トロント大学とVector Instituteの研究者らは、会話文に対して、自然言語による返答とそれに合う顔の表情を生成する発表しました。
論文:A Face-to-Face Neural Conversation Model
著者:Hang Chu, Daiqing Li, Sanja Fidler
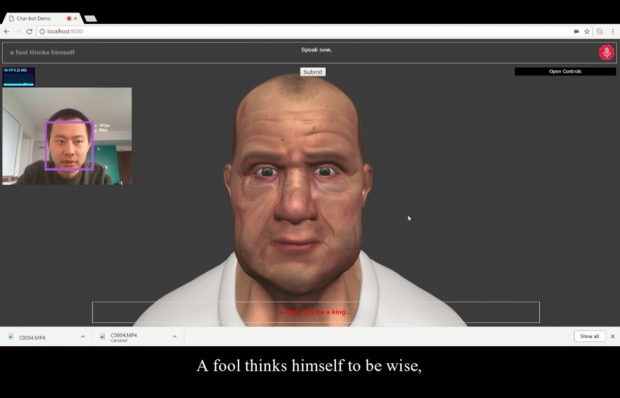
(Webカメラを通してボットとリアルタイムに会話している様子)
本稿は、テキストもしくは動画による会話文の入力に対して、自然言語による返答と、同時にそれに合う適切な顔のジェスチャを生成するニューラルネットワークモデルを提案します。
訓練には、250本の映画データセット「MovieChat」を用いて、1人の顔が映っているシーンからデータセットを構築します。顔のジェスチャを検出するためにOpenFaceを使用。モデルは、強化学習とGANで訓練されたフレームワークで、6つのRNN(Recurrent Neural Network)モジュールで構成されています。
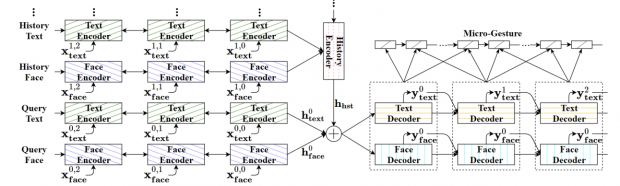
これらのことで、ボットとの会話のために、テキスト情報と顔情報の両方を用いた適切な応答の生成を可能にしました。実験では、入力にテキストのみや顔の表情が加わるなど5アプローチで行われますが、動画の場合だと、同じテキストでも相手の表情の違いで返答が変化することも実証しました。
また、WebカメラとWebGL等を用いて、リアルタイムに返答をするアプリケーションも作成しました。こちらでは、リアルタイムのライブデモを試すことができます。