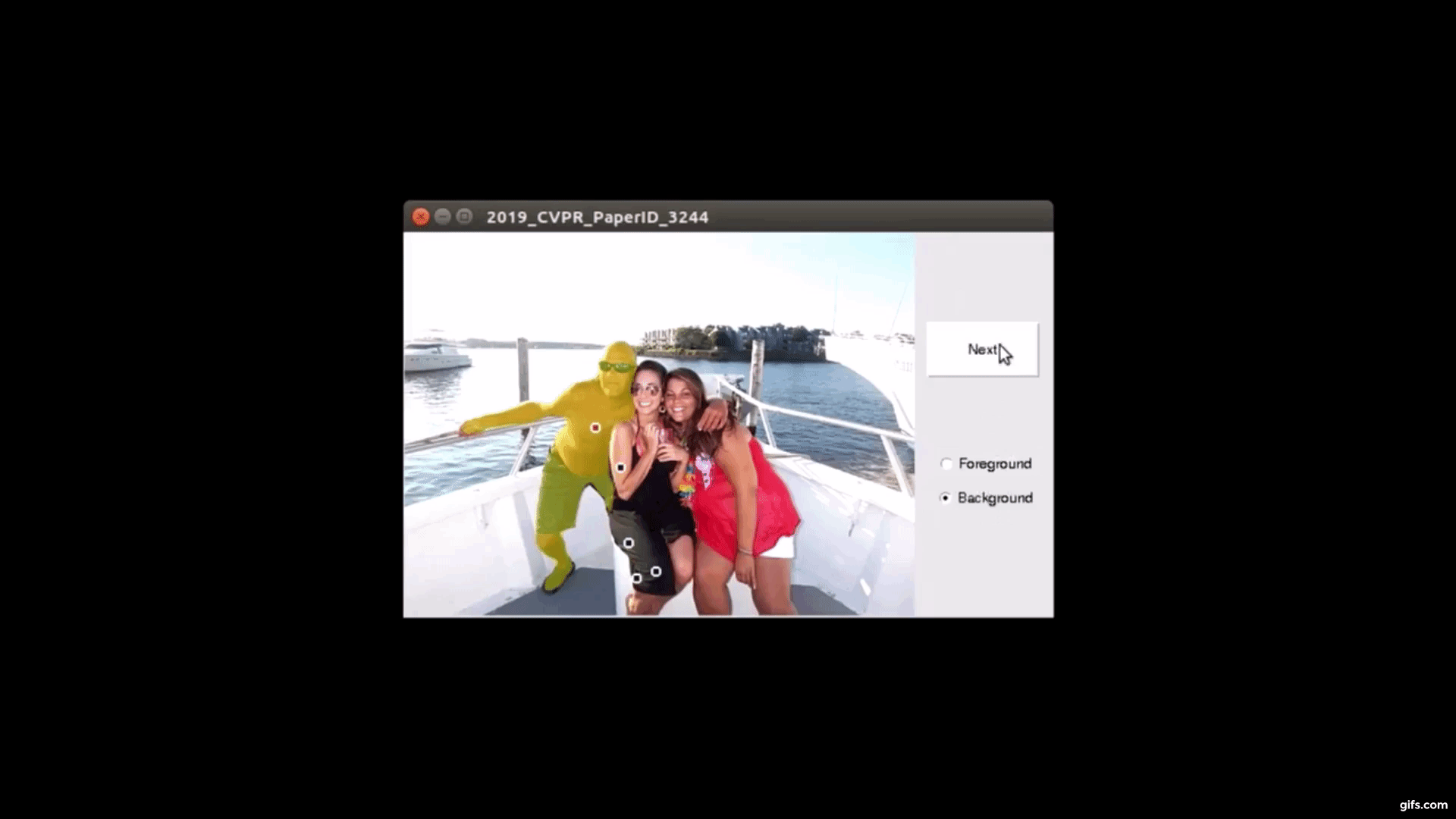
対話型画像セグメンテーションとは、ターゲットオブジェクト(または前景)を背景から分離するタスクです。タスク処理した画像データセットは、学習において活用されます。そのため、膨大な画像が必要な訓練用データセットでは、正確且つスピーディに処理していく必要があります。
そこで本論文では、バックプロパゲーション方式に基づいた対話型画像セグメンテーションアルゴリズムを提案します。ターゲットオブジェクトをセグメント化するために、Fully-CNN(fully convolutional neural network)を訓練します。
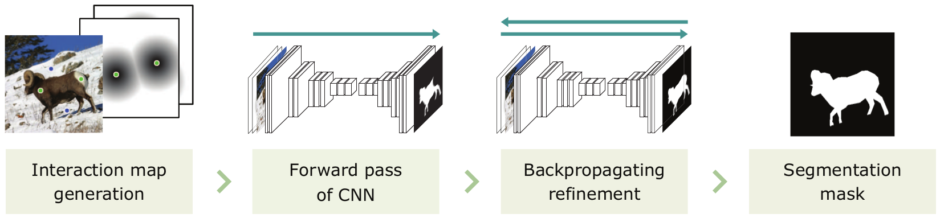
ユーザは、画像に対してターゲットオブジェクトを注釈し、セグメンテーション結果からさらに微調整を手動ですることで、最終的なマスクを出力します。調整は何度も可能でユーザが止めるまで再実行されます。これにより、本提案の訓練したモデルを使用することで、ユーザ注釈付きオブジェクトのセグメンテーションマスクを効率よく出力できます。