オックスフォード大学の研究チームが開発した 「Unsupervised Learning of Probably Symmetric Deformable 3D Objects from Images in the Wild」[Wu et al. 2020]は、いかなる事前情報なしに、単眼カメラによる静止画から3次元形状を復元する教師なし学習モデルだ。主に、人の顔、猫の顔の再構築を実証した。

多視点画像からの3次元形状復元
これまでにも2次元画像を3次元画像に再構築する手法は、複数研究されてきたが、そのほとんどが異なる視点の複数画像や、3次元の事前情報を必要としてきた。
代表的なところでいうと、異なる視点の複数画像を入力として、対象物の3次元画像を復元するStructure from Motion (SfM)がある。 複数の画像間における特徴点の対応関係を算出することで実行する手法だ。
SfMを用いた研究として、例えば「C3DPO」[Novotny et al. 2019] がある。複数の2次元キーポイントから、カメラ視点、物体姿勢、基準となる形状を求め、3次元形状を復元する。
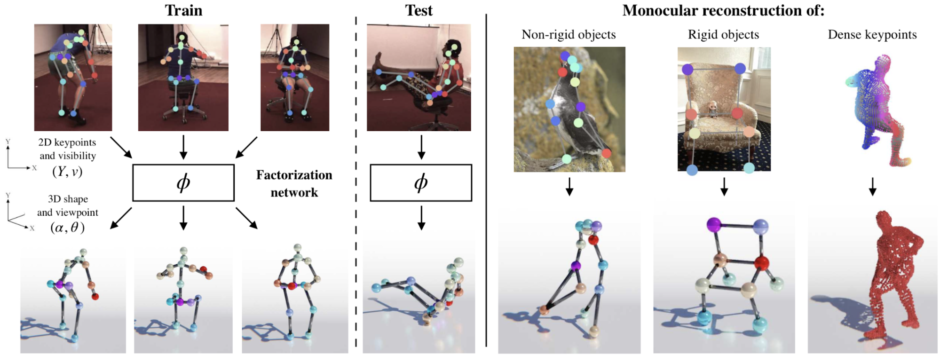
こういったSfMを用いた方法は他にもあるが、どちらにせよ複数枚の画像が必要になるため、1枚の画像から3次元形状を推定することはできない欠点をもっている。
1枚の画像から3次元形状を復元
単眼カメラで撮影した1枚のRGB画像を入力に、GAN(Genera tive Adversarial Network)を用いて人体の3次元メッシュを復元した研究も出てきている。例えば、「End-to-end recovery of human shape and pose」[Kanazawa et al. 2018] がある。

