Google Brainの研究者らは、数ヶ月前、機械学習モデルの設計を機械学習で自動化するアプローチ「AutoML(Auto Machine Learning)」を発表しましたが、今回は、これまで小規模にテストしてきたAutoMLを大規模な画像分類と物体検出に適応した論文を発表しました。
Learning Transferable Architectures for Scalable Image Recognition(PDF)

「AutoML」とは、人工知能に機械学習のコードやアルゴリズムを生成させる新しい開発アプローチで、ニューラルネットワークがニューラルネットワークを設計する技術です。
これまでは、小規模のデータセットに制約していましたが、今回は、検出データセット「COCO」や画像分類データセット「ImageNet」に適応しました。この2つは、コンピュータビジョンで尊敬される大規模な学術データセットです。
この2つに適応させるために、AutoMLは新しいアーキテクチャ「NASNet」を設計しました。
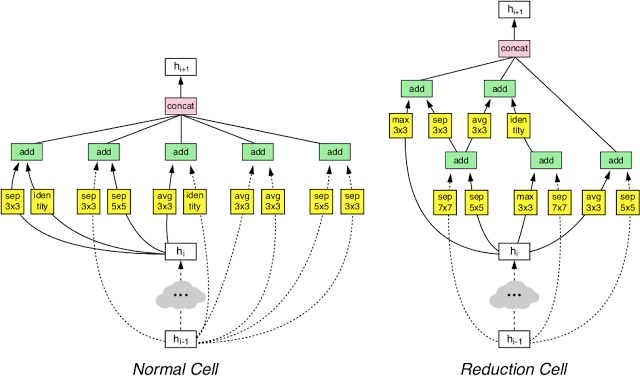
(「NASNet」と呼ぶ新たなアーキテクチャ。Normal Layer(左)とReduction Layer(右)の2種類のレイヤーで構成されており、これらの2つの層はAutoMLによって設計されました。)
NASNetは、ImageNetに適応した場合、同社が構築した以前のモデルを上回る、検証セット上で82.7%の予測精度を達成しました。過去の公表されたすべての結果よりも1.2%優れており、モバイルプラットフォーム用の小規模サイズでは、最先端モデルよりも3.1%優れていると報告しました。
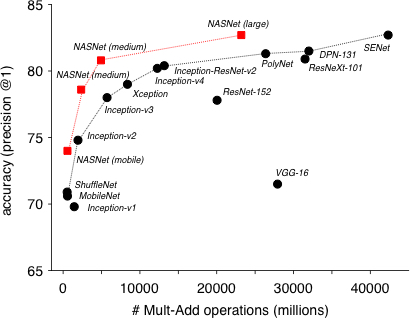
(NASNetの精度と、ImageNet画像分類で人間が設計してきたさまざまな最先端モデル。どれもNASNetが上。)
そして、実験では、ImageNet分類から学んだ機能をFaster-RCNNフレームワークと組み合わせオブジェクト検出に適応しました。結果、以前発表された最先端の技術よりも4%優れており、43.1%のmAPを達成しました。

(NASNetでFaster-RCNNを使用したオブジェクト検出の例)
Googleは、ImageNetとCOCOのNASNetで学んだ画像の特徴が、多くのコンピュータビジョンアプリケーションで再利用される可能性があると考えて、SlimとObject DetectionのTensorFlowリポジトリでリリースしています。
関連
Google、機械学習の可視化を強化する「TensorBoard API」を発表。独自の機械学習ビジュアライゼーション構築へ | Seamless