テキサス大学オースティン校とFacebook AI Researchの研究チームは、動画を活用して、モノラルオーディオをバイノーラルオーディオに変換するdeep learningを用いた手法を発表しました。
著者:Ruohan Gao, Kristen Grauman
所属:The University of Texas at Austin, Facebook AI Research
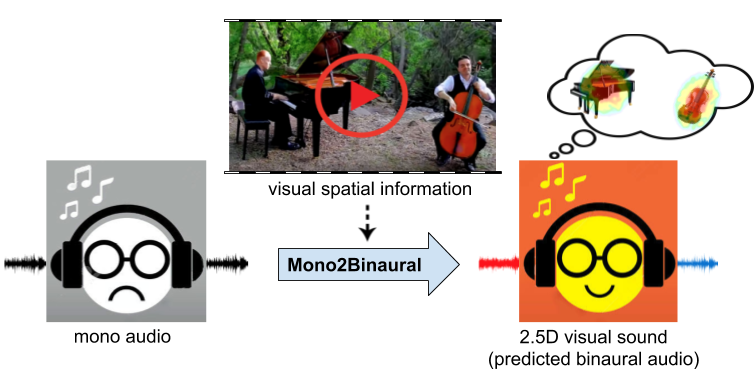
本論文は、ビジュアルフレームに見られるオブジェクトとシーン構成を利用して、シングルチャンネルオーディオをバイノーラルオーディオに変換する技術を提案します。例えば、上図の動画では、左にピアノ、右にチェロを弾く人がいますが、通常のモノラルではどこから聞こえているか分かりませんが、本提案手法を用いると、音源の位置を感知しながら視聴することができます。
本提案手法は、Mono2Binauralと呼ぶフレームワークを使用します。モノラルオーディオとそれに付随するビジュアルフレームを入力とし、ResNet-18で視覚的特徴を抽出、U-NETでオーディオ特徴を抽出、オーディオビジュアル分析を実行し、ビデオの空間構成と一致するバイノーラルオーディオを推定します。
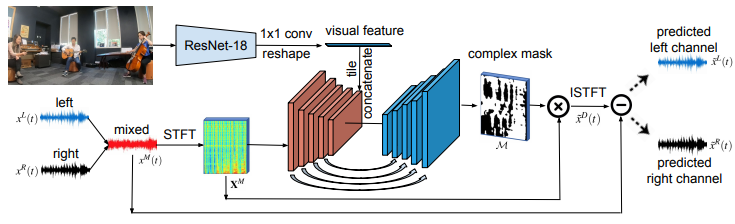
これにより推定されたバイノーラルオーディオ(2.5Dビジュアルサウンド)は、音源の位置を感じさせることができ、より没入感のあるオーディオ体験を提供できます。今後の課題としては、オブジェクトの位置特定と動きを取り入れ、シーンサウンドを明示的にモデル化する方法を模索する予定としています。