Google Brainの研究チームは、単眼カメラから撮影したシーンだけから深度とエゴモーションを推定する教師なし学習を用いた手法を発表しました。
論文:Depth Prediction Without the Sensors: Leveraging Structure for Unsupervised Learning from Monocular Videos
著者:Vincent Casser, Soeren Pirk, Reza Mahjourian, Anelia Angelova
所属:Google Brain, Institute for Applied Computational Science, Harvard University, University of Texas at Austin
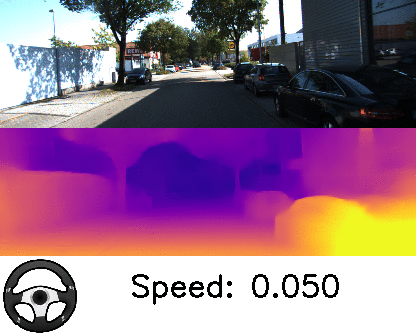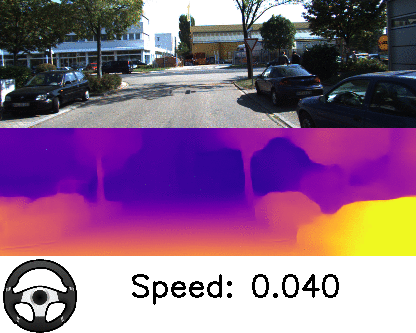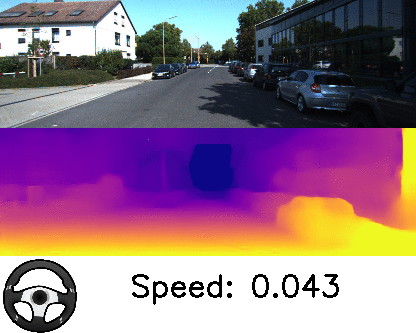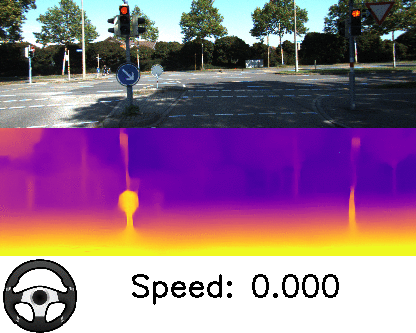
本論文は、単眼カメラで撮影したRGB画像を入力に、深度とエゴモーションを推定する教師なし学習を用いた手法を提案します。入力画像からシーンの深さを予測することは、屋内外のロボットナビゲーションにとって重要であり、しかし、深度を取得するためLIDARのような高価なセンサは導入ハードルが高いのが現状です。
そこで、本提案手法は、ニューラルネットワークを用いて直接深度を学習するのではなく、個々のオブジェクトに分解するアプローチにより安価な単眼カメラのみで対処できることを実証しました。個々のオブジェクトとモーションを独立して3Dモデリングすることで、深度とエゴモーションを推定します。また、オンザフライで学習を適応します。
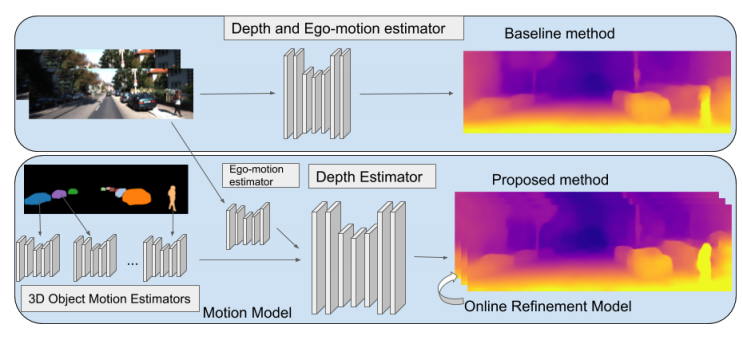
これにより、シーン内の動的オブジェクト(例:移動する車、人、自転車など)がどこに向かっているかを検出することができ、また、動いている物体だけでなく、静的オブジェクトでも、潜在的に移動する可能性があるかを学習し役立てます。
本提案手法の出力結果は、ステレオで訓練されたモデルにも匹敵すると実証しました。TensorFlowでコードも公開されています。