NVIDIAが開発する機械学習を用いたオーディオ駆動の3Dフェイシャル・アニメーション技術がSIGGRAPH 2017にて採択されました。論文はこちら(PDF)。

本提案は、俳優の音声入力から話すスタイルを3Dモデル化し、表情含め動的に低レイテンシおよびリアルタイムに動作させることを可能にします。
本提案で同社が用いる機械学習技術ディープニューラルネットワークは、音声の入力波形から顔モデルの3D頂点座標へのマッピングを学習し、と同時にオーディオだけでは説明できない表情の変化も推論し明確にします。
性別、アクセント、言語が異なる多様なスピーカーの音声で駆動しても合理的な結果をもたらしました。
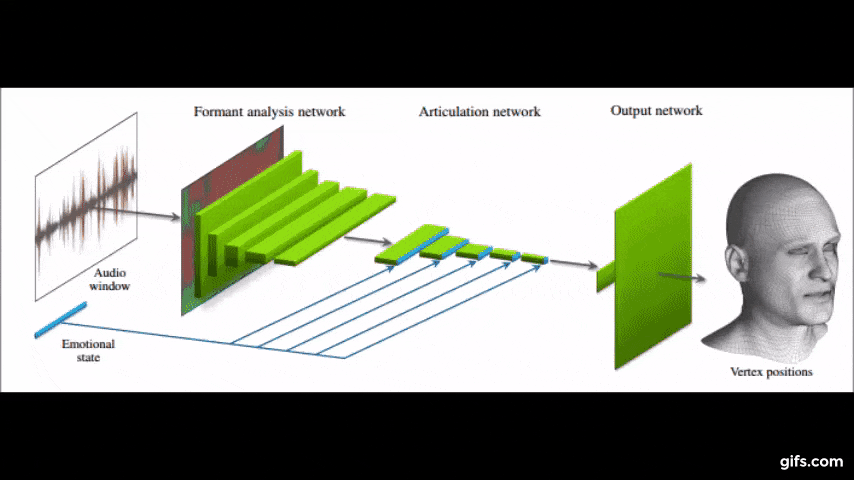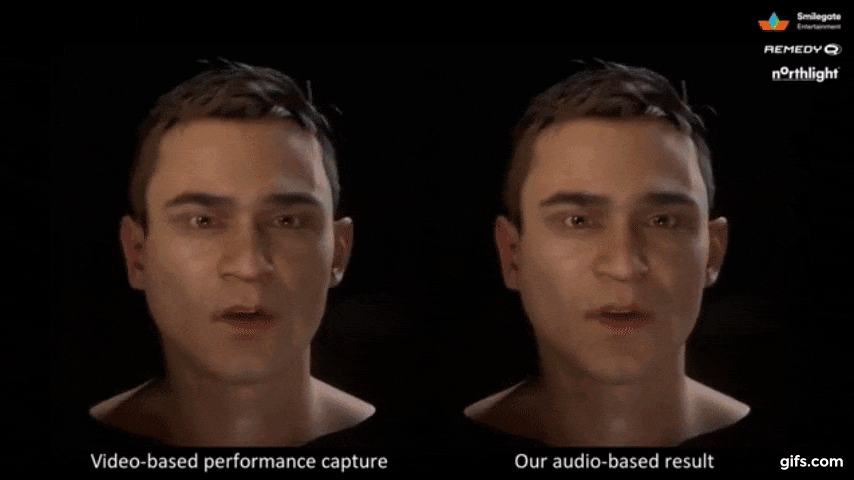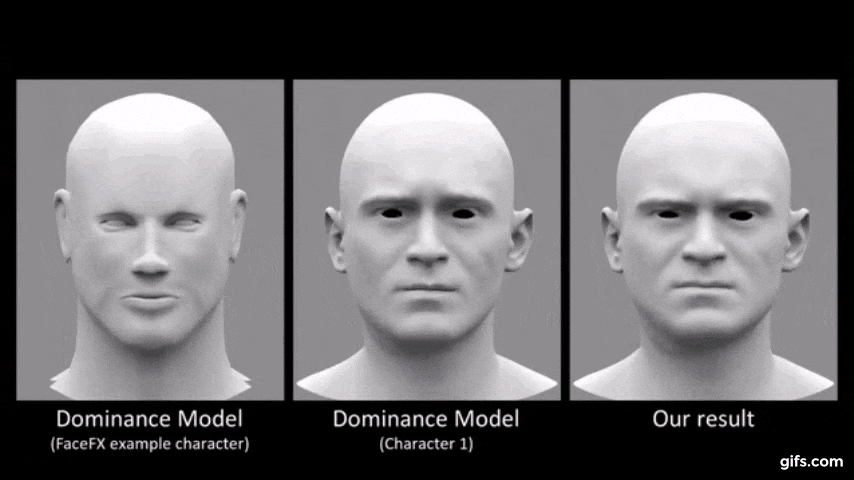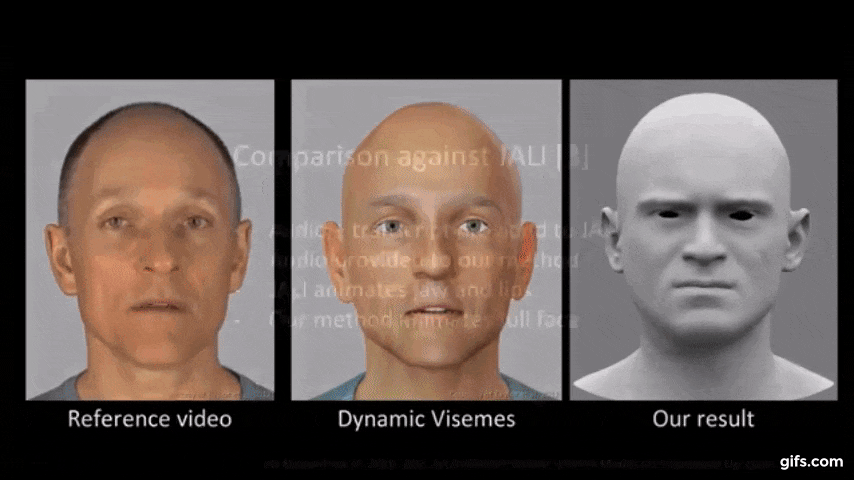
説明映像はこちら。
関連
アクター(俳優)とキャラクターの顔面比率が違っていても自動的に再配置する新たなフェイシャル・キャプチャ技術が論文にて公開 | Seamless