Google DeepMindは、数字、文字、肖像画などを描くときのブラシストロークを機械学習を用いて推論する「SPIRAL(Synthesizing Programs for Images using Reinforced Adversarial Learning)」を発表しました。
論文:Synthesizing Programs for Images using Reinforced Adversarial Learning
著者:Yaroslav Ganin,Tejas Kulkarni,Igor Babuschkin,S. M. Ali Eslami,Oriol Vinyals
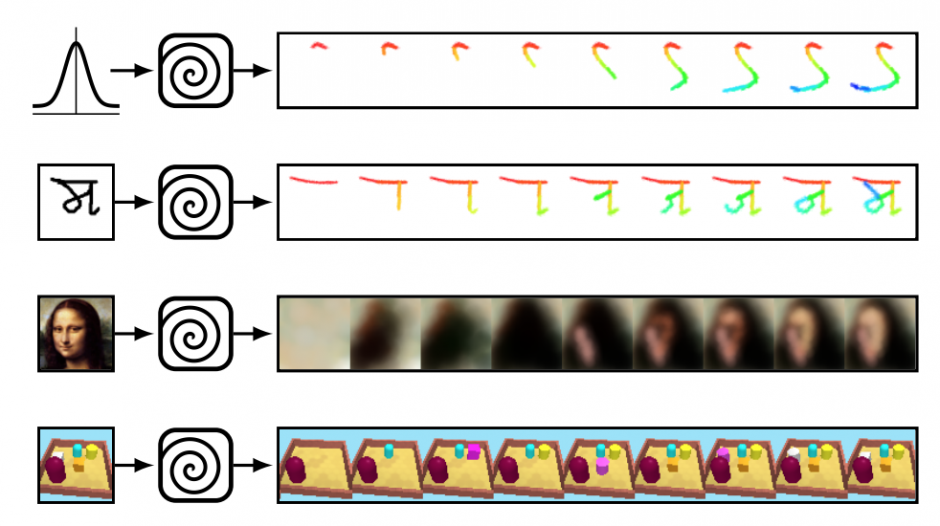
本稿は、機械学習を用いて筆のストロークを考慮しながら生成する画像描画プログラムを提案します。画像から画像をピクセルベースで生成するだけではなく、ブラシストロークを考慮した上で描画するアプローチを研究します。
提案手法は、ブラシのサイズ、圧力、色の変更を強化学習で訓練し描くエージェントを設計し、加えて、文字や画像がエージェントによって生成されたか、それともデータセットからサンプリングされたかどうかを判断する識別器(ニューラルネットワーク)を用いて精度を上げます。
