Baidu Researchとシドニー工科大学の研究チームが開発した「Collaborative Video Object Segmentation by Foreground-Background Integration( CFBI )」[Yang et al. 2020]は、動画内において、オブジェクトごとに追跡しクラス分けする半教師あり学習のビデオオブジェクトセグメンテーション(Video Object Segmentation 、VOS)だ。
ビデオオブジェクトセグメンテーション( VOS )とは
ビデオオブジェクトセグメンテーション(VOS)とは、動画内のオブジェクトに対して、そのオブジェクトが何なのかをピクセル単位で区別し認識するタスクを指す。ターゲットとなるオブジェクトと、背景や他のオブジェクトとの境界線を引くことで、クラス分けを行い抽出できる。ARや自動運転など、多くの応用が期待されるコンピュータビジョンの基本的なタスクとして知られている。
既存のVOS手法
VOSの研究では、半教師あり学習でビデオオブジェクトセグメンテーションを行う「Video Object Segmentation using Space-Time Memory Networks」[Wug Oh et al. 2019] がある。メモリネットワークを導入してシーケンス情報を読み取る学習を行い、精度の高いVOSを実証している。しかし、大規模な画像データセットを用いたフレームシーケンスのシミュレーションに依存しているため、非常に訓練手順が複雑になったりと改善の余地もある。
また、これまでのVOS手法は、前景オブジェクトのみに着目しセグメンテーションを実行しており、背景領域は基本的に注目されてこなかった。
本手法
本手法では、前景領域にしか着目していない従来の手法から学び、背景領域も考慮することで精度が上がるのではないかと仮定した。なぜなら、従来の方法では、背景にある類似/同種のオブジェクトが前景オブジェクトの予測を混乱させやすくエラーが起きやすいからだ。
このようなことから、背景を前景と同等に扱い、すべての背景を正確に除去すれば、より精密に前景オブジェクトを抽出できると考えた。今回の手法では、前景と背景を統合したCFBIと呼ぶVOSモデルを提案する。
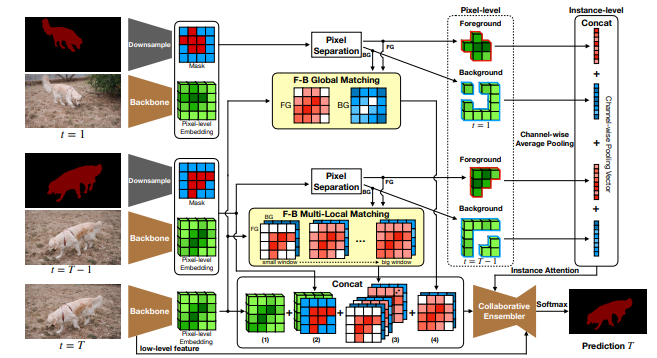
これまでの手法とは異なり、基準フレーム内の前景オブジェクトに対してEmbedding(埋め込み)を行うだけでなく、背景領域に対してもEmbeddingを行い、マッチングすることで、背景の混同を解消する。
さらに今回の手法は、特徴量のスケールをカバーするために、動画フレームごとにピクセルレベルとインスタンスレベルの2種類のEmbeddingを行っている。
ピクセルレベルだけでは、スケールの大きなオブジェクトをマッチングするには十分ではなく、またピクセルごとの多様性によるノイズも発生するからだ。
定性的な評価
このように学習したモデルの有効性を検証するために、DAVIS 2017とYouTube-VOSで定性的な実験を行った。

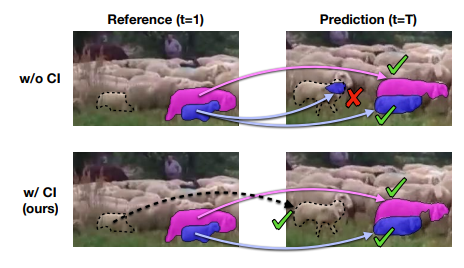
結果、上図が示すように、背景に類似した羊がいるのにターゲットの羊を正確に追跡し、人と犬が複雑にオクルージョンしても正確に追跡した。ただし、柔道の動画では正確にセグメントできないシーンがあり、腕の領域が失敗している。2人の人物が似ていて、位置が近すぎること、また、動きが速いために両手がぼやけていることがエラー原因だと述べている。
しかしながら、総合的には非常に高い精度でセグメンテーションを生成しており、大きな動き、オクルージョン、ボケ、類似オブジェクトなどの困難な状況下でも良質なセグメントを実証している。