名古屋大学 情報基盤センターの戸田智基教授(JSTさきがけ研究者)の研究チームは、発声者の協⼒的動作を活⽤した⾳声⽣成機能の拡張技術を発表しました。
名古屋大学 大学院情報学研究科 戸田研究室
JSTさきがけJPMJPR1657
本研究チームは、⾝体的な制約、環境的な制約、能⼒的な制約などにより、⼗分な情報を持つ⾳声を⽣成することができない人向けに、瞬時に音声を変換し、所望の情報を持つ⾳声の⽣成を可能とする「⾳声⽣成機能拡張技術」に取り組んでいます。
今回、2つの視点からの音声拡張技術を提案します。
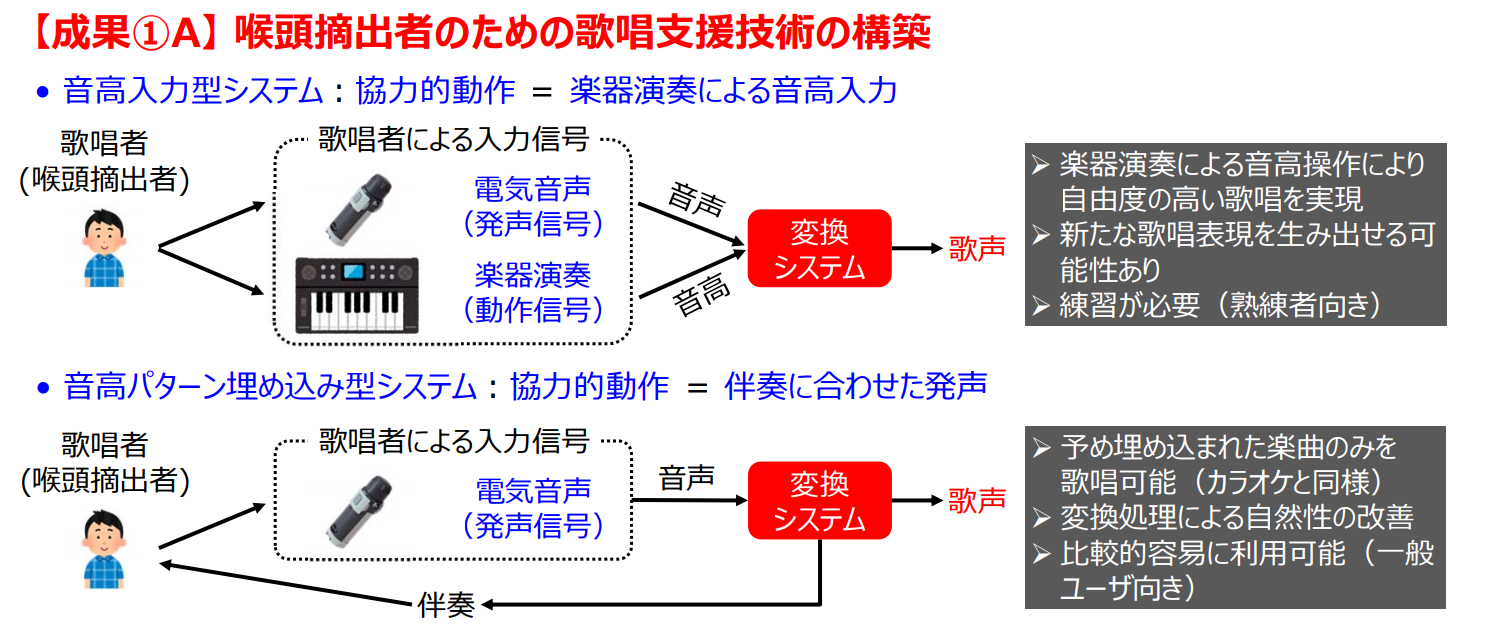
- 喉頭(のどぼとけ)摘出による発声・歌唱障碍に対する⽀援
- 健常者による歌唱表現の拡張
1つ目は、喉頭を摘出し発声が困難な人向けに、歌唱と発声を支援するシステムです。歌唱支援は、2種類の方法で提案します。入力に発声補助器具と楽器演奏を同時に使用する方法と、カラオケのように楽曲がある中で発声補助器具を用いて入力する方法です。どちらもより自然に歌唱することを可能にします。(出力結果は、記事最後に貼り付けてある動画をご覧ください)
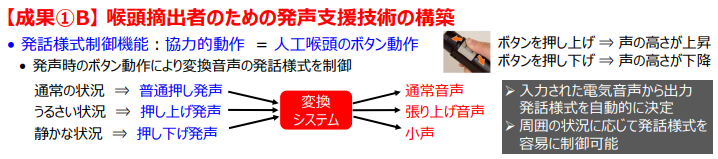
発声支援では、発声補助器を用いて、周囲の状況などに応じて発話様式をボタン動作により容易に制御可能な拡張システムの構築に取り組んでいます。これにより、うるさい環境や静かな環境など状況に応じて、張り上げ声や小声で発声できるようになると期待されます。
2つ目は、健常者がキャラクタの声を再現できる歌唱表現の拡張システムです。例えば、男性でも裏声による歌声を入力とすることで、特定のキャラクタの声をリアルタイムに再現することが出来ます。これにより、自分の自由な歌い回しのまま、所望の声⾊で歌唱することを可能にします。
本研究は、JSTさきがけJPMJPR1657の助成を受け実施したものとなります。