南カリフォルニア大学、Pinscreen、Snapchat、USCクリエイティブ・テクノロジー研究所の研究者らは、1枚の画像から3Dヘアを再構築するdeep learningを用いた手法を発表しました。
論文:3D Hair Synthesis Using Volumetric Variational Autoencoders
著者:著者:Shunsuke Saito, Liwen Hu, Chongyang Ma, Hikaru Ibayashi, Linjie Luo, Hao Li

本論文は、単一視点画像から3次元ヘアモデルを直接生成するdeep learningフレームワークを用いた手法を提案します。本提案手法のVariational Auto-Encoder(VAE)は、エンコーダと2つのデコーダで構成されます。
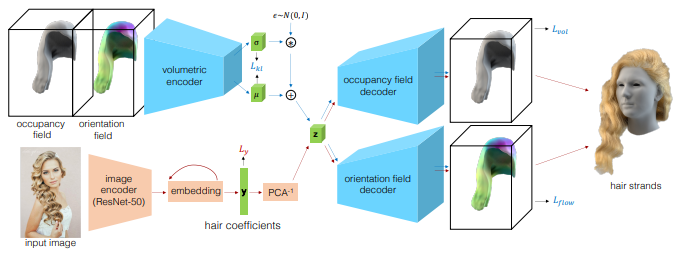
2000種類以上のヘアスタイルのデータセットを使用して、変分オートエンコーダを訓練することで3Dヘアを低次元空間に圧縮し、さらに入力画像から髪型を直接予測するembedding networkを訓練します。最後に、予測された髪の向きと髪型の概形に基づき、ストランドを頭部モデルの頭皮から成長させることによって毛髪の束を合成します。
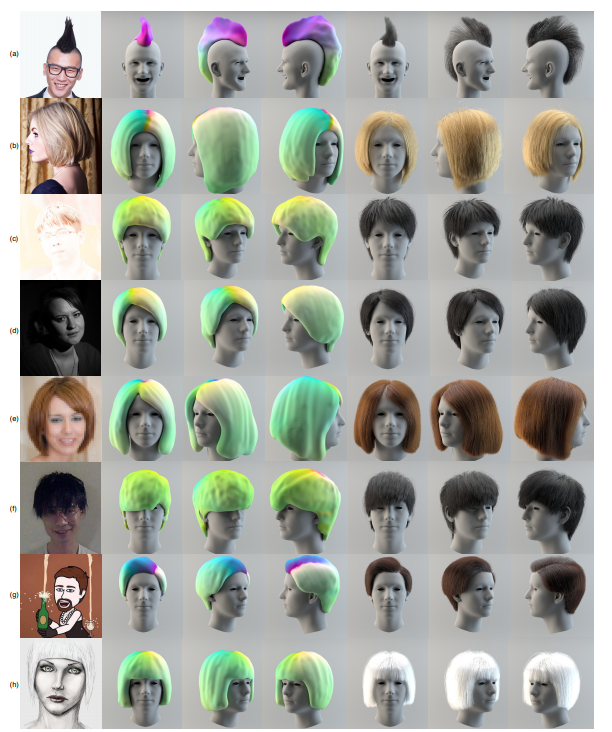
これにより、1枚の画像から顔検出や髪領域の検出に依存しない3Dヘアの合成を可能にします。それにより、後頭部、暗い被写体、スタイライズされた画像など、非常に難しいケースも処理できるようになりました。