ミュンヘン工科大学などによる研究チームは、複数視点の画像から、その物体の3D再構成をより写実的に生成する学習ベースのアプローチ「IGNOR(Image-guided Neural Object Rendering)」を発表しました。
論文:IGNOR: Image-guided Neural Object Rendering
著者:Justus Thies, Michael Zollhöfer, Christian Theobalt, Marc Stamminger, Matthias Nießner
所属:Technical University of Munich, Stanford University, Max Planck Institute for Informatics, University of Erlangen-Nuremberg
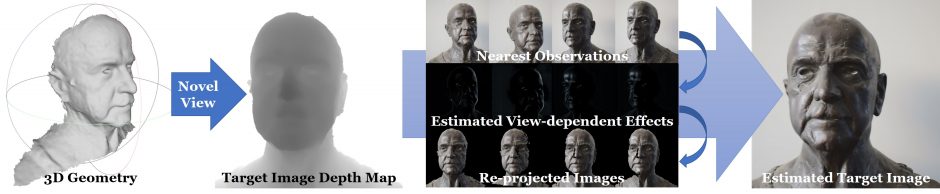
本論文は、多視点画像のセットを入力に、deep learningを用いてオブジェクトを再レンダリングする手法を提案します。本提案手法は、従来のテクスチャマッピングや手作業による画像ベースのレンダリングをする代わりに、deep learningで直接学習することで、ちらつき等のアーチファクトを軽減した高品質の画像を生成します。
前処理後は、2つのネットワークで構成されたパイプラインで実行されます。「EffectsNet」と呼ぶネットワークでは、視点依存の鏡面ハイライトや反射などのエフェクトを推定します。「CompositionNet」と呼ぶネットワークでは、データが欠落している領域を塗りつぶすなど含め、複数の再構成された画像を組み合わせ合成します。