南カリフォルニア大学などによる研究チームは、1枚の画像から服を着た人の3Dモデルを再構築できるdeep learningを用いた手法「Pixel-aligned Implicit Function(PIFu)」を発表しました。
論文:PIFu: Pixel-Aligned Implicit Function for High-Resolution Clothed Human Digitization
Shunsuke Saito¹,²∗ Zeng Huang¹,²∗ Ryota Natsume³∗ Shigeo Morishima³ Angjoo Kanazawa⁴ Hao Li¹,²,⁵
¹University of Southern California ²USC Institute for Creative Technologies
³Waseda University ⁴University of California, Berkeley ⁵Pinscreen
∗- indicates equal contribution
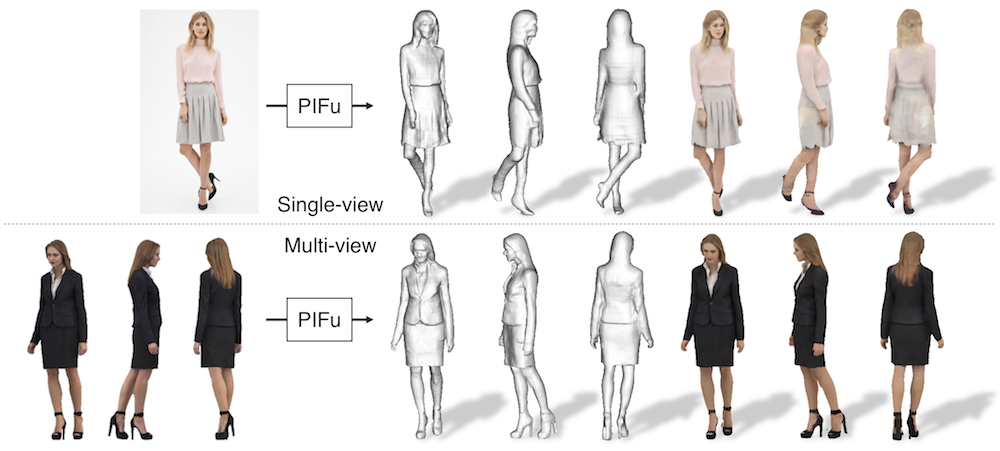
本研究は、単一または複数の入力画像から服を着た人間の3D形状とテクスチャを生成するdeep learningを用いて推定するエンドツーエンドの手法を提案します。本提案手法を用いることで、1枚の画像または複数の画像からヘアスタイルやしわのあるスカート、ハイヒールのような複雑な形状を3D化します。また1枚の入力画像からの場合、被写体の背面など、見えない領域もそれらしい形状及びテクスチャを推定し再構築します。