Facebookとスタンフォード大学とワシントン大学の研究者らは、ニューラルネットワークを用いて、バイオリンやピアノ演奏のオーディオ入力からアバタの動きを推定するシステムを発表しました。
論文:Audio to Body Dynamics
著者:Eli Shlizerman, Lucio Dery, Hayden Schoen, Ira Kemelmacher-Shlizerman
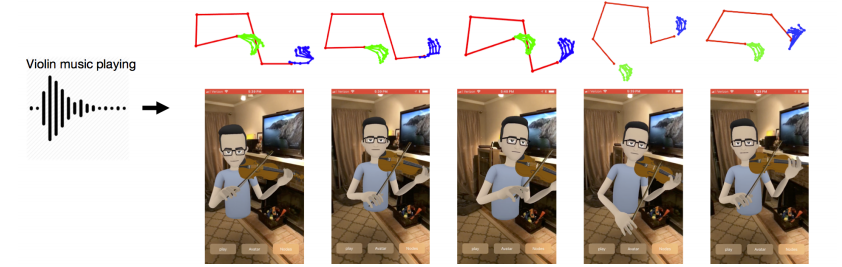
本稿は、バイオリンやピアノ演奏のオーディオを入力として取得し、アバタのアニメーションを作成、骨格予測のビデオを出力するニューラルネットワークを用いたアプローチを提案をします。音声信号から身体のジェスチャを予測します。
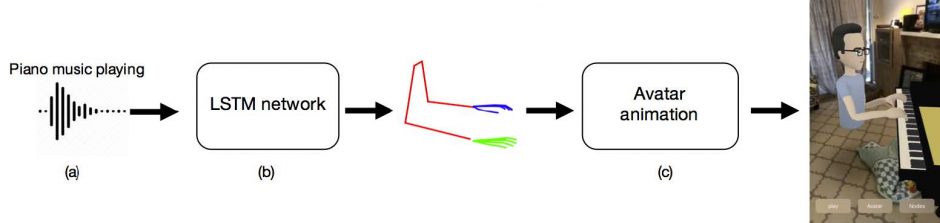
本提案手法では、OpenPoseとMaskRCNNを使用して推定します。ピアノとヴァイオリンのビデオ(Youtube)から、各ビデオの各フレームの上体と指を検出し、オーディオ機能と身体骨格のランドマークとの相関を学習するLSTM(Long-Short-Term-Memory)ニューラルネットワークを構築、予測された動きのポイントを基にアニメーションを作成し、オーディオに従って動くアバタとして出力します。

1フレームあたりのポイントは、身体と指合わせて合計50ポイント。上半身は8ポイント、各ポイントは21ポイントです。
これらのことで、オーディオ入力に応じて自然に動くアバタのアニメーションを再構築することを可能にします。制限としては、隠れた箇所、視覚的なポイントしか予測できない課題はあります。
また、今後は、その他センサやMIDIファイルを使用して、トレーニングデータを補完するチャレンジも検討したいとのことです。