Disney Research、イングランド:イースト・アングリア大学、カリフォルニア工科大学、カーネギーメロン大学の研究者たちは、音声データからそれに合わせたフェイシャル・アニメーションを自動的に生成する機械学習アプローチを論文にて公開しました。
A Deep Learning Approach for Generalized Speech Animation(PDF)
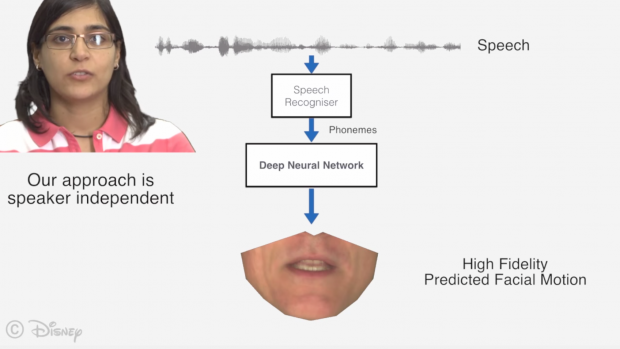
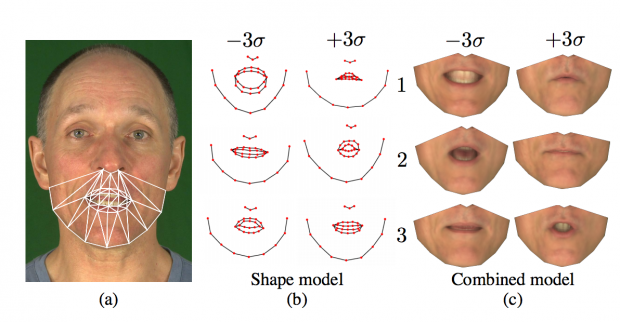
本アプローチは、Deep Learningで訓練されたシステムを使用して、任意の単一スピーカーからの音声を分析、対応する口形を自動的に生成、自動音声アニメーションの顔モデルに適用することができます。
音声データから口元のアニメーションに変換し、キャラクターの顔にリターゲットすることを可能にします。
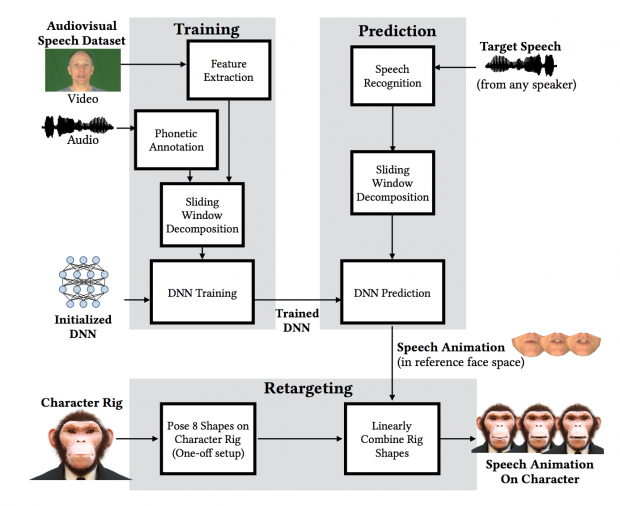
下のGIFは、右がオリジナルで、左が本パイプラインから生成したアニメーションです。

関連
NVIDIAの音声入力から3D顔面モデル・アニメーションを駆動させる機械学習ベースの技術がSIGGRAPH 2017にて採択 | Seamless