カリフォルニア大学バークレー校の研究者らは、ビデオ内の人の動きをキャラクタが習得するための、deep learningを用いたフレームワークを発表しました。
論文:SFV: Reinforcement Learning of Physical Skills from Videos
著者:Xue Bin Peng, Angjoo Kanazawa, Jitendra Malik, Pieter Abbeel, Sergey Levine

本論文は、物理的にシミュレートされたキャラクタがビデオからスキルを習得できる強化学習アルゴリズムを提案します。
本提案手法は、単眼で撮影された通常の動画からアクロバットなスキル(動画内の人の動き)の姿勢推定をするところから始まり、物理的なシミュレーションでスキルを再現することで3D姿勢推定を補完し、これを学習プロセスにて使用します。
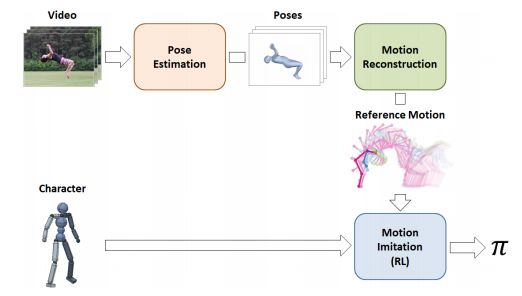
パイプラインは、姿勢推定、モーション再構成、模擬という3つのステージから構成されます。 それは、特定のスキルを実行する人のビデオクリップと、シミュレートされたキャラクタモデルを入力として、キャラクタがそのスキルをシミュレーションで再現することを可能にする制御ポリシを学習します。
得られたポリシは、異なるキャラクタや環境にリターゲットしたり、インンタラクティブな設定で使用することが可能です。