独マックス・プランク情報科学研究所(Max Planck Institute for Informatics)、ミュンヘン工科大学、Technicolor、バース大学、スタンフォード大学の研究者らは、ビデオ内の顔の表情、頭の動き、目の動きや瞬きを制御する機械学習を用いた手法を発表しました。
論文:Deep Video Portraits
著者:HYEONGWOO KIM, PABLO GARRIDO,AYUSH TEWARI, WEIPENG XU,JUSTUS THIES, MATTHIAS NIESSNER,PATRICK PÉREZ,CHRISTIAN RICHARDT,MICHAEL ZOLLHÖFER,CHRISTIAN THEOBALT

本稿は、機械学習を用いて、ソースビデオの人物(顔)からターゲットビデオの人物(顔)へ転送し、3Dアニメーションを再構築するアプローチを提案します。ソースビデオの人物がターゲットビデオの人物のアイデンティティと外観を維持しながら、頭部姿勢、顔の表情、目の動きや瞬きを制御することを可能にします。
本提案手法は、頭の動きや目の動きなどを両方のビデオからパラメータベースで取得し合成した顔モデルをネットワークの入力に使用し、ターゲットビデオの人物に対するビデオフレームを推定します。
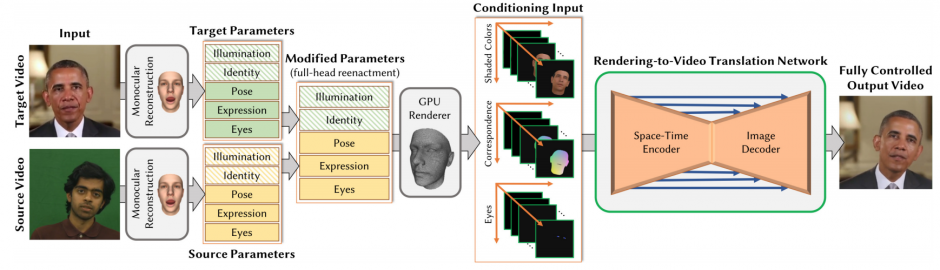
フォトリアリスティックなビデオに変換するため、敵対生成学習のcGAN(conditional generative adversarial network)を用いて精度を向上させます。
これらのことで、ソースビデオの人物がターゲットビデオの人物の顔の動きを制御したアニメーションを可能にし、また、パラメータの制御下であるため、頭の動きだけ制御や、ユーザコントロールによるインタラクティブ制御も可能にします。
ただし、胴体や髪の毛の動き、背景を制御することはできない制限はあります。