Disney Researchによる研究チームは、対話エージェントにおける会話中の動作を簡易的に導入するラベリング・インタフェースを発表しました。
論文:Animating an Autonomous 3D Talking Avatar
著者:Dominik Borer, Dominic Lutz, Martin Guay
所属:Disney Research

本論文は、対話エージェントにおける会話上の動作アクションを簡易的に導入する動作分類法を提案します。対話エージェントを実装する上での主な課題の1つは、動作がいつどのようにしてリアルタイムで再生され、一緒に構成されるかを視覚的なアーチファクトなしでラベリングすることです。そこで提案手法では、152のアニメーションにおける全てのモーションクリップをラベル付けするための高速インタフェースを検証します。
対話エージェントと会話する場合、うなずきなどの頭の動きをしながら、手の動きを変えたり、体重を体の片側に移動させるなど体の姿勢を変えたり、人間の動きと似せたより自然な動作が求められます。従来の方法でUnityやUnreal Engine等で作業すると、例えば9つのStanceとそれに付随するGestureがそれぞれ5つ、fidgetも5つ、そしてStance間の複雑なTransition、これらをメタグラフにすると以下のようになります。
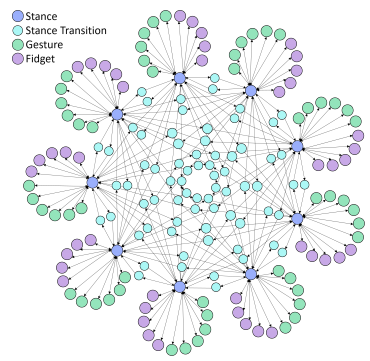
アニメーションの数が増えるにつれて指数関数的な作業が必要になり、これだけ複雑だと人為的誤りが起き大量のモーションに対応することは困難になります。本提案では、これらを単純化し、アニメーションクリップ間を自動化するドラッグアンドドロップ方式で構築できるインタフェースを検証します。以下が本提案のメタグラフとインタフェース画面です。
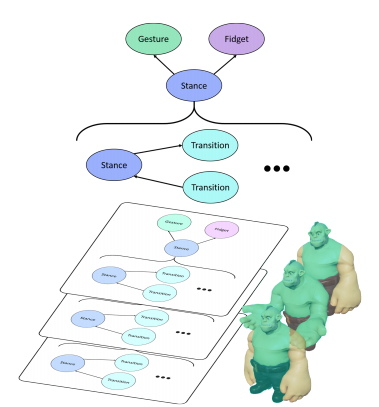
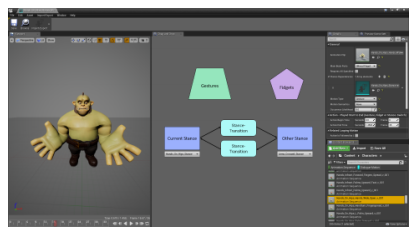
アニメーションの合成は、運動の解析から3つの層(体、腕、頭)に分解され、加算的に組み合わされ最終ポーズを形成します。この単純化により、人為的誤りを防ぎつつ短時間(Unreal Engineの従来のインタフェースを使用する場合に比べて7倍高速に)で構築することができ、多数の動きやバリエーションを持つことで、より豊かで自然なパフォーマンスを付与することを可能にします。