顔の2次元画像から顔の3次元形状とテクスチャを復元する手法では、「GANFIT」[Gecer et al. 2019] がある。UV空間上へのテクスチャマッピングにGANを用いている。

しかしながら、これらは1枚の画像から復元することはできるものの、人体モデルの「SMPL」や、フェイスモデルの「Basel」のような事前に定義された形状モデルから再構成を行う必要がある。事前モデルに依存するため、詳細な部分で限界がある。
本手法
今回紹介する手法は、定義された3次元形状モデル、2D/3Dキーポイント、セグメンテーション、深度マップ、多視点画像、その他ラベル付きデータなどの事前知識を必要とせず、1枚の画像から3次元モデルを復元するための学習ベースのモデルを提案する。
顔は左右対称と仮定し学習に活用
このモデルの特徴は、入力画像の物体は「対称性」(左右対称)が備わっていると仮定している点にある。この前提を利用して行うことで、深度やアルベドのみを反転させても同じになるという制約で学習ができる。
しかし、画像内の物体がきっちり左右対称になっていることはなく、顔画像だと髪の毛が左右で違っていたりと、左右対称の制約は非常に厳しいものがある。そのため、 各ピクセルが対称性を持つかどうかを予測した信頼度マップを作成することで、物体の左右対称の信頼度を推定している。この推定を損失関数に利用することで、左右対称でない領域も考慮に入れた計算が行える。
