東京工業大学による研究チームは、0.5秒後の相手の動きをリアルタイムに予測し格闘の訓練ができるdeep learningを用いたシステム「FuturePose」を発表しました。
著者:Erwin Wu ; Hideki Koike
所属:Tokyo Institute of Technology

本論文は、1台のRGBカメラによる画像から0.5秒後の相手の動きをリアルタイムに予測するdeep learningを用いた格闘訓練システムを提案します。本提案は、RGB画像の入力から相手の未来の姿勢を推定し提示することで格闘を訓練するシステムです。
具体的には、最初にResidual Networkを用いてRGB画像から相手の2D関節位置を推定します。続けて、推定した2D関節位置をLSTMネットワークの入力として時間的特徴を学習するために使用し、未来の2D関節位置を予測します。正確な動き予測を得るためにオプティカルフローを使用、中でも計算コストを下げるためにlattice オプティカルフローを使用します。
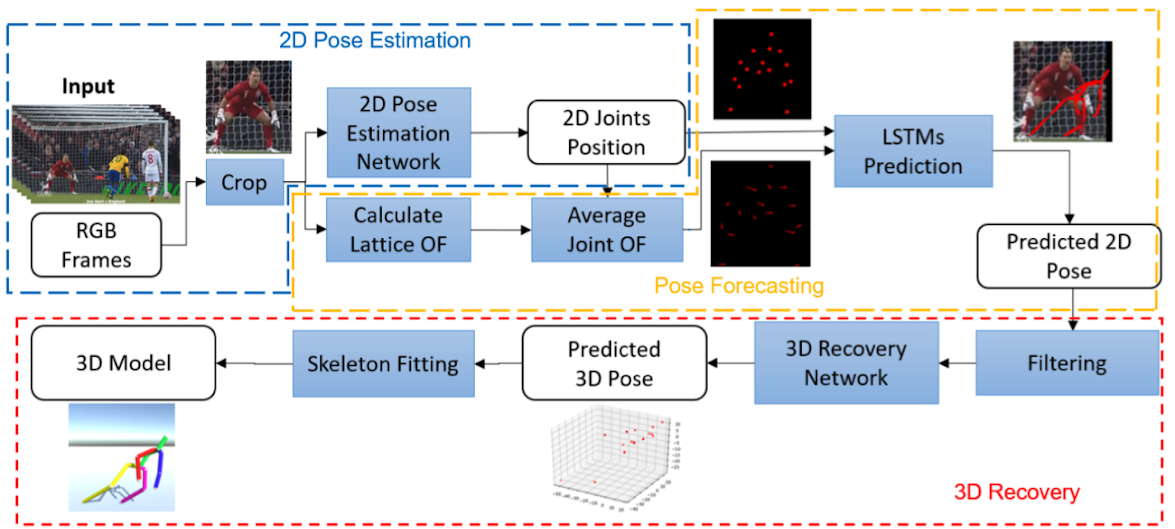
本提案の概要図。青枠:2D姿勢推定。黄枠:2D姿勢予測。赤枠:3D姿勢回復
最後に、予測した2D関節位置を可視化するために3Dスケルトンモデルを構築しユーザに提示します。ユーザは、提示された未来の動きをする3DスケルトンモデルをVR HMDで体験しながら、格闘技の訓練をすることができます。
実験では、HTC Viveを装着したユーザに、パンチやキックの攻撃を回避してもらいます。提示される映像は、予測なし映像と予測あり映像(ARベースとVRベースの2種類)。30 fpsのビデオで15フレーム先を予測(0.5秒後を予測)します。結果、予測なしのユーザの平均応答時間は0.62秒に対して、予測ありはそれぞれ0.42秒および0.41秒と予測ありの方が速く動作し、相手のパンチやキックを回避できることを示しました。
また、オンラインビデオに本手法を適応することで、視聴者に対して動画内の人の動作予測を提示することも実証しました。これにより、例えばPK時でのゴールキーパーの動きや、ダンスの動きなど、スポーツやエンターテインメントなど幅広い分野での活用が期待されます。