早稲田大学、Pinscreen、南カリフォルニア大学、USC Institute for Creative Technologiesの研究チームは、CNN(Convolutional Neural Network)を用いて、1枚の画像から被写体の顔の形状および反射率をモデル化する手法を発表しました。
論文:High-Fidelity Facial Reflectance and Geometry Inference From an Unconstrained Image
著者:SHUGO YAMAGUCHI, SHUNSUKE SAITO, KOKI NAGANO,YAJIE ZHAO, WEIKAI CHEN, KYLE OLSZEWSKI,SHIGEO MORISHIMA,HAO LI
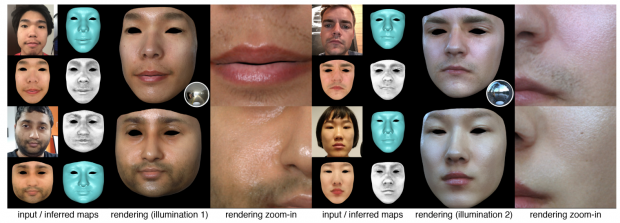
本稿は、1枚の画像から顔の反射率およびジオメトリデータを推定するCNNを用いたアプローチを提案します。得られたデータは、3Dモデルと共に使用し、異なる照明条件や任意の視点でレンダリングすることができます。
本提案手法では、入力画像からメッシュおよび対応する顔面テクスチャマップを抽出し、CNNを用いて可視領域からディフューズ反射、スペキュラー反射、ディスプレイスメントマップを推定します。
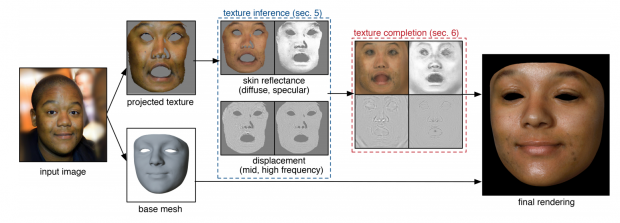
次に、可視化されていない部分を補完するため、ダウンサンプリングし可視領域に一致する内容を埋め、完成したテクスチャの解像度を512×512から2048×2048にアップサンプリングします。
これらのことで、1枚の画像からより現実的な3D顔面モデルを生成することを可能にします。ただし、入力画像が低画質/低解像度であれば推定はできず、メガネなども復元することはできない制限はあります。