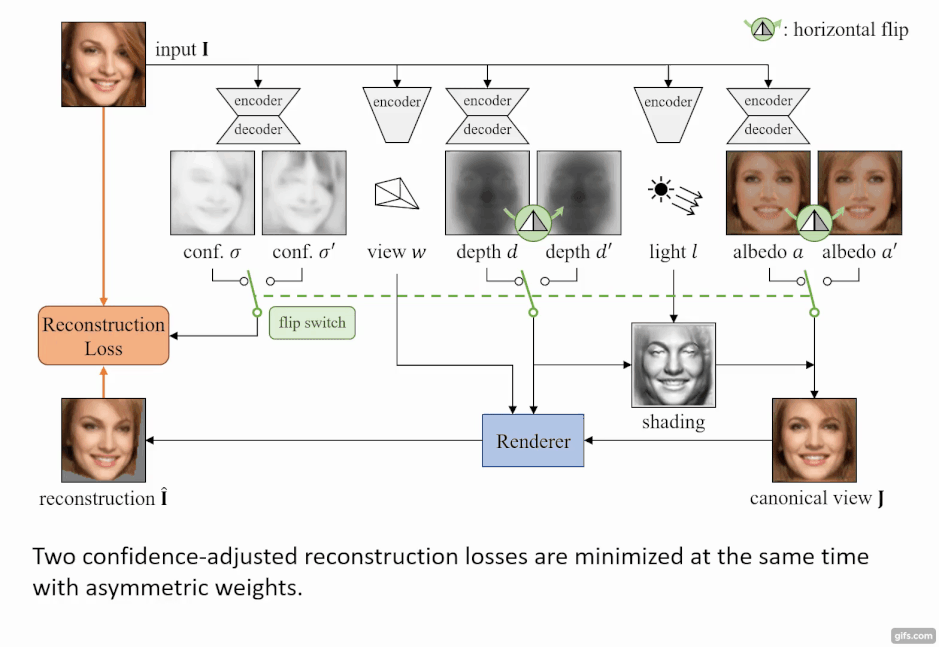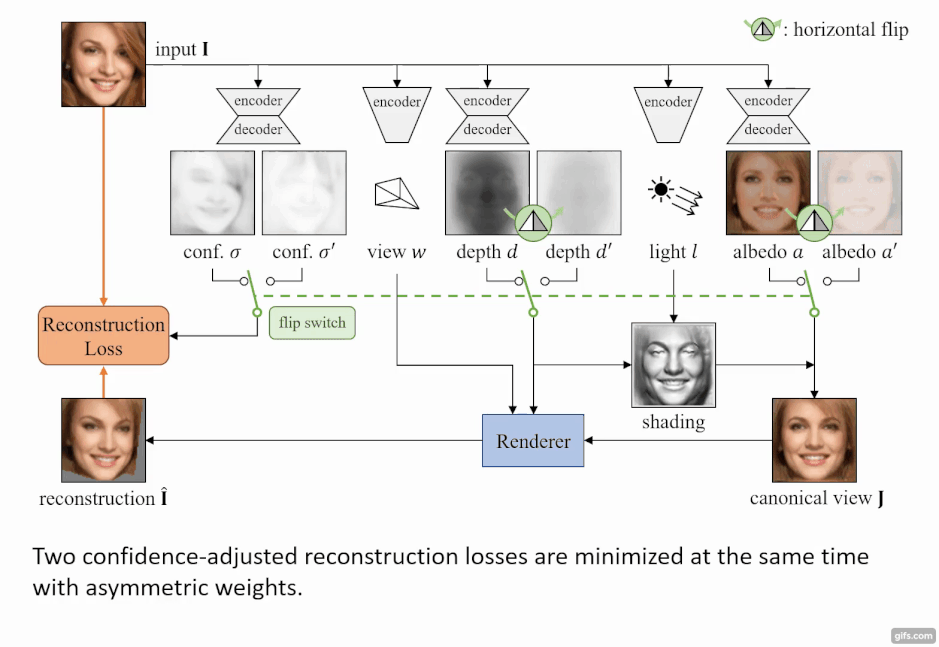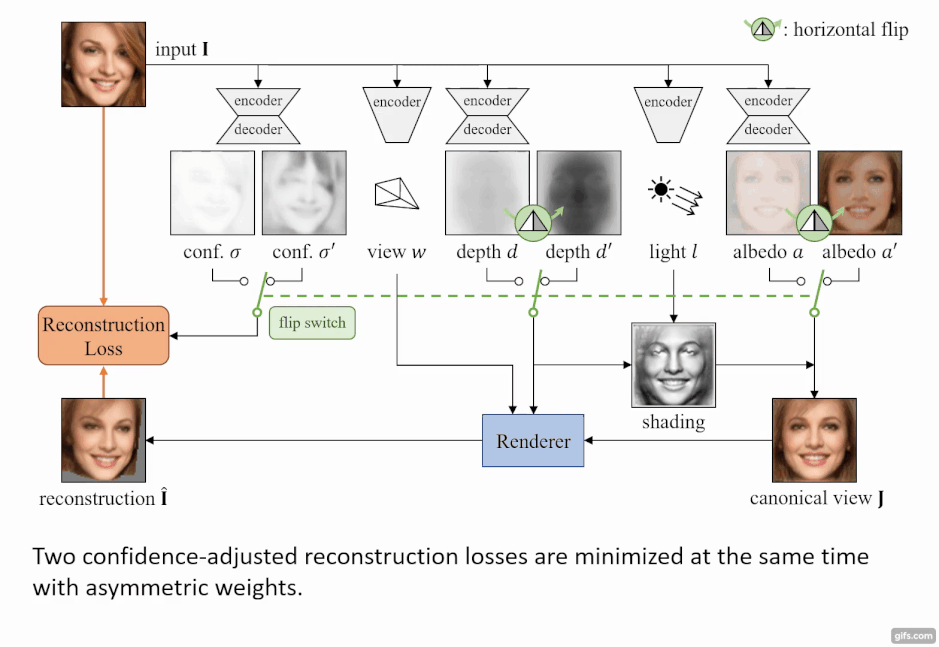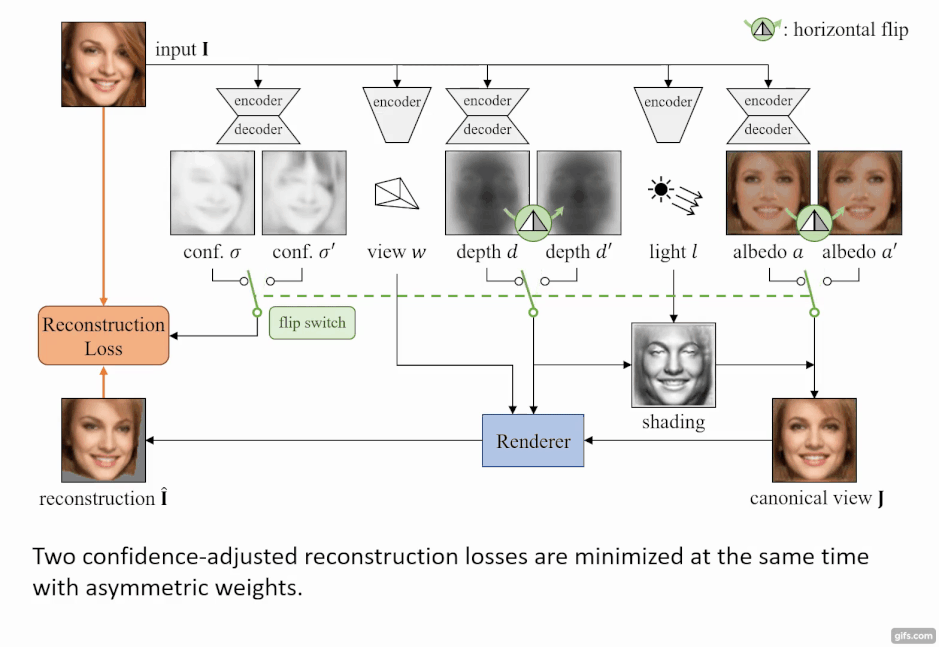
モデルはまず、入力画像からAutoEncoderベースのネットワークを用いて、深度、アルベド、視点、照明の4つに分解する。分解した4つの要素から、「微分可能レンダラー」 を使用し2次元画像を出力する。
微分可能レンダラーとは
ここでいう「微分可能レンダラー」とは、入力画像で予測した3次元構造からレンダリングした2次元画像と入力画像との差分を計算し、 ネットワーク全体を学習することで2D画像から3D情報への変換の精度を向上させる手法を指す。「Neural 3D Mesh Renderer」[Kato et al. 2018]にて公表された。
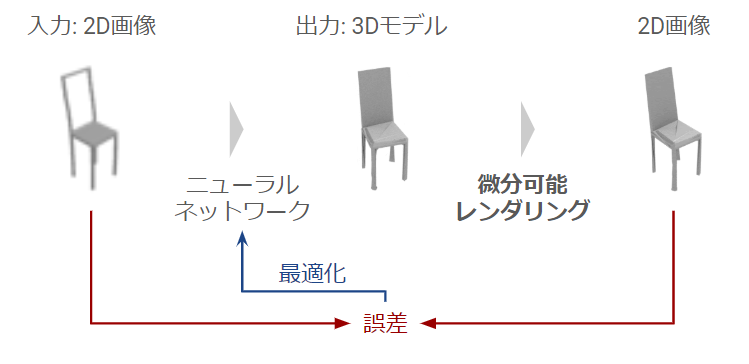
今回は、顔画像の集合だけから3次元形状、色、視点、照明を学習し、推定結果をレンダリングして元画像と見比べる枠組みで微分可能レンダリングを使用している。 微分可能レンダラーは、3次元形状などの教師データが手に入らない場合に効果的に使えるため、さまざまな物体カテゴリにも適応可能だ。
出力結果
学習したモデルは、追加の事前情報なしにRGB画像のみから3次元形状を復元することに成功した。実験では、人の顔、猫の顔、絵画の顔、アニメキャラクターの顔、車で試された。
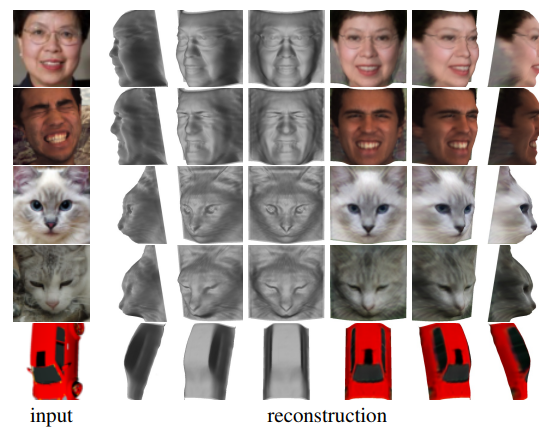



プロジェクトページでは、ブラウザ上でライブデモを試すことができる。