スコットランドのエジンバラ大学とElectronic Artsの研究チームが開発した「Local Motion Phases for Learning Multi-Contact Character Movements」[Starke et al. 2020] は、ゲーム内で使用する高速で動く2足歩行キャラクターにおけるリアルタイム制御を学習するための新しい深層学習フレームワークだ。

3Dキャラクターの操作において、素早い動きをした場合、地面から足が離れたり、ぎこちない動きになったりと、不自然な動作に悩まされる。 また他のキャラクターとの相互作用の場合はとりわけ困難だ。今回の提案では、1対1のバスケットボール環境を例に挙げ、フレームワークを評価し、この課題に挑戦する。

AI4Animation
エジンバラ大学では、数年前から、AI4Animationと呼ぶ研究プロジェクトとして、リアルタイムのキャラクター制御のための深層学習フレームワークの可能性を探っている。
その中から、これまでのキャラクター制御フレームワーク(1)2足歩行のリアルタイム制御、(2)4足歩行のリアルタイム制御、(3)キャラクターと物体との相互作用、そして今回のフレームワーク(4)キャラクターと他のキャラクターとの相互作用の合計4本を紹介する。
#1:Phase-Functioned Neural Networks for Character Control
最初に紹介するのが、2足歩行キャラクターのリアルタイム制御において、高速かつメモリの利用量が少ないことを目標にした深層学習モデル。人間の動きであるモーションキャプチャを教師データとして学習し、次の動きであるフレームを推定する。
ガタガタの地形でも対応しており、小山を登り、降りて、飛び越え、階段も足が地面から離れることなく自然に上り下りする。
学習で使用されるPhase-Functioned Neural Network(PFNN)と呼ぶネットワークは、通常だと各層のパラメータが学習後に固定されるのに対して、 時間位相によって定期的に変動させている。そのため、精度の高い歩行を実現している。
Paper: Phase-Functioned Neural Networks for Character Control [Holden et al. 2017]
#2:Mode-Adaptive Neural Networks for Quadruped Motion Control
次は、4足歩行キャラクターのリアルタイム制御を深層学習で計算するモデル。2足歩行に比べ、複数の歩き方、走り方があるのが特徴。そのため、 複数の歩行モードを効率的に学習するモデルが必要。
それを踏まえて、 キャラクターの現在の姿勢と速度、ユーザーからの制御信号を参考に、次に動くフレームでの姿勢と速度を推定するように学習する。 コマンドには移動速度、座る、歩く、ジャンプといったモーションが含まれる。
モデルは、モーション生成のMotion Prediction Network、その重み調整のGating NetworkからなるMode-Adaptive Neural Networks (MANN)と呼ぶアーキテクチャを手掛ける。 データセットは、速度と動作方法に手作業でラベル付けした犬のモーションキャプチャデータを使用。
実験では、27本の骨格モデルによる81自由度を持った犬を構築し、Unityのフレームワーク上で組まれたプログラムにより実行する。 結果、平地において、自然かつ滑らかに動き回ることに成功した。
Paper: Mode-Adaptive Neural Networks for Quadruped Motion Control [Zhang et al. 2018]
#3:Neural State Machine for Character-Scene Interactions
続いては、リアルタイムのキャラクター制御において、キャラクターとさまざまな物体との相互作用に焦点を当てた深層学習モデルをご紹介。 椅子に向かって歩いて座る、部屋から出る前にドアを開ける、机の上や下から箱を運ぶ など、様々なシーンでのインタラクションタスクを正確かつ滑らかに行うよう学習するためのフレームワーク。
Neural State Machineと呼ばれるフレームワークは、従来のシステムでは推定時に誤差が蓄積されてしまうアクション付近を欠点とし、キャラクター視点からの推定と、アクションを行う物体からのゴール視点からの推定が合成される双方向のスキームを提案する。
学習したモデルは、歩行動作から自然に箱を持ち上げ移動させる、位置がずれる事なく椅子に座る、など安定して物体との相互作用を出力する。
Paper: Neural State Machine for Character-Scene Interactions [Starke et al. 2019]
本手法 #4:Local Motion Phases for Learning Multi-Contact Character Movements
最後に、リアルタイムのキャラクター制御において、 他のキャラクターとの相互作用に焦点を当てた深層学習モデルをご紹介。ユーザの指示から生成された抽象的な制御信号を、全身運動へマッピングし、シャープな制御信号に変換するモデルを提案する。
1対1のバスケットボールのプレーを大規模なデータベースとして利用し、1人のプレイヤーがドリブルして、ゴールを守ろうとする相手プレイヤーを避ける動作を例としている。
プレイ中にオフェンスからディフェンスへの切り替えが容易に行えるように、統一されたフレームワークのもとでリアルなオフェンスとディフェンスのアクションを学習・生成できる制御モデルを設計する。
身体とボールや地面との接触が非同期的に素早く切り替わるような、高速で複雑な相互作用を伴う動きを学習させるために、Local Motion Phaseと呼ばれる特徴量を提案している。この特徴量は、モーションキャプチャデータから、身体全体の動きを揃えることなく、局所的に個々の身体部位の動きを学習する。
モデルは、局所的な運動位相を入力に重みを計算し、滑らかな位相軌跡を求める「Gating network」と、あるフレームから次のフレームへの全体の動きを予測するための「Motion prediction network」から構成する。学習したモデルは、現在のキャラクターの状態と、ユーザーが与えた制御コマンドから自己回帰的に次の動きを計算する。
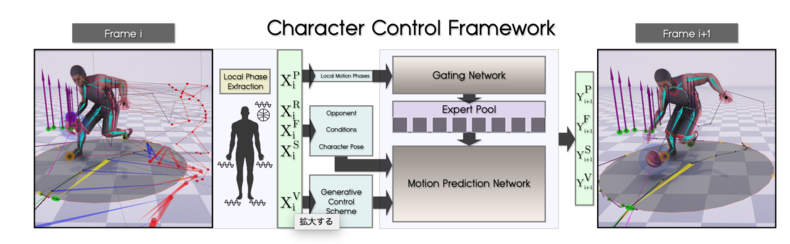
これにより、キャラクターをインタラクティブに制御した操作、ドリブル、フェイント、スティール、ディフェンスなどの高速で非同期な動きをリアルタイムに作り出す。既存手法と比較すると、如実に滑らかさの違いを確認できる。
また、今回のアプローチで採用された局所的な運動位相は、全身運動から自動的に抽出することができ、高品質な運動を生成するための特徴量として機能することを実証した。