描くエージェントは識別器を欺くために訓練され、識別器は見抜くために訓練され、人間がラベル付けしたデータセットを用いることなく自身で切磋琢磨して精度を高めていきます。ただし、敵対生成学習のGAN(Generative Adversarial Networks)とは異なると述べています。
数字や図形だけでなく、肖像画も再構築するテストをしており、以下のようにぼやけていますが、背景色、顔の位置、人の髪の色などある程度一致した画像を生成します。

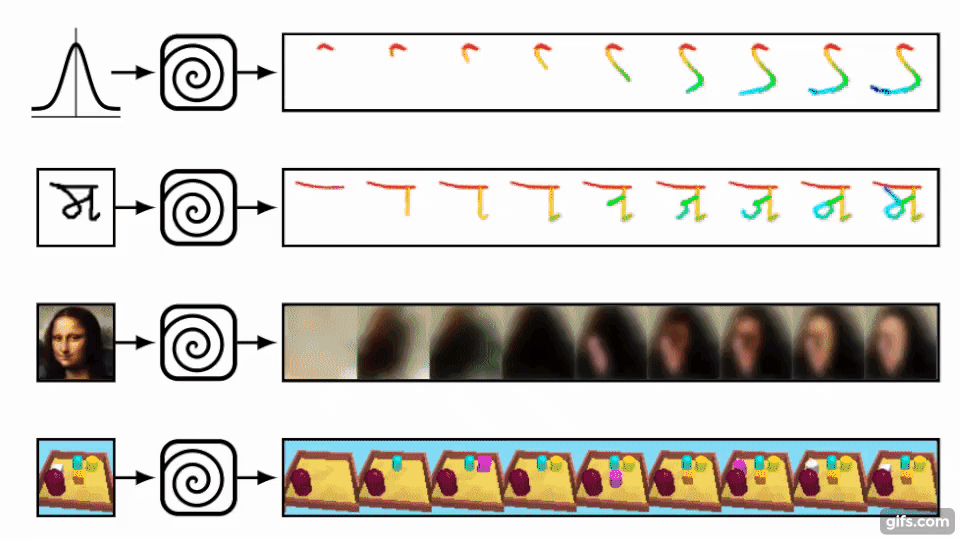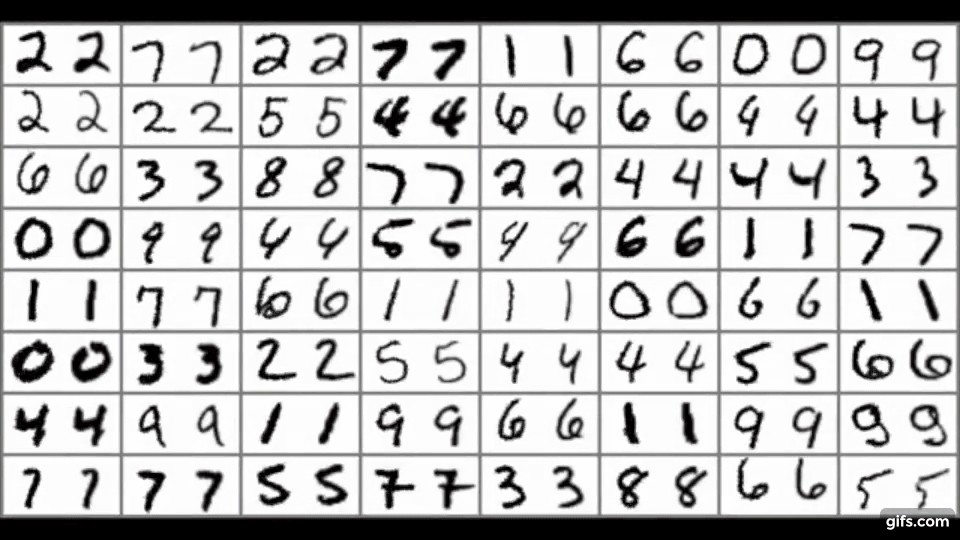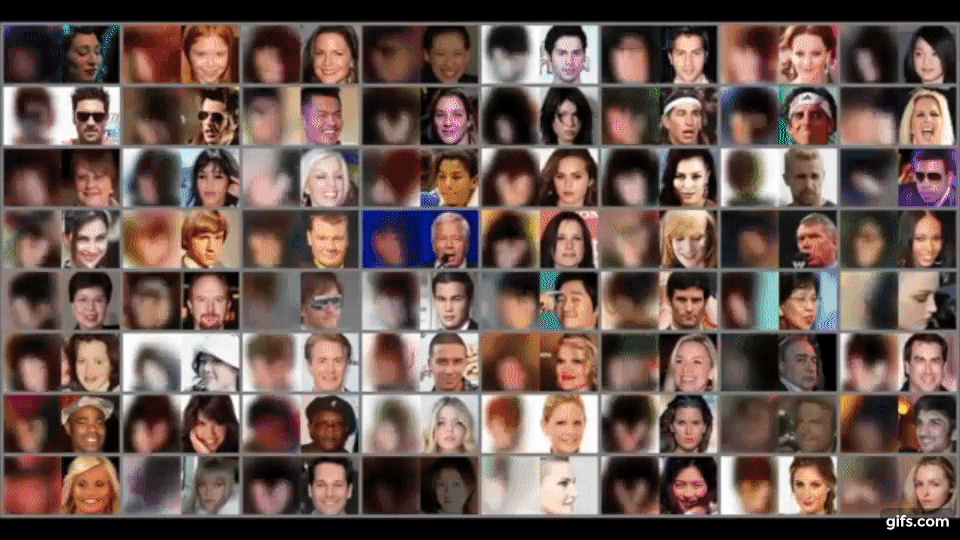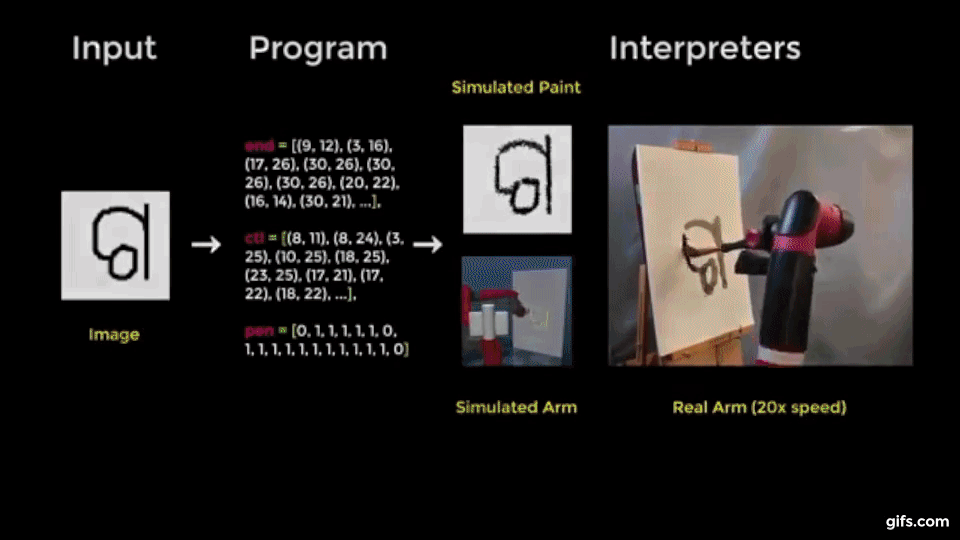
別の実験では、本提案手法をロボットアームに統合して、筆でキャンパスに描くテストもしています。
お詫びと訂正
最初の投稿では、人間のように書き順や構造を理解した上で描画するという書き方をしていました。実際には、筆のストロークを学習するという提案であり、構造を理解するという表現は誇張であり不適切でした。ご迷惑をお掛けしたこと、お詫び申し上げます。本当に申し訳ございませんでした。