ブラウンシュヴァイク工科大学「Computer Graphics Lab」、マックス・プランク情報科学研究所の研究者らは、1台の単眼RGBカメラを使用して人の3Dモデルを作成する機械学習を用いた手法を発表しました。
論文:Video Based Reconstruction of 3D People Models
著者:Thiemo Alldieck, Marcus Magnor, Weipeng Xu, Christian Theobalt, Gerard Pons-Moll

本稿は、単一のカメラを用いたビデオから3D人体モデルを再構成する機械学習を用いた手法を提案します。
本提案手法は、複雑なカメラ機器や、Microsoft Kinectなどの3D深度センサは必要とせず、1台のカメラからの単一の視点で完了します。スマートフォンの既存カメラや、PCのウェブカメラだけで可能と。
ユーザは、その前でぐるっと回るだけでスキャンされます。提案手法は、フレームを前景と背景に分類するCNNベースのビデオセグメンテーション方法を用いて人物を背景から分離し、SMPLモデルを使用してポーズを計算、シルエットを取り除き形状を最適化、テクスチャを計算しパーソナライズされたブレンドシェイプモデルを生成します。
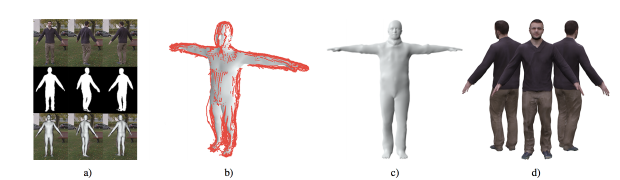
4.5mm以内の精度で再構成します。再構成は、髪、身体、衣類、表面テクスチャ、姿勢および形状の変化を可能にする基礎モデルなどが含まれます。一方で、スカートや長い髪はまだ難しいとしています。
コードとデータセットはこちらで公開されています。(執筆現在はComing Soon)
関連
南カリフォルニア大学、単一の顔画像からリアルタイム用アバターの顔や髪形を再構成する提案の論文概要を発表。髪形には深層畳み込みニューラルネットワークを使用 | Seamless