Google DeepMindは、マシンが周囲を認識するために、2D画像からシーンの3Dモデルを生成する視覚認識フレームワーク「Generative Query Network(GQN)」システムを発表しました。

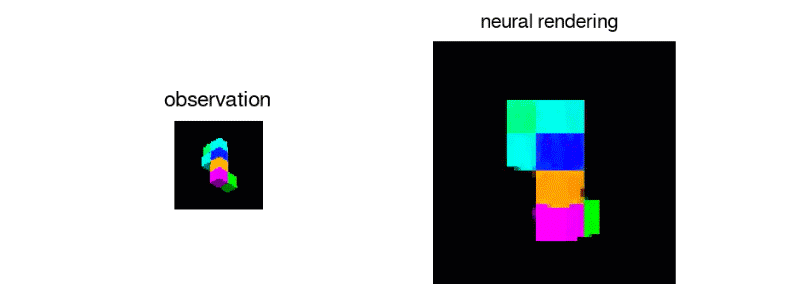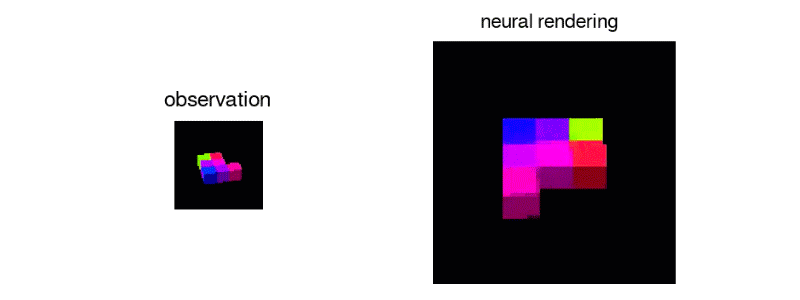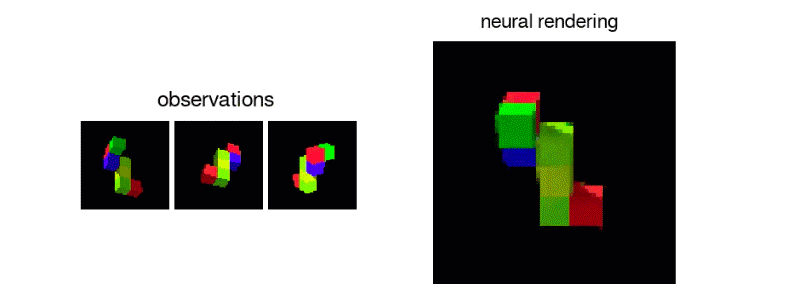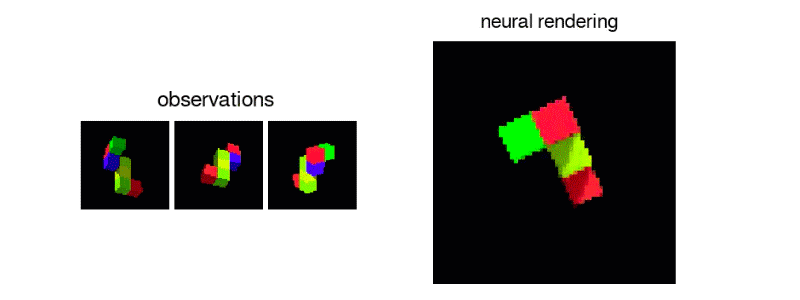
GQNは、事実上何も知らないエージェントが、シーンの複数の静的2D画像を見て、それの合理的に正確な3Dモデルを再構築するシステムです。
シーンの内容を人間がラベル付けすることなく、あらゆる角度からシーンを推定しレンダリングします。マシンが、その部屋なりを動きながら収集した2D画像を基に、関係性や規則性などを学び、見えない部分も含めオブジェクトの位置や色などを推定し再現します。
以下のような単一の視点から正確な3Dオブジェクトを生成することもできます。