Google Researchは、Deep learningを用いて、複数の音から1人の音声だけを抜き出す視聴覚音声分離モデル「Looking to Listen at the Cocktail Party」を発表しました。
論文:Looking to Listen at the Cocktail Party: A Speaker-Independent Audio-Visual Model for Speech Separation
著者:Ariel Ephrat, Inbar Mosseri, Oran Lang, Tali Dekel, Kevin Wilson, Avinatan Hassidim, William T. Freeman, Michael Rubinstein
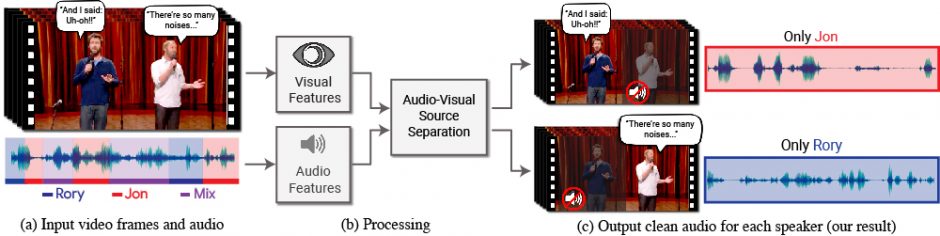
上の動画を見てもらうと分かるように、2人が同時に話す中で、どちらかをミュートにしてどちらかだけを聞こえるようにパラメータで自由にコントロールしている様子が実証されています。
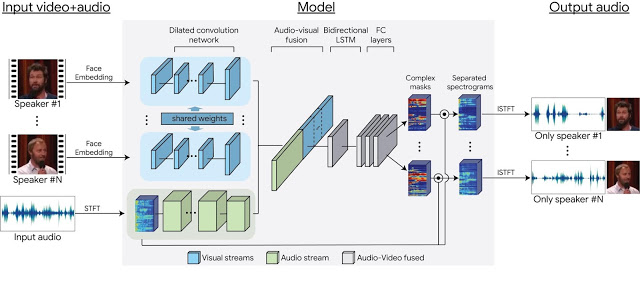
本稿は、他の人の音声や背景の雑音などの混合音から単一の音声信号を分離するDeep learningを用いたモデルを提案します。本モデルを使用すると、特定の人の発話が強調され、他のすべての音声は抑制されたビデオを生成することができます。
入力ビデオは、普通のオーディオトラックを持つ映像で行えます。ユーザは、強調したい発話者の顔を選択するだけで実行できます。
本提案手法は、音声を分離するために入力ビデオの聴覚信号と視覚信号の両方からアプローチしています。人が話す声と口の動きは相関関係があるため、両者を捉えることで精度は向上します。
関連
Googleら、テキストから機械学習を使って人間のようなスピーチを生成する人工音声生成モデル「Tacotron 2」を論文にて発表。サンプル音声あり | Seamless