Googleは、先日Deep Learning向けトレーニングライブラリ「Tensor2Tensor(T2T)」を発表しました。今回は、その一部に含まれる「MultiModel」が、8つの異なるタスクを同時に学習できるということを発表しました。
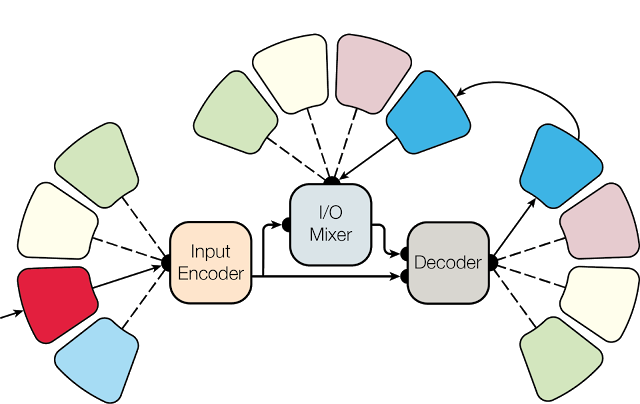
通常、ニューラルネットワークは一つのタスクに特化し完了する事が基本ですが、MultiModelでは複数のタスクを同時に訓練する事ができます。
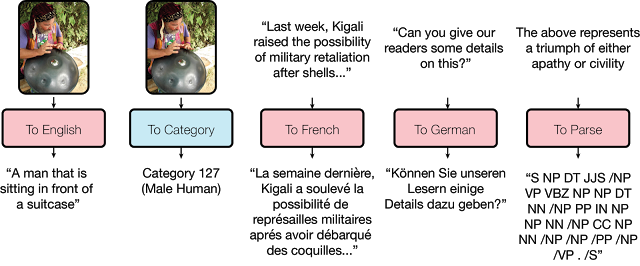
例えば、画像内のオブジェクトを検出し、キャプションを提供、スピーチを認識、4組の言語間で翻訳、文法と構文を解析する、そんな異なるタスクを同時に学習する事を可能にします。
それは、人間の脳が一度に複数のタスクを処理するイメージです。五感を使って情報を収集し、考え選択したタイミングで選択した言語や行動を出力する。また、これらタスクは独立しているのではなく、すべての情報が一緒になって全体を理解し必要なときに応答します。
MultiModelもドメインごとをネットワーク化し統合、他のタスクと連携してトレーニングを行います。
パフォーマンスは多くのタスクで良好な結果がもたらされた事が報告され、また以下の事が証明されました。別々のタスクは、お互いのパフォーマンスを妨げないという事、そしてデータ量が限られているタスクでは改善されパフォーマンスが向上した事。
つまり、お互いが足の引っ張り合いをせず良好な結果を出しながら、しかも、例えば画像認識タスクが言語タスクの性能を改善するといった他のタスクを改善する現象も引き出したと。
今回の記事ページはこちら。Tensor2TensorのGitHubページはこちら。